










目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯毕业设计-基于人工智能的脱机手写数字识别系统
课题背景和意义
在光学在光学字符识别领域中,手写数字识别是一个必不可少的组成部分,它是在光 学字符识别基础上,采用计算机等处理器对手写阿拉伯数字进行识别的一种技术。依据字体 分类,数字识别可分为印刷体识别和手写体识别两类,而手写体识别遵从识别时间分类,又 可分为联机手写体识别与脱机手写体识别两种模式。目前印刷体和联机手写体数字识别系统 的使用非常成熟,但对于脱机手写体数字系统的应用则较为缓慢。由于脱机手写体数字是由 众多不同类型的人们手动书写形成,每个人的书写方式不同,很难实现一个兼顾多种书写方 式的实用性数字识别系统。从识别的角度来看,手写体识别难于印刷体识别,而脱机手写体 识别又难于联机手写体识别。手写数字识别的应用非常广泛,如财政报表、银行单 据、试卷成绩统计、交通违章车辆号码牌录入等,之前需要大量的手工录入,人力物力投入 较多,劳动强度也较大,然通过对脱机手写数字识别的研究既可以适应无纸化办公的需要, 又能极大提高工作效率。目前手写数字识别仍然是一门有待提高和发展的技术, 因此对其不断深入的研究对诸多行业具有深远的意义。
实现技术思路
一、相关背景知识介绍
智能优化算法
优化问题是指在满足一定条件下,在众多方案或参数值中寻找最优方案或参数值,以使 得某个或多个功能指标达到最优。智能优化算法是通过模拟或揭示某些自然界的现象和过程或 生物群体的智能行为的一类算法,具有简单、通用、便于并行处理等特点,因此在图像处理、 模式识别、自动控制和机械设计等众多领域广泛应用。
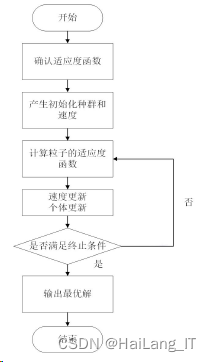
1、PSO算法
粒子群算法(PSO)是一种基于蜂群的智能优化算法,曾受到动物的社会行为影响,如 一群鸟类寻找食物来源或一群鱼保护自己不受捕食者的伤害。PSO中的粒子类似于鸟或鱼在 搜索空间中飞行。每个粒子的运动都是靠速度来协调的,速度又同时具有大小和方向,引导 粒子的飞行。PSO算法可以通过以下方程式得到:

PSO算法优化的具体步骤如下:
2、GA算法
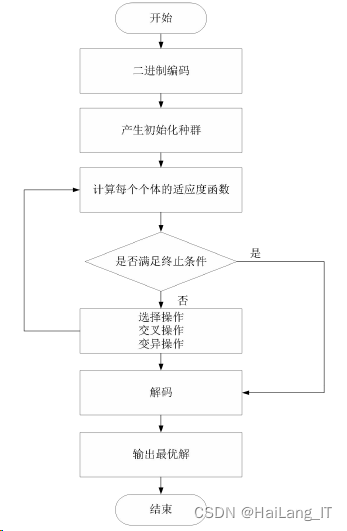
该 算法是一种基于自然选择和自然遗传学机制的随机搜索算法,在优化设计、模糊逻辑控制、 神经网络、专家系统等许多领域都得到了应用。与传统搜索算法不同,GA算法从一组被 称为总体的初始随机解开始,种群中的每个个体都被编码为一条染色体。解码公式被定义为:

GA算法优化的具体步骤如下:
3、SSA算法
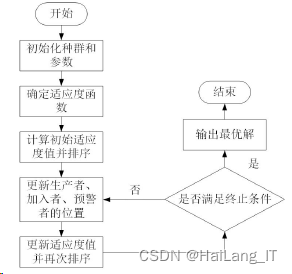
麻雀搜索算法(SSA)是薛剑凯于2020年提出的一种新的群体智能优化算法,其源于麻 雀的觅食和反捕食行为。麻雀是一种有着强烈记忆的群居鸟类,通常来说,在群体中存在两 种不同类型的麻雀即生产者和加入者。生产者主要负责寻找觅食区域并为整个鸟群提供方向, 而加入者则利用生产者获得食物。通常生产者和加入者的个体行为可以相互转化。在觅食的 过程中,种群中的个体是会监视种群中其他个体的行为。
根据以上描述, 可以建立SSA算法的数学模型。假设在d维搜索空间中有n个麻雀构成的种群表示如下:
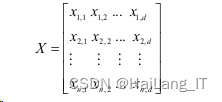
所有麻雀的适应度值XF可表示如下:

