







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于机器学习的钓鱼网站自动检测方法
课题背景和意义
随着互联网的发展,钓鱼网站作为网络安全中的一种严重威胁,给用户隐私和财产安全带来了巨大风险。钓鱼网站通常伪装成合法网站以窃取用户的敏感信息,如何有效识别和检测这些网站已经成为信息安全领域的重要研究课题。通过采用机器学习和特征分析等技术,能够实现对钓鱼网站的自动化检测,提高网络安全防护能力。这项研究不仅有助于提升用户的网络安全意识,还能够为网络安全产品和服务提供技术支持,促进网络环境的安全性与可靠性。
实现技术思路
一、算法理论基础
1.1 钓鱼攻击
钓鱼攻击的方式多种多样,钓鱼者为了获取利益,常常利用网站的漏洞、用户的安全意识低以及好奇心等因素。反钓鱼技术必须对钓鱼者的攻击手段有深刻了解,并采取相应的应对策略。常见的钓鱼攻击手段之一是伪造 URL,这种方法通过创建与合法网站相似的域名来欺骗用户,使其误以为自己访问的是安全的网站。例如,钓鱼者可以注册类似于知名公司的域名,降低用户的警惕性。此外,超链接隐藏也是一种常用手段,钓鱼者将真实的钓鱼 URL 藏在超链接下,用户往往只依赖超链接的文本来判断目标,导致上当受骗。
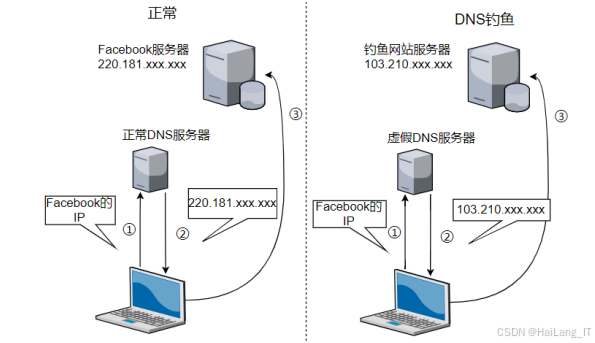
DNS 钓鱼,这种攻击通过劫持域名解析服务器或伪造服务器来改变目标网站的地址,导致用户无法访问或访问错误页面。钓鱼者通过攻击存在漏洞的 DNS 服务器,修改域名与 IP 的映射关系,将用户请求重定向至恶意网站。修改 Hosts 文件则是另一种策略,通过在用户系统中植入恶意代码,使得用户访问常用网站时被错误引导到钓鱼页面。路由交换技术也被用于此类攻击,通过修改路由表,使得用户的请求被重定向至不安全的网页,进一步加大了网络安全的风险。
XSS 跨站脚本攻击是一种非常普遍的网络攻击形式,攻击者将恶意脚本植入网页中,当用户访问该页面时,脚本会被执行,从而控制用户的浏览器,甚至盗取用户的敏感信息。攻击者可以利用低安全防护的网站,通过提交恶意代码,获取其他用户的账户信息。例如,恶意用户在评论区输入含有 script 标签的内容,其他用户在查看时会无意中执行这些脚本,导致个人信息泄露。XSS 攻击的多样性使得其成为网络安全领域的一大隐患,必须引起足够重视并采取有效防护措施。
1.2 钓鱼检测
随着钓鱼现象在网络上愈来愈普遍,各个组织机构纷纷将反钓鱼研究放到自己的技术重点中,安全研究人员也在利用计算机视觉、机器学习等计算机技术推动反钓鱼领域的进展。启发式钓鱼检测技术不同于传统的基于黑白名单、规则匹配等技术,其着眼于利用 URL、域名信息、网页内容等多个角度发掘具有区分度的代表特征。通过提取出相应特征的数据集,使用机器学习中的算法模型进行训练,使其具备良好的准确率和泛化性,从而实现对钓鱼网站的自动识别。这种方法的性能往往依赖于特征工程中的特征选取和分类模型算法的选择,是目前主流的钓鱼检测技术。
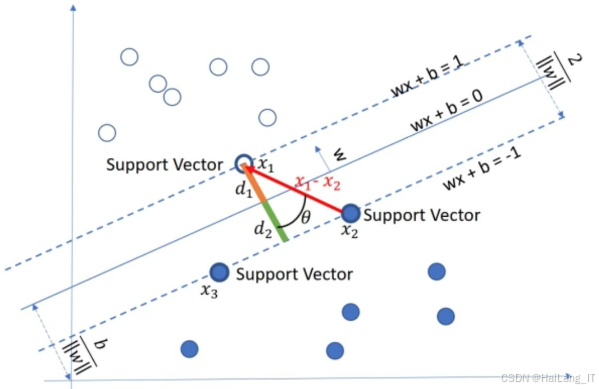
使用机器学习解决的问题从输出结果的角度,通常可以分为回归和分类两类。其中一种是输出变量为连续型数值的回归问题,另一种是输出离散型变量的分类问题。从反钓鱼技术的角度来看,钓鱼网站的检测是一个“是/否”类型的分类问题。常见的机器学习分类算法包括支持向量机和决策树。支持向量机是最常见的二分类器之一,给定一组训练数据,每个数据点被标记为两个类别之一。其算法的目标是找到一个超平面,使得训练数据表示的点到该平面的距离之和最小化。
决策树是一种特殊的树结构,由决策图和可能的结果组成,用于辅助决策。在机器学习中,决策树是一个分类预测模型。树中的每个节点表示某个对象,每个路径的分叉代表某个可能的属性值,而每个叶子节点则代表一种预测结果。决策树的决策过程从根节点开始,根据条件分叉选择不同路径,直至到达代表最终输出结果的叶子节点。
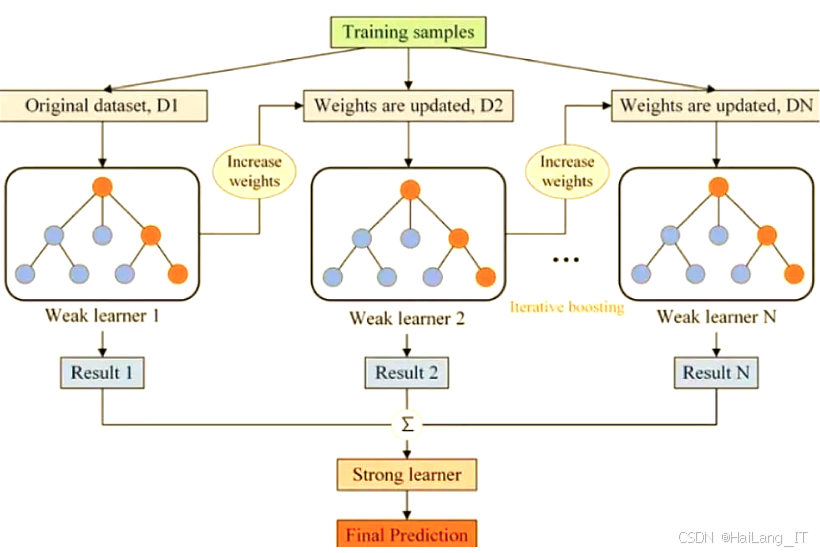
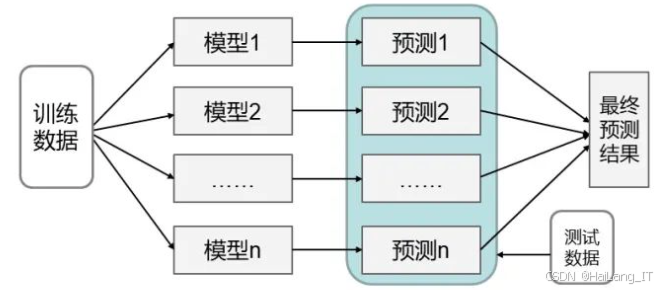
集成学习方法与传统分类方法不同,目标是学习多个分类器,组成一个元分类器。元分类器的分类结果通常由各个分类器的结果投票组合而成,与单个分类器相比,元分类器具备更好的泛化性能。目前的集成学习大致分为两种类型:一种是个体学习器间存在强依赖关系,必须串行生成,代表方法为 Boosting;另一种是个体学习器之间不存在强依赖关系,可以同时生成,代表方法包括 Bagging 和随机森林。这些方法在反钓鱼技术中发挥着重要作用,有助于提升检测的效果和准确性。
