







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的微博舆情动态分析系统
课题背景和意义
在数字化时代,社交媒体的兴起使得公众能够迅速表达对突发热点事件的看法与情感。新浪微博作为中国重要的社交平台,其评论数据蕴含着丰富的舆情信息。对这些数据进行有效分析,能够帮助政府和相关机构及时掌握公众情绪,制定相应的危机应对策略。深度学习技术可以更好地捕捉评论中的时序特征,提升舆情分析的准确性与实时性。
一、算法理论基础
1.1 情感分析
情感词典是情感分析的基础,包含大量带有情感色彩的词汇及其情感极性和情感强度。微博舆情动态分析中,使用情感词典可以快速有效地进行情感评分。词典构建可以使用已有的中文情感词典,如中文情感词典、知网情感词典,或自行构建。对微博内容进行分词后,使用情感词典进行匹配,计算每条微博的情感分数。通过对情感词的频率和强度进行加权,得到整体情感评分。此方法快速识别用户对特定事件的主观评价。
支持向量机(SVM)是一种强大的监督学习算法,广泛应用于分类和回归分析。它的基本思想是通过寻找最佳的超平面,将不同类别的数据点分开,从而实现分类。对于线性可分的数据,SVM通过引入支持向量的概念,识别出距离决策边界最近的样本点,这些样本点称为支持向量。决策边界的选择基于这些支持向量,使得模型在分类时更为稳健。当数据不是线性可分时,SVM采用核函数技术,将数据映射到更高维的特征空间,从而使得在高维空间中实现线性可分。这些核函数包括线性核、多项式核和径向基函数核(RBF),用户可以根据具体问题选择适合的核函数。通过对已经标注的微博数据进行训练,SVM可以学习到情感分类的特征,并有效地对新的微博内容进行分类。在处理具有复杂特征的数据时,支持向量机能够提供良好的分类性能。
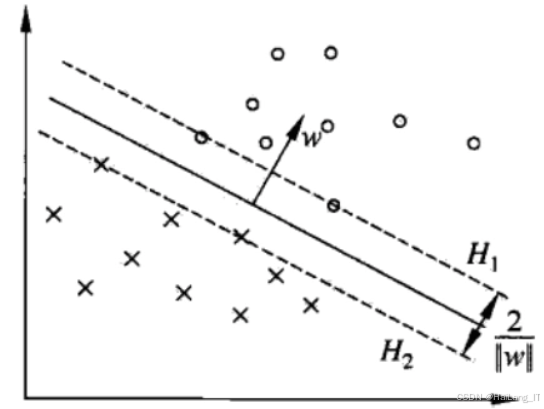
BERT模型是基于Transformer的预训练模型,具有强大的自然语言处理能力。在微博舆情分析中,使用BERT进行情感分析可以提升分析的准确性和鲁棒性。BERT模型在大规模文本数据上进行预训练,学习到丰富的语言表示。针对特定情感分析任务,使用标注好的微博数据集对BERT模型进行微调。添加分类层,将BERT的输出映射到情感类别。经过微调的BERT模型可以用于对新获取的微博文本进行情感预测,输出情感类别的概率分布。
将情感词典、支持向量机和BERT结合使用,可以充分发挥各自的优势,提高微博舆情动态分析的效果。首先通过情感词典进行初步情感评分,快速识别用户情绪。然后利用支持向量机对微博进行分类,检测情感类别。最后使用BERT模型进行深度分析,获取更精准的情感倾向。分析结果通过可视化工具展示,形成情感趋势图、主题词云等,帮助决策者直观理解舆情动态。系统实现对微博舆情的实时监测与动态分析,及时反馈公众情绪。
1.2 主题建模
LDA模型是一种广泛使用的主题建模算法,旨在从文本数据中识别出潜在的主题结构。LDA模型假设每篇文档由多个主题组成,每个主题又由多个词汇构成。LDA不仅关注单一文档的内容,还考虑了文档之间的相似性和词汇的分布。通过观察文档中出现的词汇,推断出这些词汇所代表的主题。。对于每篇文档,LDA首先为文档选择一个主题分布,然后根据这个主题分布生成该文档中的词汇。LDA通过引入狄利克雷分布和多项分布,为每个文档生成主题分布,并为每个主题生成词汇分布。经过多次迭代优化,LDA可以有效地揭示文档的主题结构,并为每个主题分配相应的词汇概率。

