







文章目录
前言
前面我们已经了解到协程的基本概念以及对称协程和非对称协程的定义,本节将对如何用c语言在用户态实现协程切换作以简单介绍。
一、c语言中协程切换方式
c/c++在C++20标准之前并不支持协程,所以很多大佬都通过自己的方法实现了协程切换,主要分类如下:
1.使用setjmp 和 longjmp实现。
2.使用switch-case等技巧实现。
3.使用ucontext实现。
4.使用汇编语言实现。
下面将逐条进行简要的分析。
二、使用setjmp 和 longjmp实现协程切换
1.setjmp和longjmp函数简介
setjmp和longjmp是C99标准中<setjmp.h>文件里定义的两个函数,定义如下:
int setjmp(jmp_buf env);
void longjmp(jmp_buf env, int val);
/*setjmp() and longjmp(3) are useful for dealing with errors and interrupts encountered in a low-level subroutine of a program.
setjmp() saves the stack context/environment in env for later use by longjmp(3). The stack context will be invalidated if the function which called setjmp() returns.
longjmp() restores the environment saved by the last call of setjmp(3) with the corresponding env argument. After longjmp() is completed, program execution continues as if the corresponding call of setjmp(3) had just returned the value val. longjmp() cannot cause 0 to be returned. If longjmp() is invoked with a second argument of 0, 1 will be returned instead.*/
简单翻译一下两个函数的用途:
a.setjmp函数是将把执行这个函数时的各种上下文信息保存起来,保存在参数env中,当初次调用这个函数保存上下文时,返回值是0。当是通过longjmp函数跳转到setjmp函数时,由于之前已经保存上下文环境了,便不会保存,并且返回值是longjmp函数的第二个参数val(保证非0,val是0时会返回1)。
b.longjmp函数负责跳转到参数 env 中保存的上下文中去执行setjmp函数,并且返回值是longjmp的第二个参数val。
这两个函数中提及的上下文信息,其实就是程序在对应位置时的一些寄存器的取值,常见的寄存器有程序计数器PC,用来保存程序对应的下一条指令的位置。setjmp负责将这些寄存器信息保存到env参数,longjmp跳转时就可以根据保存的env参数重置cpu寄存器的值,从而跳转到指定位置开始执行程序。
2.协程实现
使用setjmp和longjmp简单实现的一个协程切换函数如下所示:
#include<setjmp.h>
#include<stdio.h>
#include<unistd.h>
/* 协程切换时用于保存主协程和子协程的上下文的数据结构 */
typedef struct _context
{
jmp_buf mainBuf;
jmp_buf coBuf;
}Context;
/* 全局对象 */
Context gContext;
/* 子协程恢复函数 */
#define resume() \
do{ \
if(0==setjmp(gContext.mainBuf)) \
{ \
longjmp(gContext.coBuf,1); \
} \
} while (0)
/* 子协程挂起函数 */
#define yield() \
do {\
if(0==setjmp(gContext.coBuf)) \
{ \
longjmp(gContext.mainBuf,1); \
} \
} while(0)
/* 函数指针 */
typedef void (*pf)(void *);
/* 子协程启动函数 */
void startCoroutine(pf func,void *arg)
{
if(0==setjmp(gContext.mainBuf))
{
/* 首次调用setjmp时,返回值为0,开始执行子协程对应函数 */
func(arg);
}
/* longjmp跳转到setjmp时,返回非0,所以直接结束协程启动函数 */
}
/* 子协程执行函数 */
void coroutine_func(void *arg)
{
while(true)
{
/* 循环打印@符号,为了一次显示一个@,将fprintf输出到不带缓冲的stderr */
printf("\n *****coroutine is working******\n");
for(int i=0;i<30;++i)
{
fprintf(stderr,"@");
usleep(1000*100);
}
printf("\n *****coroutine is suspending******\n");
yield();
}
}
int main(int argc,void *argv)
{
/* 启动子协程 */
startCoroutine(coroutine_func,NULL);
