







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于计算机视觉的采矿车装载状态识别系统
课题背景和意义
在采矿行业中,准确判断采矿车的装载状态对于矿山的运营效率和安全管理至关重要。传统的装载状态判断方法通常依赖于人工观察和主观判断,存在主观性、误差和效率低下的问题。通过自动化识别采矿车的装载状态,可以实时监测和评估车辆的装载情况,提高装载效率,降低运营成本。
实现技术思路
一、算法理论基础
1.1 卷积神经网络
卷积神经网络是一种深度学习模型,其特别适用于处理图像数据。它通过卷积层、池化层和全连接层等组件,能够自动学习和提取图像中的特征。在采矿车装载状态识别系统中,卷积神经网络可以通过训练大量标注好的采矿车图像数据,学习到不同装载状态下的特征表示。
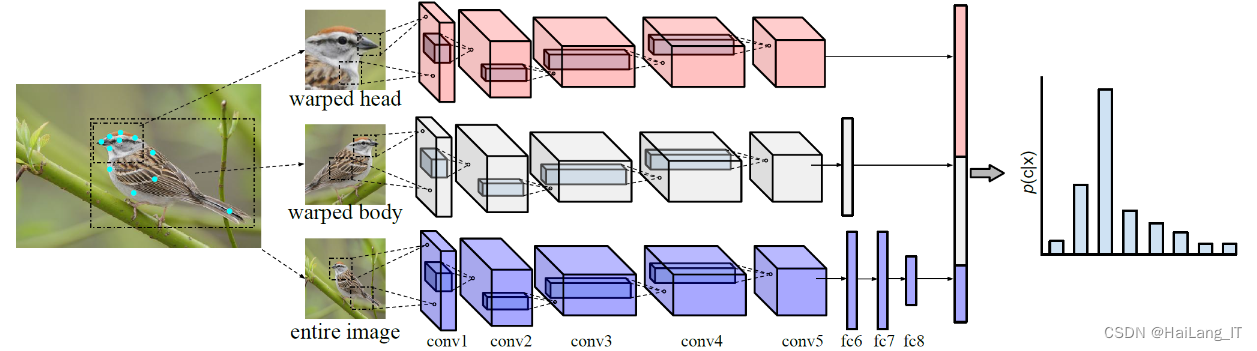
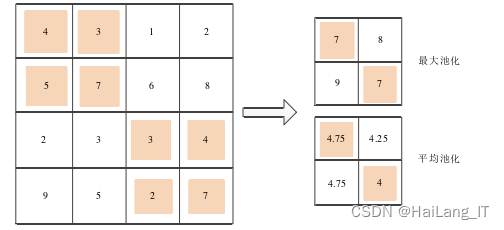
卷积神经网络通常由输入层、卷积层、池化层、全连接层和输出层组成。输入层接收二维图像作为输入,并具有智能性,能够自动提取图像中的特征。卷积层对输入图像进行卷积运算,通过卷积核的权重与每个像素进行内积运算,得到特征图。池化层用于降采样,减少特征图的尺寸和参数量。全连接层将池化层输出的特征图连接成向量,然后通过全连接层进行分类或回归任务。输出层具有多个输出维度,用于识别目标任务的不同类别。
卷积神经网络通过卷积运算和池化操作提取图像特征,然后通过全连接层进行分类或回归。输入层自动获取图像的特征,卷积层对图像进行特征提取,池化层进行降采样,全连接层进行最终的任务分类或回归。这样的网络结构使得卷积神经网络在计算机视觉任务中表现出色,能够有效地处理图像数据并提取关键特征。
相关代码示例:
class MiningTruckClassifier(nn.Module):
def __init__(self, num_classes=3):
super(MiningTruckClassifier, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(32 * 8 * 8, 128)
self.fc2 = nn.Linear(128, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.conv2(x)
x = self.relu(x)
x = self.maxpool(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x1.2 卷积神经网络
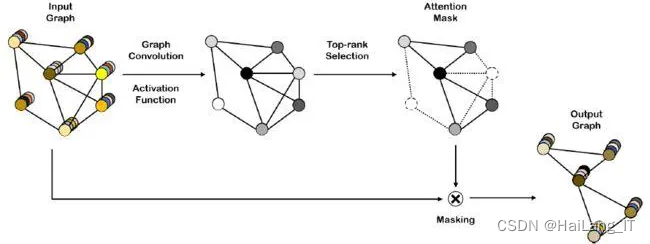
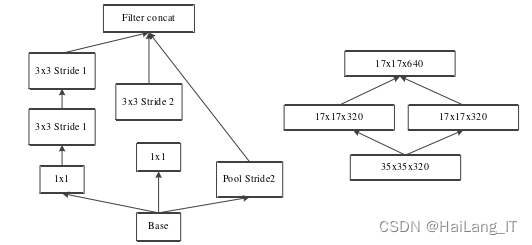
并行Inception结构通过同时使用不同大小的卷积核进行卷积操作,可以在不同尺度上获取图像的特征信息。这种并行操作可以捕捉到不同尺度下的细节和上下文关系,从而提高网络对图像的感知能力。过并行的方式进行卷积操作,避免了串行操作中的信息瓶颈问题,并且可以共享参数,减少网络的参数量和计算量。这样可以提高网络的效率和速度,并且减少过拟合的风险。通过并行Inception结构,网络可以同时获取多尺度信息、减少计算量、实现多层次特征提取、具备可扩展性和强大的表达能力。这些优点使得并行Inception结构成为卷积神经网络中常用的设计模块,对于图像识别、目标检测和图像生成等计算机视觉任务具有重要作用。