二、 数据集
使用公开的钓鱼网站数据集和网络爬虫技术是构建钓鱼网站检测系统的重要方式。公开数据集提供了易于访问、标准化且多样化的样本,能够有效支持模型的训练和泛化能力。而通过爬虫技术,可以针对特定需求实时抓取最新网站数据,灵活构建自己的钓鱼和合法网站数据集。正类样本可以通过 Alexa、DMOZ 和 BOTW 等机构获取基础域名,结合网络爬虫获取相关 URL;负类样本则主要来自 Phishtank 等反钓鱼组织。通过 WGET、WebShot 和 WHOIS 工具获取页面 HTML、网站截图及注册信息,这些数据集为系统的 URL 分类模块和页面分类模块提供了坚实的基础,显著提升了检测的准确性和效果。
三、实验及结果分析
将系统功能分为四个模块:URL 过滤模块、URL 检测模块、页面检测模块和品牌识别模块。这些模块通过前后关联实现对输入 URL 的检测识别。此外,还需要明确系统的非功能需求,如可用性和安全性,确保在高流量识别场景下系统的稳定性和高效性。
# 伪代码示例:功能需求分析
def analyze_system_requirements():
modules = ["URL过滤模块", "URL检测模块", "页面检测模块", "品牌识别模块"]
non_functional_requirements = ["可用性", "安全性"]
return modules, non_functional_requirements针对 URL 特征与页面特征提取时间的差异以及系统的并发性需求,提出级联检测方法。首先使用 URL 特征和 WHOIS 特征训练轻量级分类器,初步过滤掉非可疑的 URL,从而减轻后续模块的压力。接着,使用页面特征训练得到的分类器来最终判断是否为钓鱼网站。
# 伪代码示例:级联检测方法
def cascade_detection(url):
preliminary_classifier = train_preliminary_classifier() # 训练初步分类器
if preliminary_classifier.predict(url):
return "非可疑URL"
else:
final_classifier = train_final_classifier() # 训练最终分类器
return final_classifier.predict(get_page_features(url))在 URL 过滤模块中,使用 Redis 内存数据库进行 URL 去重,并利用 MySQL 黑白名单数据库进行过滤。在 URL 检测模块中,选取多种特征并提出基于编辑距离的异常品牌检测算法。在页面检测模块中,采用无界面浏览器获取隐藏页面特征并训练分类器。品牌识别模块则使用轻量级的 MobileNet 网络模型对爬虫获取的数据集进行迁移学习。
# 伪代码示例:各模块实现
def url_filter_module(url):
if redis_check(url): # Redis去重
return "URL已存在"
return mysql_filter(url) # MySQL黑白名单过滤
def url_detection_module(url):
features = extract_features(url)
return anomaly_detection(features) # 基于编辑距离的异常检测
def page_detection_module(url):
page_features = get_hidden_page_features(url)
return page_classifier.predict(page_features) # 使用训练好的分类器
def brand_recognition_module(data):
model = load_mobilenet_model()
return model.predict(data) # 迁移学习海浪学长项目示例:



最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 2071
2071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