/* 主协程循环 */
while(true)
{
printf("\n *****main is working******\n");
for(int i=0;i<30;++i)
{
fprintf(stderr,"#");
usleep(1000*100);
}
printf("\n *****main is suspending******\n");
resume();
}
return 0;
}
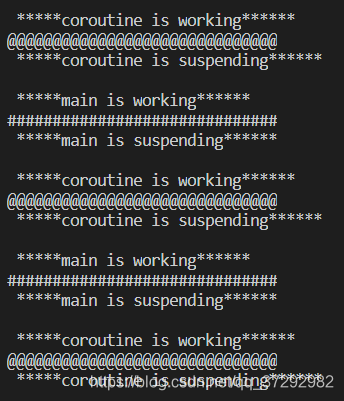
结合注释可以很容易理解代码,主要是主协程和子协程分别执行自己的打印任务,通过setjmp和longjmp完成协程的切换。执行结果如下所示:
三、使用switch-case实现协程切换
1.switch-case小技巧
switch-case语句是c中常见的语法,现在介绍一个比较小众的用法:达夫设备。先看一个函数示例:
int copy(int *dest, int *src, int n)
{
for (int i = 0; i < n; ++i)
{
*dest++ = *src++;
}
}
可以看出copy函数主要实现了将一个地址为src的int数组中的元素拷贝n个到dest地址。其中for循环中比较次数和拷贝次数均为n次,拷贝次数不可避免,那么能不能想办法减少比较次数呢?
带着这个问题我们先看一下下面一段代码:
int main()
{
int n;
cin >> n;
switch (n%4)
{
do
{
case 0:cout << 0 << endl;
case 1:cout << 1 << endl;
case 2:cout << 2 << endl;
case 3:cout << 3 << endl;
} while (--n > 0);
}
return 0;
}
当输入n=0,1,2,3时,输出如下所示:
| 0 | 0,1,2,3 |
|---|---|
| 1 | 1,2,3 |
| 2 | 2,3,0,1,2,3 |
| 3 | 3,0,1,2,3,0,1,2,3 |
结合输出可知swich(n%4)的作用时根据n定位到do-while中的某一个case语句,如n=2时会定位到case 2。此时,**switch-case已经完成了它的作用,**然后,程序从case语句开始执行,直到while处进行条件判断,若–n>0,则会继续执行do-while循环,所有的case均已无用。
学习了这个用法以后,我们来看一下最开始的问题的答案,代码如下:
void send( int * to, int * from, int n)
{
int count = (n+7) / 8 ;
switch (n%8) {
case 0 : do { * to ++ = * from ++ ;
case 7 : * to ++ = * from ++ ;
case 6 : * to ++ = * from ++ ;
case 5 : * to ++ = * from ++ ;
case 4 : * to ++ = * from ++ ;
case 3 : * to ++ = * from ++ ;
case 2 : * to ++ = * from ++ ;
case 1 : * to ++ = * from ++ ;
} while (--count>0);
}
}
可以看出相比原来比较n次,现在只需要count次,比较次数变为了原来的八分之一,这段代码就叫Duff’s Device。象这样的把 case 标志放在嵌套在 swtich 语句内的模块中是合法的
2.协程实现
学习了上面的小技巧以后,我们来思考一下,如何使用这个技巧来实现协程。所谓协程,无非是程序在执行到某一行时保存一下上下文暂时挂起去执行其它任务,恢复时继续从上下文执行。对于“保存现场-暂停-恢复继续执行”这个要求,我们可以采取如下思路执行:
int function() {
static int i, state = 0;
switch (state) {
case 0: /* start of function */
for (i = 0; i < 10; i++) {
state = __LINE__ + 2; /* so we will come back to "case __LINE__" */
return i;
case __LINE__:; /* resume control straight after the return */
}
}
}
其中__LINE__ 是内置宏,代表该行代码的所在行号。这样当调用function函数时,它会依次返回0,1,2,3,4,5,6,7,8,9。每次到return i时函数返回,下一次执行时根据switch继续跳转到case LINE:执行,完成了类似的效果。
当然了使用switch-case来实现协程远比上述代码复杂,详细实现大家可以看一下这一篇文章:一个“蝇量级” C 语言协程库。
四、使用ucontext实现协程切换
1.ucontext相关函数简介
在system-v环境中<ucontext.h>文件中定义了的这些函数:getcontext(), setcontext(), makecontext()和swapcontext()。利用它们可以在一个进程中实现用户级的线程切换,下面先学习一下这些函数。
在介绍函数之前,先学习一个ucontext_t类型的结构体,它表示协程的上下文环境:
typedef struct ucontext {
struct ucontext *uc_link;
sigset_t uc_sigmask;
stack_t uc_stack;
mcontext_t uc_mcontext;
...
