







题目:
Write a function to find the longest common prefix string amongst an array of strings.
If there is no common prefix, return an empty string "".
Example 1:
Input: ["flower","flow","flight"]
Output: "fl"
Example 2:
Input: ["dog","racecar","car"]
Output: ""
Explanation: There is no common prefix among the input strings.
Note:
All given inputs are in lowercase letters a-z.
这道题需要找出一组string的共同前缀。乍一想很简单,但只想出了一种方法:从头遍历一遍每个string,如果每个string的当前字母都相同则加入prefix,否则直接返回空字符串。在提交的时候遇到了一个小坑,直接就runtime error了,才发现原来需要考虑到输入的vector为空的情况,这点刚开始没有考虑进来,后续的题目都需要注意了。上面方法的代码如下,时间复杂度O(s),s为所有string的长度总和,空间复杂度O(1),运行时间4ms:
class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
if (strs.size() == 0) {
return "";
}
string prefix = "";
for (int i = 0; i < strs[0].length(); i++) {
char first = strs[0][i];
for (int j = 1; j < strs.size(); j++) {
if (first != strs[j][i]) {
return prefix;
}
}
prefix += first;
}
return prefix;
}
};参考solution以后得到另外一种和上面的做法很像的,上面这种做法可以看作是vertical scanning,即针对每个字母的scan,而另一种horizontal scanning则是针对每个单词的scan,首先通过前两个单词得到一个prefix,然后拿这个prefix与后面的每个单词作比较,得到最终的prefix,代码就懒得再写一遍了就贴个solution里面给出的Java代码:
public String longestCommonPrefix(String[] strs) {
if (strs.length == 0) return "";
String prefix = strs[0];
for (int i = 1; i < strs.length; i++)
while (strs[i].indexOf(prefix) != 0) {
prefix = prefix.substring(0, prefix.length() - 1);
if (prefix.isEmpty()) return "";
}
return prefix;
}另外还有两种方法是我完全没有想到的,分别是分治法和二分法。听起来似乎很高贵但是其实它们的性能还不如前面的简单方法,而且代码写起来巨复杂无比,然而为了训练自己对于这两种方法的熟练度,于是还是决定硬着头皮把它们实现一遍。
首先是分治法,它的思想在于,先把那一串string不断分成两部分直到不能再分(分),然后再倒着合并每次取prefix的结果(治),盗一下solution里的图,感觉非常直观:
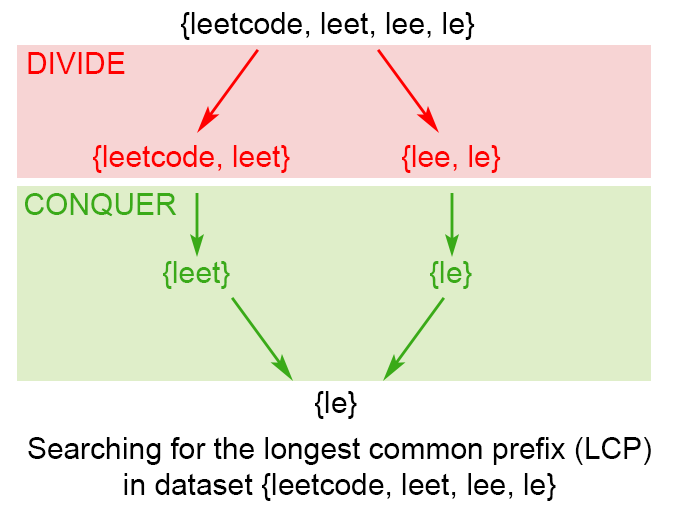
代码如下:
class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
if (strs.size() == 0) {
return "";
}
return lcp(strs, 0, strs.size() - 1);
}
string lcp(vector<string>& strs, int l, int r) {
if (l == r) {
return strs[l];
}
else {
int mid = (l + r) / 2;
string lcpLeft = lcp(strs, l, mid);
string lcpRight = lcp(strs, mid + 1, r);
return commonPrefix(lcpLeft, lcpRight);