使用LDA模型进行主题建模的步骤通常包括数据预处理、模型训练和主题提取。数据预处理阶段需要对微博内容进行清洗,包括去除停用词、标点符号和无关信息,对文本进行分词处理。将处理后的文本数据转换为词袋模型或词频-逆文档频率表示,以建立文档-词矩阵。在模型训练阶段,选择合适的主题数量K,并使用LDA算法对文档-词矩阵进行训练。通过设定迭代次数和收敛条件,LDA将逐步优化主题分布和词汇分布,最终得到每篇文档的主题分布以及每个主题的词汇概率。训练完成后,可以通过查看主题词汇及其权重,提取出每个主题的主要话题。
通过LDA模型提取的主题可以为微博舆情分析提供重要的洞见。在分析某个特定事件的微博内容时,LDA能够帮助研究者识别出与该事件相关的主要话题。LDA可能会提取出主题,这些主题能够反映出舆论的主要关注点和情感倾向。通过对不同时间段内的微博数据进行LDA分析,可以观察到主题的变化趋势。
二、 数据集
2.1 数据集
选择合适的数据来源,主要包括微博平台的公开数据。可以使用微博的开放平台API获取相关数据,或者通过爬虫技术从微博网页中抓取信息。数据采集完成后,对原始数据进行去重,删除重复的微博内容。接着,清除无关信息,包括广告、链接、无意义的字符等。对文本进行分词处理,使用中文分词工具将微博内容切分为词汇。将处理后的文本数据转换为结构化格式,便于后续的分析和建模。数据标注是数据集制作的重要环节。根据研究目标,对微博内容进行情感标注,标记出每条微博的情感倾向,如积极、消极或中性。在标注完成后,将数据存储到数据库或文件中,确保数据的安全性和可访问性。
三、实验及结果分析
3.1 实验环境搭建

3.2 模型训练
经过数据采集后的微博文本需要进行清洗和整理,以确保后续分析的准确性。数据预处理的主要步骤包括去除重复内容、清洗无关信息、分词和去除停用词。分词是中文处理中的关键步骤,可以使用现有的分词工具,如结巴分词。通过这些步骤,原始数据被转化为可供模型使用的格式,从而提高模型训练的效果。
import pandas as pd
import jieba
# 读取微博数据
data = pd.read_csv('weibo_data.csv')
# 去重
data.drop_duplicates(subset=['content'], inplace=True)
# 分词和去停用词
stop_words = set(line.strip() for line in open('stopwords.txt', encoding='utf-8'))
data['content'] = data['content'].apply(lambda x: ' '.join([word for word in jieba.cut(x) if word not in stop_words]))
# 保存处理后的数据
data.to_csv('cleaned_weibo_data.csv', index=False)常用的方法包括词袋模型和TF-IDF(词频-逆文档频率)。词袋模型将每个文档表示为词汇表中的词频向量,而TF-IDF则考虑了词汇在整个数据集中的重要性。通过这些方法,可以将清洗后的文本数据转化为特征矩阵,供模型进行训练。选择合适的机器学习模型进行训练通过将特征矩阵和已标注的情感标签输入模型进行训练。训练过程中,可以使用交叉验证来评估模型的性能,并根据评估结果进行参数调整,优化模型效果。
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report
# 读取情感标签
labels = cleaned_data['label']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)
# 创建支持向量机模型并训练
model = SVC(kernel='linear')
model.fit(X_train, y_train)
# 预测测试集并评估模型
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))通过使用测试集对模型进行评估,计算准确率、精准率、召回率和F1-score等指标,可以获得模型的整体表现。根据评估结果,可以对模型进行优化,例如通过调整超参数、选择不同的特征提取方法或引入更多的数据进行训练,从而提升模型的效果。
from sklearn.model_selection import GridSearchCV
# 定义参数范围进行调优
param_grid = {'C': [0.1, 1, 10], 'gamma': [0.01, 0.1, 1]}
grid_search = GridSearchCV(SVC(), param_grid, cv=5, scoring='f1')
# 在训练集上进行超参数调优
grid_search.fit(X_train, y_train)
# 输出最佳参数和最佳得分
print("最佳参数:", grid_search.best_params_)
print("最佳得分:", grid_search.best_score_)海浪学长项目示例:



最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 2106
2106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









