






目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于机器学习的消费者品牌决策偏好动态识别与效果验证
课题背景和意义
准确识别消费者的品牌决策偏好有助于提升精准营销效率,避免推荐结果出现品牌歧视和低价竞争, 有利于改善消费者体验。
准确识别消费者的品牌决策偏好有助于提升
精准营销效率,避免推荐结果出现品牌歧视和低价竞争,有利于改善消费者体验。
购物方式的变化使消费者的购买行为数据通过互
联网被记录下来,而各电商平台可以通过对这些数据的
分析发现消费者的偏好特征,从而向其提供更为个性化
的推荐服务。
然而,当前的推荐代理系统依然存在对
消费者品牌偏好关注不足的问题。传统的推荐算法往往
基于产品外部特征和消费者画像,
尽管品牌在消费者决策过程中扮演着重要角色,但是现有的推荐算法却没有考虑消费者的品牌决策与偏好。
通过自
适应的机器学习算法,即时分析每个消费者的个性化品
牌偏好,精准识别消费者的情感需求,并依据所开发的
模型动态预测其品牌选择行为,为消费者行为研究方法
的拓展和精准营销的深化提供新的思路。同时,本文也
希望在实践层面助力电商平台等网络零售商提高运营效
益,为高附加值的小众品牌营造更加公平的竞争环境,
提升在线消费者的消费体验。
实现技术思路
一、文献综述与研究框架
消费者品牌决策模型
通过消费者调查方式统计和分析消费者品牌偏好和购买倾向,这类初期的统计研究结果都较为一致地显示出消费者品牌偏好具有明显的异质性。通过
一些复杂的统计分析方法开始被运用到消费者品牌选择行为的研究中,并建立起一些模拟消费者思维的决策模型。
消费者品牌决策影响因素
由于技术水平受限,互联网、大数据和人工智能等技术尚未成熟,在消费者品牌决策模型领域难以有重大突破,20
世纪
80
年代以后学者开始侧重于寻找影响消费者品牌选择行为的具体因素,主要包括两大类 :一是品牌自身的固有因素,二是消费者等品牌以外的影响因素。
研究框架
品牌的重要功能之一是帮助消费者识别不同组织、产品或服务,将其与竞争对手区分开来。
在当前产品同质化、复杂化的背景下,开发消费者品牌决策偏好识别模型对理论研究和营销实践都
具有积极的意义。以手机为例:由于智能手机在产品层面上同时具有同质化和复杂性的特点,通过消费者对智能手机品牌决策的实验研究来开展品牌决策偏好模型的构建和检验。实验过程涉及 110
个市场主流智能手机样本,涵盖 32
个不同手机品牌。本文的研究框架如图:
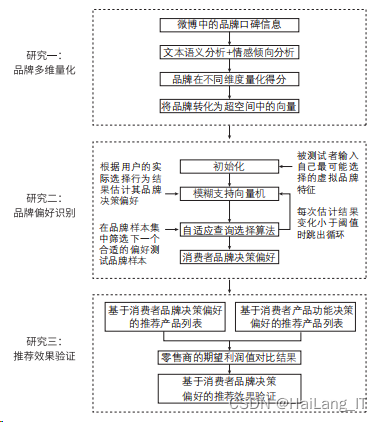
二、品牌多维量化
品牌量化方法
运用机器学习算法识别消费者品牌决策偏好,首先需要将品牌进行多维度的量化,将每个品牌从一个抽象概念转化为计算机可以处理的向量,尔后才能通过消费者的实际选择行为识别其对品牌不同维度的敏感度,即消费者的品牌决策偏好。
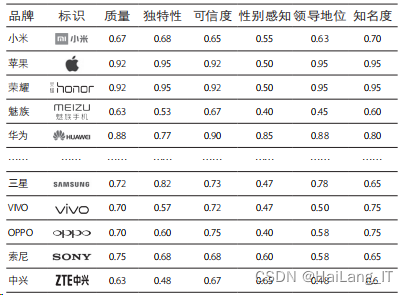
品牌量化结果
通过关键词匹配搜集信息,剔除不相关、重复和广告促销信息后得到精确匹配的信息。

品牌量化算法如公式和所示:

具体的计算步骤如下:
第一,本文在进行微博信息情感分析时主要借鉴Pai 等测量电子口碑情感倾向的做法,认为一条口碑信息中往往包含多个主体(Subject),
第二,计算机通过查询
Boson
语料库对上述文本分析中所涉及的每一个词确定其程度(Level);
第三,在以上计算结果基础上,先定位该条
信息中出现的某品牌关键词,例如“华为”(可能出现
多次) 将 每 个品牌关 键 词 前后
5
步内所有词的权重(Weight
)与其相应的程度(Level)相乘之后计算均值。
第四,在得到单条微博信息的情感分析得分基础上,
本文将计算每个品牌在各个维度上所有口碑信息得分的
平均值,作为最终的量化结果。
部分品牌量化结果:
三、品牌偏好识别
利用本文提到的基于模糊支持向量机的机器学习算法模型与其他传统方法,通过实验识别出消费者的品牌决策偏好,并在此基础上预测可能的品牌决策行为,最后将预测结果与实际选择行为进行对比。
实验材料与流程
第一步,获取初始态度数据。提出的模糊支持向量机算法模型和普通支持向量机算法模型,均要求被试在考虑价格合理的情况下输入最偏好的虚拟品牌类型,从而实现算法的初始化。第二步,采集动态选择数据。第三步,验证模型的有效性。在得到全部被试的品牌决策偏好估计值之后,这一步要求被试在验证样本集中再标注
随机样本品牌的选择结果。
模型有效性评价标准
采用三种被广泛接受的模型性能评价指标作为模型有效性的评价标准,分别是准确(Accuracy
)、
K L
散度、
F
1
-
measure
。
1)准确率
准确率是模型预测结果与被试者真实决策行为相比的正确率。
2)
K L
散度
K L
散度是描述两个分布之间差异的方法,取值为0-
1
。两个分布之间的差异越小则
K L
散度取值越接近
0
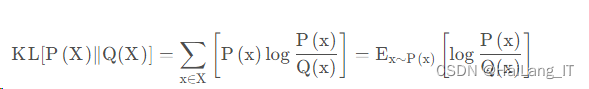
3)F
1
-
measure
是衡量机器学习等分类模型的常用评价指标,同时考虑正确预测和错误预测的比例,取值范围为 0
-
1
,越接近
1
表明模型性能越好。
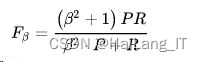
四、推荐效果验证
研究流程
首先,在模糊支持向量机算法模型的基础上,用相同算法建立了
消费者产品外部特征偏好识别模型, 即基于模糊支持向量机算法的消费者产品外部特征偏好识别模型。接着,通过该模型识别出使用模糊支持向量机模型识别品牌决策偏好
产品外部特征决策偏好。再次,分别基于
品牌决策偏好和外部特征决策偏好,在
样本中筛选出最符合每个被试者真实偏好的产品。
![]()
实现效果图样例
分别使用模糊支持向量机模型、普通支持向量机模型、“Dollar
-
metric
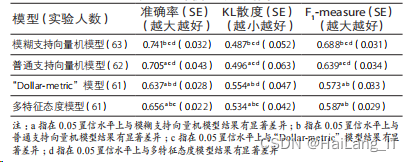
”模型和多特征态度模型, 识别每一个被试的品牌决策偏好,利用该品牌决策偏好估计结果来预测被试对验证样本集中 20 个随机品牌样本的选择行为,并将预测结果与消费者实际选择行为进行对比,四组之间的对比结果:
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