}
}
string commonPrefix(string lcpLeft, string lcpRight) {
int min_len = min(lcpLeft.length(), lcpRight.length());
string prefix = "";
for (int i = 0; i < min_len; i++) {
if (lcpLeft[i] == lcpRight[i]) {
prefix += lcpLeft[i];
}
else {
return prefix;
}
}
return prefix;
}
};分治法时间复杂度同样为O(s),具体的一些分析已经看不太懂了orz 以后还是要复习一下复杂度分析方面的知识。就贴一下lc给出的分析吧:
最坏的情况下一共有n个长度为m的相同的string,时间复杂度为 , 即O(s),s=m*n;最好的情况下只需要进行O(minLen⋅n)次比较,minLen是数组中的最短的string的长度。
空间复杂度为O(m*log(n)),因为有log(n)次递归调用,每次需要m的空间来存储。
另一种方法是二分法,其实和分治法有点像,但感觉分治法是对整个string数组进行拆分(类比上面说的horizontal scanning),而二分法像是对string进行拆分(类比我最开始想到的vertical scanning)。把第一个string拆成两半,分别测试左半边是否在数组里的每一个string中,如果都在,则可以把右半边再分成两半,加入右半边的左半边,再次进行前面的判断;如果有不在数组中的其他string中的,那么就重新使用左半边进行判断,如此循环。
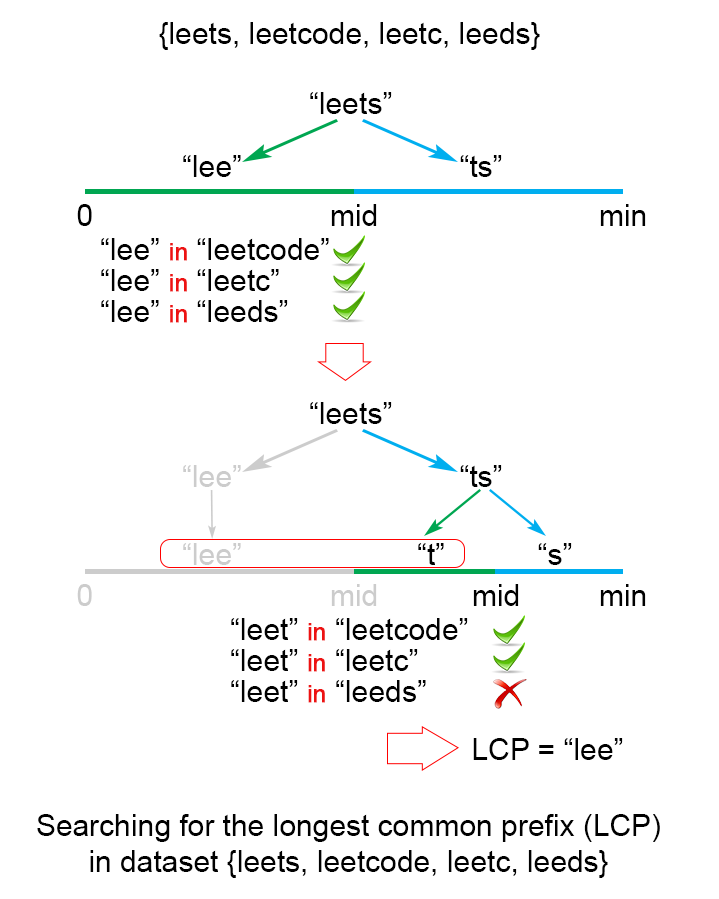
代码基本上是照着solutions抄的,而且理解起来特别费劲,看来还真的得多熟悉熟悉啊:
class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
if (strs.size() == 0) {
return "";
}
int min_len = INT_MAX;
for (int i = 0; i < strs.size(); i++) {
if (min_len > strs[i].length()) {
min_len = strs[i].length();
}
}
int low = 0;
int high = min_len;
while (low <= high) {
int mid = (low + high) / 2;
if (isCommonPrefix(strs, mid)) {
low = mid + 1;
}
else {
high = mid - 1;
}
}
return strs[0].substr(0, (low + high) / 2);
}
bool isCommonPrefix(vector<string> strs, int len) {
string prefix = strs[0].substr(0, len);
for (int i = 1; i < strs.size(); i++) {
if (strs[i].substr(0, len) != prefix) {
return false;
}
}
return true;
}
};在主函数里定义好每次的low和high,while循环到low和high相遇时停止,说明已经达到了lcp的位置,此时返回string从头到这个位置的substring就可以了。在循环的过程中,不断判断string从头到当前的mid是否是lcp(这里需要用到辅助函数),如果是则下一次的low为mid+1,搜索后半部分,否则下一次的high为mid-1,搜索前半部分。辅助函数中的参数是string的数组和需要判断的长度,返回值为这个长度的substring是否为commonPrefix。
由于一共需要进行log(n)次循环,每次循环需要进行s=m*n次比较,因此时间复杂度为O(log(n)*s),空间复杂度为O(1)。
总结一下这道题,本来刚开始自己写的时候很快就写好了以为这道题很简单,没想到看到了分治和二分的做法以后居然花了这么久来弄懂它们的思路和代码,以及居然是我最开始想的简单粗暴的方法的性能是最好的。写到分治和二分才猛然意识到自己的基础真的非常薄弱了,明天大概还要回来再复习一下这两份代码看能不能默写出来。















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