} ucontext_t;
当前协程暂停时,系统会切换到uc_link对应上下文环境,完成协程切换。uc_sigmask为上下文中的阻塞信号集合;uc_stack为上下文中使用的栈;uc_mcontext保存的上下文的特定机器表示,包括调用线程的特定寄存器等。
下面学习一下相关函数:
int getcontext(ucontext_t *ucp);
int swapcontext(ucontext_t *oucp, ucontext_t *ucp);
void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...);
int setcontext(const ucontext_t *ucp);
getcontext负责初始化ucp结构体,将当前的上下文保存到ucp中。
swapcontext负责保存当前上下文到oucp结构体中,然后激活upc上下文。
makecontext修改通过getcontext取得的上下文ucp(这意味着调用makecontext前必须先调用getcontext),这样当makecontext修改以后的ucp被激活以后,就会转向执行func函数,argc代表func的参数个数,后面的…代表可变参数。需要注意的是,在getcontext调用之后,makecontext调用之前,首先要给该上下文指定一个栈空间ucp->stack,设置后继的上下文ucp->uc_link。这样func函数返回以后程序就会转到ucp->uc_link指向的上下文中继续执行。如果uc_link为NULL,则线程退出。
setcontext负责设置当前的上下文为ucp,setcontext的上下文ucp应该通过getcontext或者makecontext取得,如果调用成功则不返回。如果上下文是通过调用getcontext()取得,程序会继续执行这个调用。如果上下文是通过调用makecontext修改,程序会调用makecontext函数的第二个参数指向的函数,如果func函数返回,则恢复makecontext第一个参数指向的上下文第一个参数指向的上下文context_t中指向的uc_link.如果uc_link为NULL,则线程退出。
总结一下,getcontext获取当前上下文,setcontext设置当前上下文,swapcontext切换上下文,makecontext创建一个新的上下文。
2.协程实现
学习了前面的四个函数以后,通过一个简单例子看一下协程实现:
#include<ucontext.h>
#include<stdio.h>
#include<unistd.h>
/* 子协程执行函数 */
void coroutine_func()
{
/* 循环打印@符号,为了一次显示一个@,将fprintf输出到不带缓冲的stderr */
printf("\n *****coroutine is working******\n");
for(int i=0;i<30;++i)
{
fprintf(stderr,"@");
usleep(1000*100);
}
printf("\n *****coroutine is suspending******\n");
}
/* 子协程测试函数 */
void coroutine_test()
{
