






spring版本:5.2.24.RELEASE
首先sql语句:
CREATE TABLE test_jdbc (
id BIGINT auto_increment NOT NULL,
is_add_1688 varchar(100) NULL,
is_1688 varchar(100) NULL,
normal_text varchar(100) NULL,
CONSTRAINT test_jdbc_PK PRIMARY KEY (id)
)
ENGINE=InnoDB;
INSERT INTO myj_amzup.test_jdbc
(is_add_1688, is_1688, id, normal_text)
VALUES('bind', 'noBind', 1, 'haha');
对应的ddl的实体:
@Data
public static class TestJdbc {
private Long id;
private String isAdd1688;
private String is1688;
private String normalText;
}查询代码:
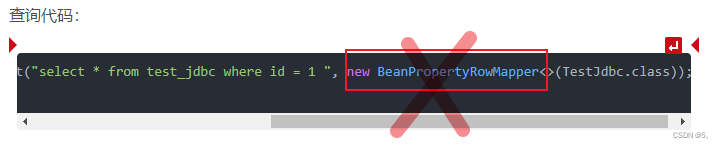
TestJdbc jdbc = getJdbcTemplate(100).queryForObject("select * from test_jdbc where id = 1 ", new BeanPropertyRowMapper<>(TestJdbc.class));
查看结果:
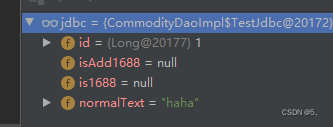
数据库数据:

为什么isAdd1688和is1688映射不上?
追踪一下源码
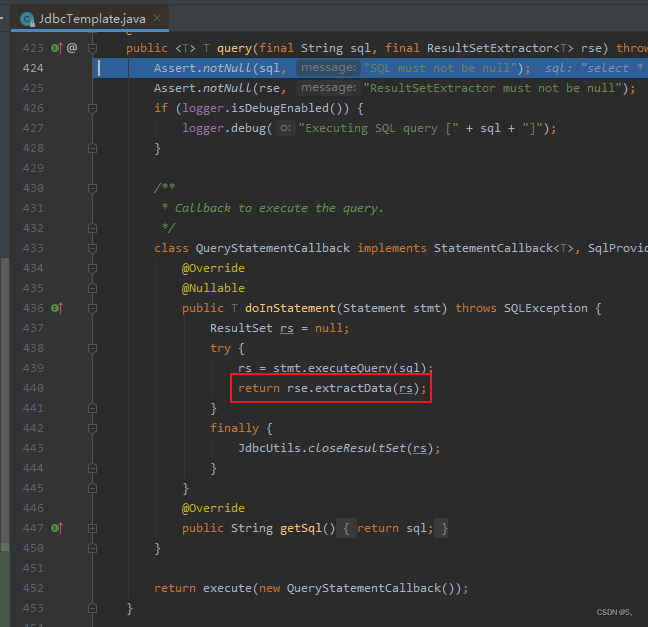
发现是在这里进行映射的,再深入追踪一下。
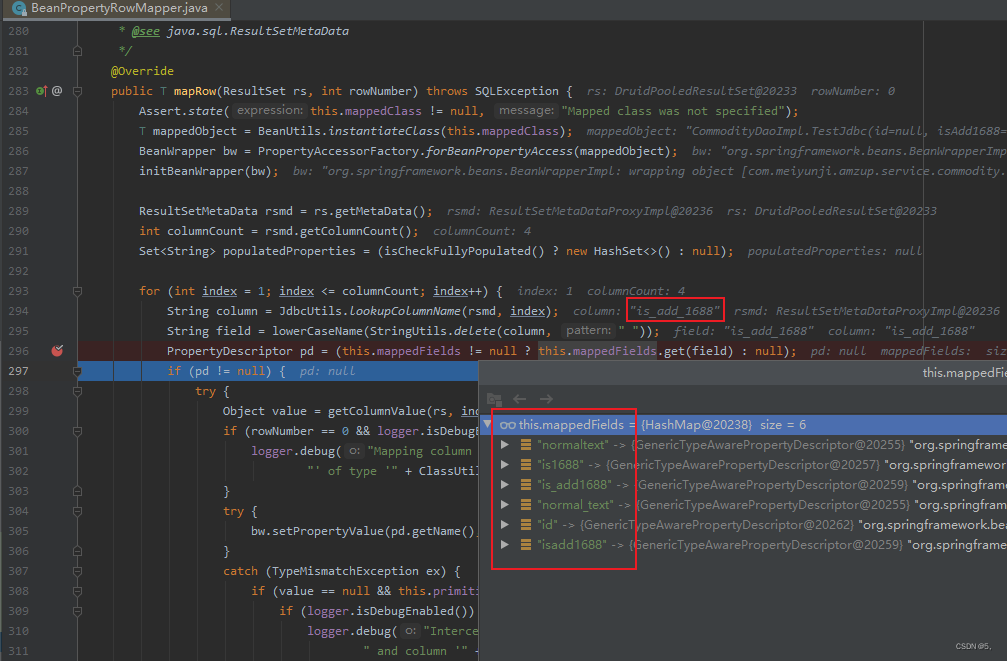
最终发现问题在这里。数据库中的字段是is_add_1688按理说应该会映射到isAdd1688,但是我们可以发现mappedFields没有is_add_1688,就会导致获取不到PropertyDescriptor,导致直接跳过了数据映射。
那我们再追踪一下,为什么mappedFields中没有is_add_1688这个映射值呢?