由于卷积神经网络的深度不断增加,网络在进行特征提取时会逐渐变得更加抽象化。这是因为深层网络的卷积层和池化层对输入数据进行多次非线性变换,导致高级特征逐渐形成,而低级特征逐渐丢失。这种抽象化的过程可能会在一定程度上降低网络的精度。引入残差连接可以帮助解决梯度消失或梯度爆炸的问题,同时减轻了信息的丢失。残差连接允许网络跳过某些层,使得低级特征可以直接传递到深层,从而更好地保留细节特征。
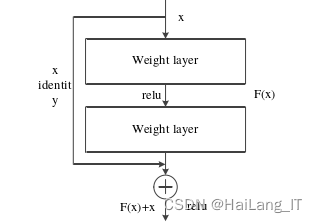
相关代码示例:
class ResNet(nn.Module):
def __init__(self, num_classes=10):
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(64, 64, blocks=2, stride=1)
self.layer2 = self._make_layer(64, 128, blocks=2, stride=2)
self.layer3 = self._make_layer(128, 256, blocks=2, stride=2)
self.layer4 = self._make_layer(256, 512, blocks=2, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, in_channels, out_channels, blocks, stride):
layers = []
layers.append(ResidualBlock(in_channels, out_channels, stride))
for _ in range(1, blocks):
layers.append(ResidualBlock(out_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
1.3目标检测算法
Faster-RCNN是在RCNN和Fast-RCNN的基础上进行改进和优化的目标检测网络,旨在提高检测精度和处理速度。该网络的主要流程包括卷积层特征提取、区域生成、分类和回归。Faster-RCNN通过优化和改进RCNN和Fast-RCNN的结构,实现了更高的检测精度和更快的处理速度。它的网络流程包括特征提取、区域生成、分类和回归,通过两个阶段的训练来实现目标检测任务。这使得Faster-RCNN成为目标检测领域中一种重要且有效的网络模型。
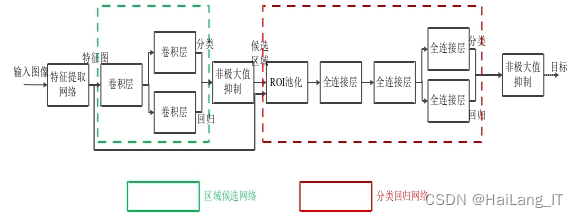
Faster-RCNN在第一阶段使用单尺度特征提取器时存在感受野与锚框不匹配的问题,导致特征图信息不完整或包含无用信息,影响检测精度。为了解决这个问题,引入了特征金字塔网络(FPN),能够在不同尺度上提取特征并建立多尺度的特征金字塔,使感受野与锚框更好匹配,提高检测的准确性。通过使用FPN,Faster-RCNN能够更好地处理多尺度目标,获取更全面的特征信息,适应不同大小和形状的目标物体,从而提高目标检测的性能。

相关代码示例:
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
# 加载配置文件
cfg = get_cfg()