在SSA算法中,适应度值XF表示能量储备,能源储备较高的生产者在搜索过程中将优先考 虑获取食物。一般来说,生产者占种群数量的10%至20%,负责寻找食物,并拥有更大的觅 食搜索范围,同时生产者应通过下述表达式来不断更新他们的位置:
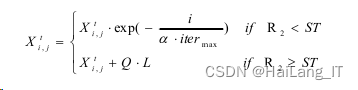
SSA算法优化的具体步骤如下:
特征提取
特征提取的定义是通过映射或变换把原始空间的高维特征变成了特征空间的低维特征, 即用由较多的原始特征映射得到的较少的新特征来描述样本,这个过程称为特征提取。
1、像素降维法
图像的像素降维法主要是主成分分析法和独立成分分析法[36]。其中主成分分析法(PCA) 是模式识别中常用的一种线性变换方法,其目的是通过分析之前较多可观测数据分量所反映 的总体信息来提取出较少的一部分数据分量,由于它们是线性无关的,这部分数据能最大限度 地反映出原来较多数据分量所包含的信息,用这较少的几项综合性数据分量来刻画总体。
2、结构特征法
对不同的数字而言,尽管书写的风格千差万别,然而笔划与笔划之间的位置关系、以笔划 为基元的字符的整体拓扑结构是不变的。对于这种基于笔划的手写体数字一直是手写数字识 别研究的重点。通过对手写数字进行结构分析,提取其特征的方法,叫做结构特征法。
3、统计特征法
统计特征是指研究有关特征在总体中的个体之间分布情况,把所要考察的特征称为总体 的统计特征。主要包括投影特征、傅立叶系数特征、小波系数特征、13点网格特征等。
4、特征融合
特征提取之后,对数据的中间层次进行融合,它是对图像预处理和特征提取后得到的图 像特征信息再次进行分析与处理。串行特征是将两组特征向量进行首尾相连,形成一个新的 特征向量。
二、基于智能优化算法的SVM在手写数字中的应用
SVM原理介绍
支持向量机(SVM)是由VapnikV等人于1995年提出的一种通用学习方法,成功通过核函 数的思想把低维空间非线性分类问题转变为高维空间线性分类问题,该方法的提出是统计学 和机器学习领域的重大成果。
线性分划与非线性分划
SVM方法是在线性可分的情况下,通过最优分类面而提出的一种方法。图描述的是 最优分类面情况,图中的实心点和空心点分别表示两类的训练样本,H是分类线,H1和H2分别是各类样本中离分类线最近的样本点,且平行于分类线的直线,H1和H2之间的距离叫做两 类的分类空隙或分类间隔,所谓最优分类线就是要求分类线不但能将两类无错误地分开,而且 要使两类的分类间隙最大,推广到高维空间,则最优分类线就成为最优分类面。
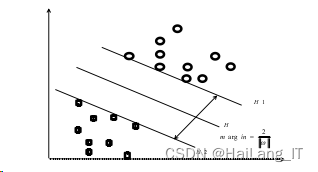
在已知法向量T的情况下,对直线构造划分的方法可转化为求解法向量T的问题。为了使 分类间隔达到最大,最优分类线H的方程为:
![]()
分类线H1的方程为:
![]()
分类线H2的方程为:
![]()
1)线性可分问题如图所示,没有样本点处在超平面H1和超平面H2中间,且所有的样本点都被安排在正确的那一侧。
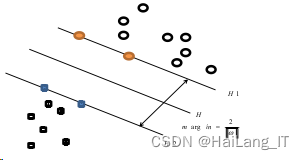
2)近似线性可分问题如图所示,图中那个紫色方形是单独的一个样本,使得原本线性 可分的问题变成了线性不可分的。由于线性分划造成的错分点可能较少,所以增加一个松弛 项即可。
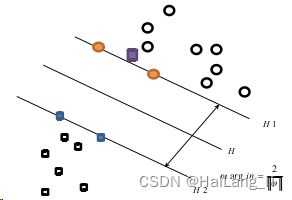
3)在非线性可分的问题上,设法通过非线性映射转化为另一个空间中的线性问题,求最 优或广义最优分类面。图展示了非线性映射的过程,若输入空间的分类样本数 据不是线性可分,则在特征空间为线性可分。
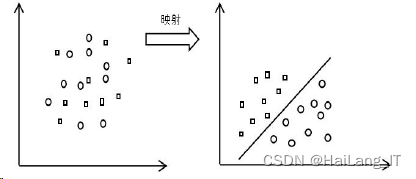
3、SVM分类算法