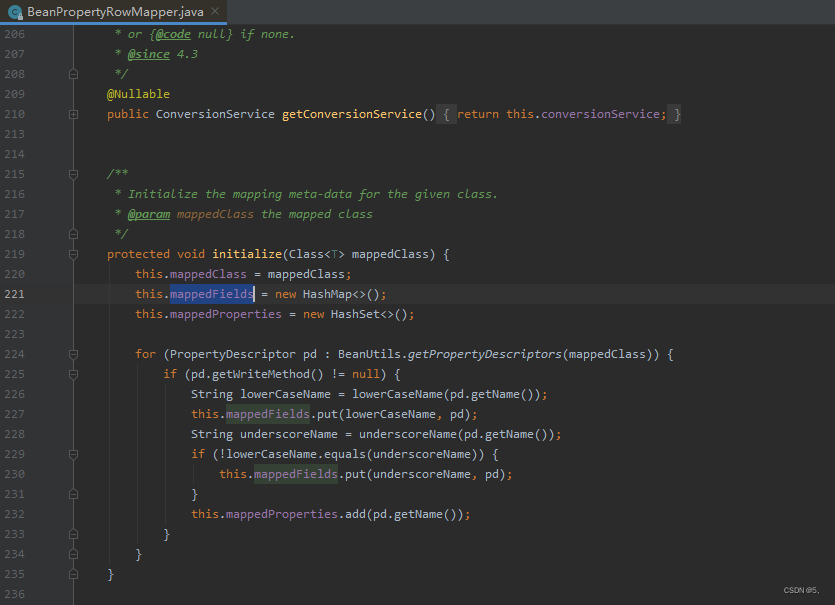
可以发现在实例化的时候,就会通过lowerCaseName()和underscoreName()设置mappedFields
看看这两个方法分别是什么
lowerCaseName()
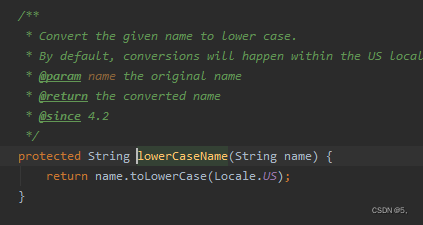
翻译得来:将给定的名称转换为小写。
默认情况下,转换将在us本地进行。
underscoreName()
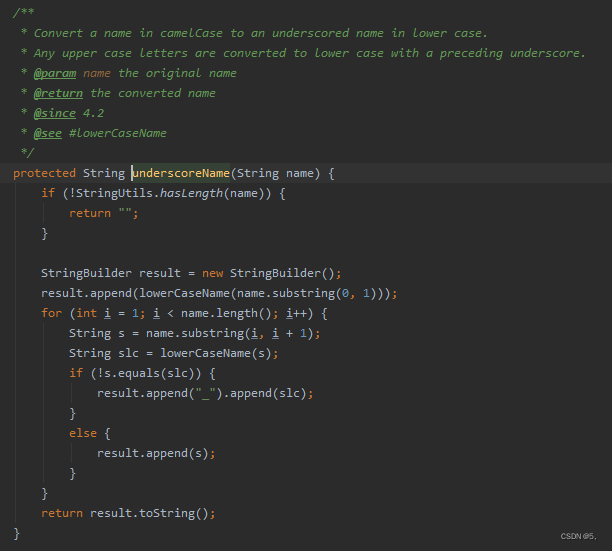
翻译:将 camelCase 名称转换为下划线小写名称。
任何大写字母都会通过前面的下划线转换为小写字母。
这里发现,他会将驼峰转换成下划线。那么实体isAdd1688这个字段后缀是数字,那么它转换成了isAdd1688和is_add1688,并没有对应数据库中的is_add_1688
那么怎么解决这个问题呢?
方法一:查询时,不使用BeanPropertyRowMapper。
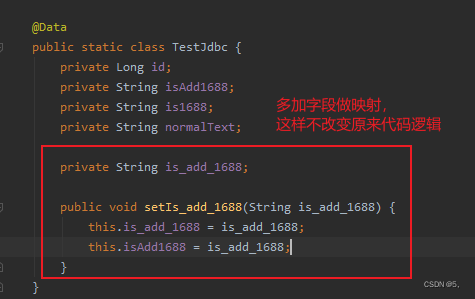
方法二:实体中多加个字段做映射。
公司使用的spring版本:5.2.24.RELEASE。后续版本spring有没有修复本人并没有去关注。有兴趣的小伙伴可以关注下。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









