






 本文介绍了如何通过自定义Mybatis基类,重写`getResources()`方法,实现统一的SQL操作,解决批量插入时自增id的问题,并比较了jdbc批量提交与Mybatisforeach的性能。作者还展示了如何使用`SqlSession`进行批量插入并返回id,以及性能测试的结果。
本文介绍了如何通过自定义Mybatis基类,重写`getResources()`方法,实现统一的SQL操作,解决批量插入时自增id的问题,并比较了jdbc批量提交与Mybatisforeach的性能。作者还展示了如何使用`SqlSession`进行批量插入并返回id,以及性能测试的结果。
因为之前研究出了mybatis基类统一查询、修改等操作的实现方式,有兴趣的小伙伴可以看看
然后在封装统一的 batchInsertSelective方法,sql写法如下:
TestMapper.java
public interface TestMapper {
int foreachInsertSelective(@Param("list") List<Test> entityList);
}TestMapper.xml
<insert id="foreachInsertSelective">
<foreach collection="list" separator=";" close="" index="index" item="item" open="">
INSERT INTO
test
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="item.id != null">id,</if>
<if test="item.content != null">content,</if>
<if test="item.puid != null">puid,</if>
</trim>
<trim prefix="VALUES (" suffix=")" suffixOverrides=",">
<if test="item.id != null">#{item.id},</if>
<if test="item.content != null">#{item.content},</if>
<if test="item.puid != null">#{item.puid},</if>
</trim>
</foreach>
</insert>因为忽略null值插入,然后插入的对象可能各自的不同字段。
比如:[{"content":"test"},{"puid":100}]。所以采用xml<foreach>标签进行循环插入。
那么就发现有个需求无法满足。
如果这个表的id是自增的,那么通过<foreach>循环插入的方法无法回填id!
看一下下面的实验:
TestMapper.java
public interface TestMapper {
int foreachInsertSelective(@Param("list") List<Test> entityList);
}TestMapper.xml
<insert id="foreachInsertSelective" useGeneratedKeys="true" keyProperty="id">
<foreach collection="list" separator=";" close="" index="index" item="item" open="">
INSERT INTO
test
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="item.id != null">id,</if>
<if test="item.content != null">content,</if>
<if test="item.puid != null">puid,</if>
</trim>
<trim prefix="VALUES (" suffix=")" suffixOverrides=",">
<if test="item.id != null">#{item.id},</if>
<if test="item.content != null">#{item.content},</if>
<if test="item.puid != null">#{item.puid},</if>
</trim>
</foreach>
</insert>test结果:

可以看到只返回的第一个id,其他的19个id并没有帮我们回写回去。
为什么会出现这种情况?
通过翻阅mybatis的源码。
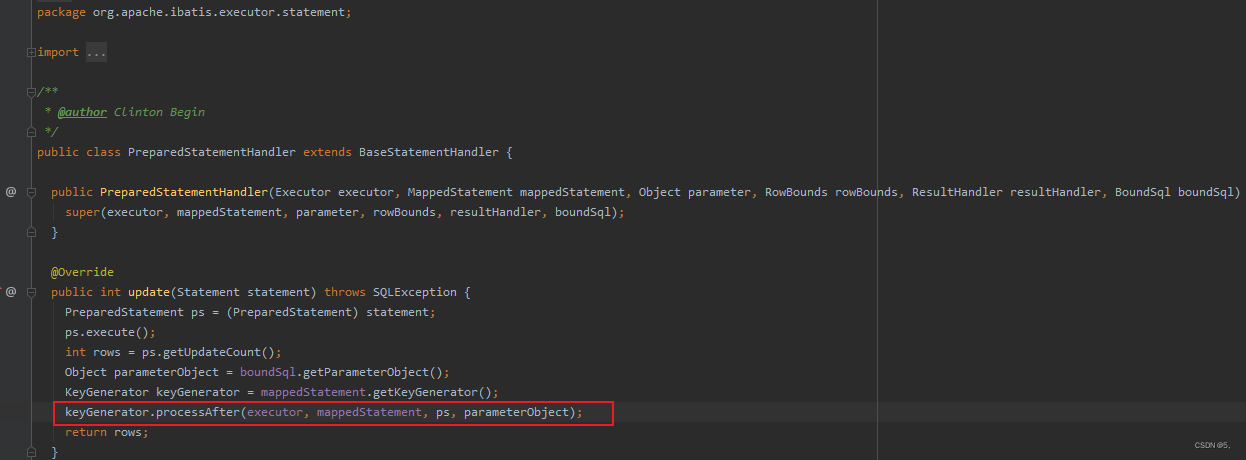
正如网上的传说,新版一点的mybatis使用的默认keyGenerator是Jdbc3KeyGenerator。那我们再接着在这里面找。


重头戏来了:

可以发现,这里发现,jdbc返回的ResultSet只有一个,并没有返回全部的id字段。那么这也怪不了mybatis了。
思考:
那么如何即实现batchInsertSelective,又能让自增表使用batchInsertSelective方法时返回id呢?
这时候我脑子一抽,想到了在学校中学习到的,jdbc批量提交!!!
从网上搜索到的批量提交的jdbc代码。
public class Batch {
@Test
public void batch() throws Exception {
Connection connection = JDBCUtils.getConnection();
String sql = "insert into admin values(?,?)";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
long start = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
preparedStatement.setString(1,"jak");
preparedStatement.setString(2,"abc");
//语句添加到批处理包里
preparedStatement.addBatch();
if (((i + 1) % 1000) == 0){
preparedStatement.executeBatch();
//到了装1000条执行后清空
preparedStatement.clearBatch();
}
}
long end = System.currentTimeMillis();
System.out.println("Batch方法执行时间" + (end - start));
JDBCUtils.close(null,connection,preparedStatement);
}
}这代码多么的古老哦。那么现在既然有了mybatis,那就不可能去使用原生的jdbc来再封装一次造轮子。并且mybatis是对jdbc的封装,那么看看它有没有暴露出来对应的功能。
对mybatis的了解,知道mybatis其实最重要的就是sqlSession这玩意。
那我们看一下正常使用mybatis功能时,他是怎么获取sqlSession的。

其实就是通过SqlSessionUtils.getSqlSession方法获取,那么就简单了。看看入参都有些什么:

看代码的方法说明。最主要的是
executorType The executor type of the SqlSession to create。(传入需要创建的执行类型)
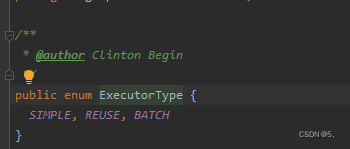
振奋人心,有BATCH的类型,那么说明mybatis其实是支持jdbc批量执行的。
那么接下来上代码
BaseServiceImpl.java
public class BaseServiceImpl<S extends BaseService<T>, M extends IBaseMapper<T>, T extends BaseModel> {
@Autowired
protected M baseMapper;
@Autowired
private SqlSessionTemplate sqlSessionTemplate;
private Class<S> currentServiceClass = getCurrentClass(0);
private Class<M> currentMapperClass = getCurrentClass(1);
private S currentService;
private <Z> Class<Z> getCurrentClass(int index) {
Type genericSuperclass = getClass().getGenericSuperclass();
System.out.println(genericSuperclass);
ParameterizedType parameterizedType = (ParameterizedType) getClass().getGenericSuperclass();
return (Class<Z>) parameterizedType.getActualTypeArguments()[index];
}
@Transactional(propagation = Propagation.REQUIRED, rollbackFor = Exception.class)
public int batchInsertSelective(List<T> entityList) {
setDefault(entityList, true);
AtomicInteger row = new AtomicInteger();
executeBatch(entityList, IBaseMapper::insertSelective);
return row.get();
}
/**
* 批量执行
* 关于为什么弄出来了这个执行方法,
* 一、因为我们公司大部分的表都设置了主键自增,如果插入的时候,用的是mybatis foreach标签进行插入,是不会填充id到实体里面的。
* 这主要是为了insertSelective,insert方法的批量操作设计。
* 二、性能,用executeBatch效率更高,可以看
* @see TestMybatis#test()
* @param entityList
* @param biFunction
* @return 执行成功的条数
*/
private int executeBatch(List<T> entityList, BiFunction<IBaseMapper<T>, T, Integer> biFunction) {
if (entityList.size() == 1) {
return biFunction.apply(baseMapper, entityList.get(0));
}
// 获取sqlSession
SqlSession sqlSession = SqlSessionUtils.getSqlSession(
sqlSessionTemplate.getSqlSessionFactory(),
ExecutorType.BATCH,
sqlSessionTemplate.getPersistenceExceptionTranslator());
IBaseMapper<T> mapper = sqlSession.getMapper(currentMapperClass);
AtomicInteger row = new AtomicInteger();
batchDoSomething(entityList, list -> {
for (T t : list) {
row.addAndGet(biFunction.apply(mapper, t));
}
sqlSession.flushStatements();
});
return row.get();
}
}最主要的关注方法是:executeBatch
BaseMapper.xml
<insert id="insertSelective" useGeneratedKeys="true" keyProperty="id">
INSERT INTO
test
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="item.id != null">id,</if>
<if test="item.content != null">content,</if>
<if test="item.puid != null">puid,</if>
</trim>
<trim prefix="VALUES (" suffix=")" suffixOverrides=",">
<if test="item.id != null">#{item.id},</if>
<if test="item.content != null">#{item.content},</if>
<if test="item.puid != null">#{item.puid},</if>
</trim>
</insert>ok,附上测试结果:

并且做了一下性能的测试。发现使用jdbc批量提交比在xml中用<foreach>标签批量提交的效率是要高许多的。并且返回了对应的id。对于批量提交并且回写id的源码我并没有去深究,有兴趣的小伙伴可以尝试去看看
结束。















 4336
4336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