char stack[1024*200];
ucontext_t coro,main;
getcontext(&coro);
//设置上下文栈
coro.uc_stack.ss_sp=stack;
coro.uc_stack.ss_size=sizeof(stack);
coro.uc_stack.ss_flags=0;
coro.uc_link=&main;
makecontext(&coro,coroutine_func,0);
swapcontext(&main,&coro); //切换协程
}
int main(int argc,void *argv)
{
printf("\n *****main is working******\n");
for(int i=0;i<30;++i)
{
fprintf(stderr,"#");
usleep(1000*100);
}
printf("\n *****main is suspending******\n");
coroutine_test();
printf("\n *****main is working******\n");
for(int i=0;i<30;++i)
{
fprintf(stderr,"#");
usleep(1000*100);
}
printf("\n *****main is suspending******\n");
return 0;
}
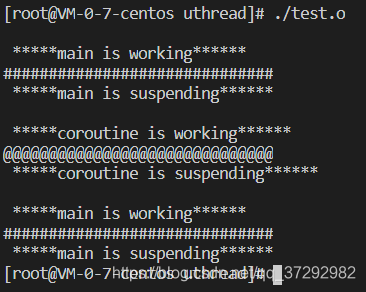
结合注释和上面的函数注释很容易看懂代码,执行结果如下所示:
五、使用汇编语言实现协程切换
1.X86-64CPU寄存器简介
X86-64cpu的寄存器如下所示:
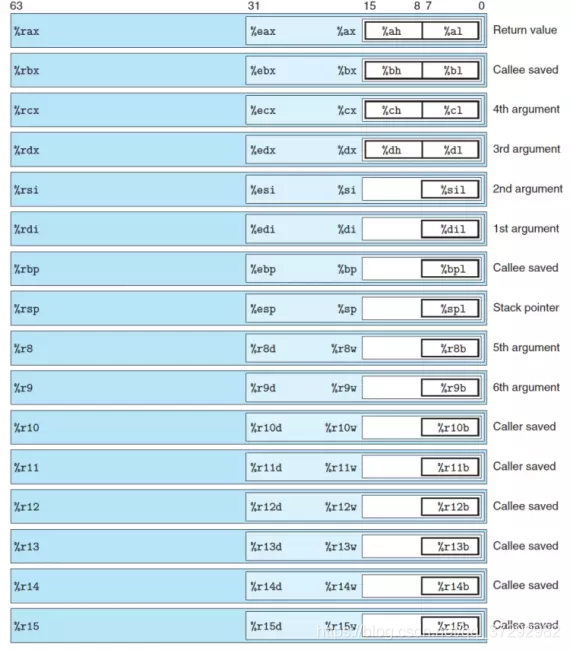
当执行程序时,cpu的寄存器就会保存函数的相关信息。其中寄存器**%rax保存函数返回值,%rdi保存函数第一个参数,%rsi保存函数第二个参数,%rsp保存栈顶指针**。
2.协程实现
当协程切换时需要保存当前协程的上下文信息,切换到另一个协程的上下文进行执行,而这些上下文信息主要就是寄存器的值。通过汇编语言实现的协程代表是腾讯微信的libco协程库,下面结合libco简要分析如何通过汇编语言实现协程切换。
libco中协程切换函数如下所示:
// 64 bit
extern "C" {
extern void coctx_swap(coctx_t*, coctx_t*) asm("coctx_swap");
};
其中coctx_t类型表示协程的上下文信息,定义如下:
struct coctx_t
{
#if defined(__i386__)
void *regs[ 8 ];
#else
// 协程的14个寄存器
void *regs[ 14 ];
#endif
//协程的栈定义
size_t ss_size;
char *ss_sp;
};
通过汇编语言实现的coctx_swap函数如下所示:
.globl coctx_swap
#if !defined( __APPLE__ ) && !defined( __FreeBSD__ )
.type coctx_swap, @function
#endif
coctx_swap:
#if defined(__i386__)
.....