SVM不仅能够解决传统的二分类问题,还能处理现实中经常面临的多分类问题。在求解 决多分类问题时,首先构造出一系列的二分类问题,并建立相应的二分类机,然后根据这些 二分类机判定输入样本数据的属性,从而构造不同的二分类问题,由此产生了三种不同的分 类算法分别为:一对一分类(OVO),一对多分类(OVA),有向无环图法(DAG)等。
核函数及参数选取问题
核函数是SVM中重要的组成部分,SVM在处理非线性问题的时候是通过核函数的思想 把低维空间非线性分类问题转变为高维空间线性分类问题。
三、基于智能优化算法的KELM在手写数字中的应用
ELM及其相关基础理论
近年来有关极限学习机(ELM)的研究和扩展已有了高速的发展,由于ELM模型简单、泛 化性能强、具有极快的学习速度和较少的人为干预,表现出了广阔的前景和应用潜力,在疾 病诊断、交通标志识别、手写数字识别等领域取得了丰硕的研究成果。
1、标准ELM原理
传统的基于梯度学习算法通常需要更多的训练样本和更长的学习时间,往往会导致学习 模型过拟合现象严重,但ELM却可以克服学习速度慢,需要在各种应用中进行复杂的参数调 整等缺点。ELM具体实现过程如下:
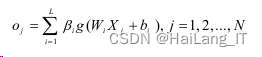
2、RELM原理
由于ELM采用的是经验风险最小化原则,训练的模型容易产生过拟合现象。在有限样本 的情况下,从统计学的角度来看,经验风险最小化原则并不是令人满意的原则。只要训练样 本中有较多离群点的出现,隐藏层的输出矩阵H具有不确定性,可能会使得模型的泛化性能 变差。
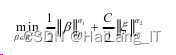
3、KELM原理
标准的ELM模型是不包含核函数的,但是当ELM的输入矩阵随机确定以后,可以看到 ELM的单隐层结构正好符合了一种非线性的显示映射。通过大量实验可知,标准的ELM对 于分类问题通常需要设置大量的隐藏层神经元数量,说明了ELM需要将样本数据映射到更 高维的特征空间,这与核函数的相关原理是相符的。将KELM的核矩阵定义为:
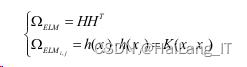
ELM的输出可以描述为:
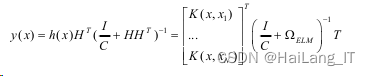
基于KELM的参数选取与优化问题
在KELM的学习训练过程中,核函数的引入虽然替代了ELM隐藏层参数的随机初始化, 但选择什么类型的核函数在一定程度上会影响KELM的性能。除了核函数问题,还有KELM 的正则化参数选择问题,若这两个参数的选择不恰当,便会影响模型分类的准确性,因此参 数的选择显得尤为重要。
1、KELM参数选取
关于KELM中核函数的选取,与SVM中核函数的选取类似,常用的核函数有线性核函 数、多项式核函数、径向基核函数(RBF)、Sigmoid核函数等。由于RBF核作为核函数具备了 较强的学习能力,选用RBF核函数。
2、智能优化算法优化参数
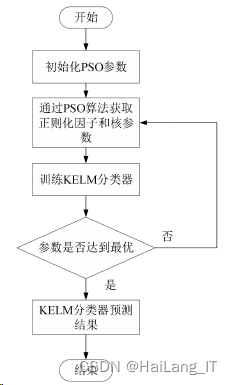
众所周知,为了让模型得到更好的分类精度和更强的稳定性,参数的选择十分关键。关 于如何才能获得最优的参数问题,通常来说有两种方法:第一种就是实验法,第二种是智能 优化法。通常来说有两种方法:第一种就是实验法,第二种是智能 优化法。选用第二种方法。将KELM与PSO算法结合建立PSO+KELM模型。有关PSO+KELM模型的具体步骤如图:
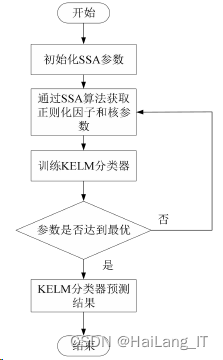
基于智能优化算法中的SSA算法,将KELM与SSA算法结合建立SSA+KELM 模型。有关 SSA+KELM模型的具体步骤如图所示:
实现效果图样例
手写数字识别系统

我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!














 3547
3547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