cfg.merge_from_file("<path_to_config.yaml>")
cfg.MODEL.WEIGHTS = "<trained_weights_file>"
# 创建预测器
predictor = DefaultPredictor(cfg)
# 对测试集图像进行预测
test_dataset = DatasetCatalog.get("<test_dataset_name>")
for image in test_dataset:
outputs = predictor(image)
# 处理输出结果,例如可视化边界框二、 数据集
2.1 数据集
以重汽自卸式矿用工程车为例,该车的额定载重为12.62吨,货箱尺寸为6m(长度)x 2.3m(宽度)x 1.5m(高度)。在矿山运输中,选用沙子、矿石、煤渣等作为货物。为了方便后续装载状态的判别,选择运输车车斗侧面S上的点1、2、5、6作为源目标点,并对运输车的3D-Box进行角度旋转。通过透视变换,将转换后的图像得到以侧面为视角的图像,使得后续判别装载状态更加便捷。

为了进行装载状态判别,首先在不规则形状的货物图像上添加坐标系,将前板总成与车斗上半部边缘水平线的交点作为坐标原点。车辆行进方向为x轴正方向,车底至车顶方向为y轴正方向。然后,结合Canny算法和Sobel等形态学方法,对转换后的运输车侧视图进行截取,只保留货物形成的不规则形状,并将其映射在坐标系中

三、实验及结果分析
货物最高装载点与前板总成的位置关系:在建立坐标尺度时,以前板总成与车斗上半部边缘水平线的交点为坐标原点,车头至车尾方向为x轴,车底至车顶方向为y轴。根据对矿山运输车的车辆结构统计,前板总成的高度映射在坐标系y轴中大致范围为10-20之间。根据前板总成的高度,在水平方向上做延伸线,将货物最高装载点与前板总成的水平高度位置关系作为判别运输车装载状态的依据之一。
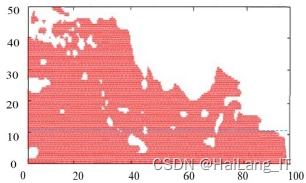
满额率:根据运输车的水平和竖直尺寸标准,考虑到货物为颗粒状物质如沙子、矿渣、煤灰等不规则形状,通过高斯滤波拟合形成平滑曲线。根据坐标系中x、y轴和拟合后的平滑曲线,形成闭合曲线,利用像素点数量计算闭合曲线的面积作为货物的面积。将前板总成水平延长线与x轴、y轴形成的矩形面积作为满额面积。满额率定义为货物面积与满额面积的比值,即满额率 = 货物面积 / 满额面积。满额率作为衡量运输车装载状态的第二个指标,用于判别装载状态的好坏。
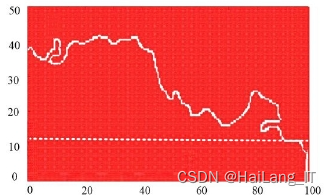
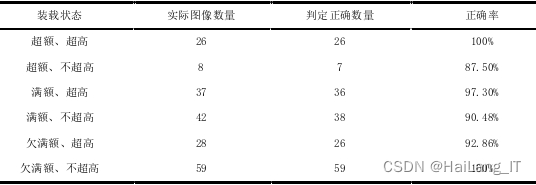
本研究通过对随机选取的200张运输车图像进行测试,评估了两个装载状态判别指标的有效性。结果显示,在判定超额、超高状态和欠满额、不超高状态时,准确率达到100%,判断结果非常准确。然而,在判定超额、不超高和满额、不超高状态时的准确率相对较低,可能由于不规则货物形状和图像变换导致的误差。对于欠满额、超高状态的判定准确率为92.86%。尽管存在一些偏差,但本文提出的算法已满足实际应用中对装载状态判别准确性的要求。根据判定结果,当装载状态为超额、超高或欠满额时,需要调整货物装载方式并召回运输车辆,只有满额、不超高状态才符合安全和高效要求。
最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