#elif defined(__x86_64__)
leaq 8(%rsp),%rax
leaq 112(%rdi),%rsp
pushq %rax
pushq %rbx
pushq %rcx
pushq %rdx
pushq -8(%rax) //ret func addr
pushq %rsi
pushq %rdi
pushq %rbp
pushq %r8
pushq %r9
pushq %r12
pushq %r13
pushq %r14
pushq %r15
movq %rsi, %rsp
popq %r15
popq %r14
popq %r13
popq %r12
popq %r9
popq %r8
popq %rbp
popq %rdi
popq %rsi
popq %rax //ret func addr
popq %rdx
popq %rcx
popq %rbx
popq %rsp
pushq %rax
xorl %eax, %eax
ret
#endif
leaq 用于把其第一个参数的值赋值给第二个寄存器参数。第一条语句用来把 8(%rsp) 的本身的值存入到 %rax 中,注意这里使用的并不是 8(%rsp) 指向的值,而是把 8(%rsp) 表示的地址赋值给了 %rax。这一地址是父函数栈帧中除返回地址外栈帧顶的位置。
在第二条语句leaq 112(%rdi), %rsp中,%rdi 存放的是coctx_swap第一个参数的值,这一参数是指向 coctx_t 类型的指针,表示当前要切出的协程的上下文。而 112(%rdi) 表示的就是第一个协程的 coctx_t 中 regs[14] 数组的下一个64位地址。这一条语句的目的是将coctx_t 中的regs数组作为栈,以便后续指令将寄存器值压入栈(regs数组)中。
pushq %rax
pushq %rbx
pushq %rcx
pushq %rdx
pushq -8(%rax) //ret func addr
pushq %rsi
pushq %rdi
pushq %rbp
pushq %r8
pushq %r9
pushq %r12
pushq %r13
pushq %r14
pushq %r15
上面的第一条语句 pushq %rax 用于把 %rax 的值放入到 regs[13] 中,resg[13] 用来存储第一个协程的 %rsp 的值。这时 %rax 中的值是第一个协程 coctx_swap 父函数栈帧除返回地址外栈帧顶的地址。由于 regs[] 中有单独的元素存储返回地址,栈中再保存返回地址是无意义的,因而把父栈帧中除返回地址外的栈帧顶作为要保存的 %rsp 值是合理的。当协程恢复时,把保存的 regs[13] 的值赋值给 %rsp 即可恢复本协程 coctx_swap 父函数堆栈指针的位置。第一条语句之后的语句就是用pushq 把各CPU 寄存器的值依次从 regs 尾部向前压入。regs[14] 数组中各元素与其要存储的寄存器对应关系如下:
//-------------
// 64 bit
//low | regs[0]: r15 |
// | regs[1]: r14 |
// | regs[2]: r13 |
// | regs[3]: r12 |
// | regs[4]: r9 |
// | regs[5]: r8 |
// | regs[6]: rbp |
// | regs[7]: rdi |
// | regs[8]: rsi |
// | regs[9]: ret | //ret func addr, 对应 rax
// | regs[10]: rdx |
// | regs[11]: rcx |
// | regs[12]: rbx |
//hig | regs[13]: rsp |
这里用的方法还是通过改变%rsp 的值,把第二个参数%rsi当作栈来使用,然后通过汇编指令将栈中数据弹出保存到寄存器中。
movq %rsi, %rsp
popq %r15
popq %r14
popq %r13
popq %r12
popq %r9
popq %r8
popq %rbp
popq %rdi
popq %rsi
popq %rax //ret func addr
popq %rdx
popq %rcx
popq %rbx
popq %rsp
第一句 movq %rsi, %rsp 就是让%rsp 指向 coctx_swap 第二个参数,这一参数表示要进入的协程上下文。执行完 movq 语句后,%rsp 指向了第二个参数 coctx_t 中 regs[0],而之后的pop 语句就是用 regs[0-13] 中的值填充cpu 的寄存器,这里需要注意的是popq 会使得 %rsp 的值增加而不是减少,这一点保证了会从 regs[0] 到regs[13] 依次弹出到 cpu 寄存器中。在执行完最后一句 popq %rsp 后,%rsp 已经指向了新协程要恢复的栈指针(即新协程之前调用 coctx_swap 时父函数的栈帧顶指针),由于每个协程都有一个自己的栈空间,可以认为这一语句使得%rsp 指向了要进入协程的栈空间。
pushq %rax
xorl %eax, %eax
ret
pushq %rax 用来把**%rax 的值压入到新协程的栈中**,这时 %rax 是要进入的目标协程的返回地址,即要恢复的执行点。然后用 xorl 把 %rax 低32位清0以实现地址对齐。最后ret 语句用来弹出栈的内容,并跳转到弹出的内容表示的地址处,而弹出的内容正好是上面 pushq %rax 时压入的 %rax 的值,即之前保存的此协程的返回地址。即最后这三条语句实现了转移到新协程返回地址处执行,从而完成了两个协程的切换。
总结
本文对协程的切换方式进行了简要介绍,如有不当,请指正。















 1285
1285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









