







概要
Mysql的日志文件中有一个叫slow.log的日志文件,里面记录着我们历史出现的慢查询语句,格式为统一的日志记录。当我们需要进行日志分析的时候,大部分会登录机器进行grep语句然后并用肉眼检索,或者直接cat这个文件进行人工全量的搜索。这样效率是很慢的,然后如果我们想用做一些自动化工具进行慢日志分析,也不适合再用shell语句进行grep,这种情况下我们就需要用python进行写一个脚本来筛选出符合条件的慢日志记录。
一、整体架构流程
脚本工具就谈不架构一说了,就是在文件夹下包括slow.log文件,sqlquery.py的两个文件,其中slow.log是捞出来的日志文件,py文件是我们实现检索功能py文件。
二、技术名词解释
- timestamp 时间戳
- key 关键字
三、代码思路
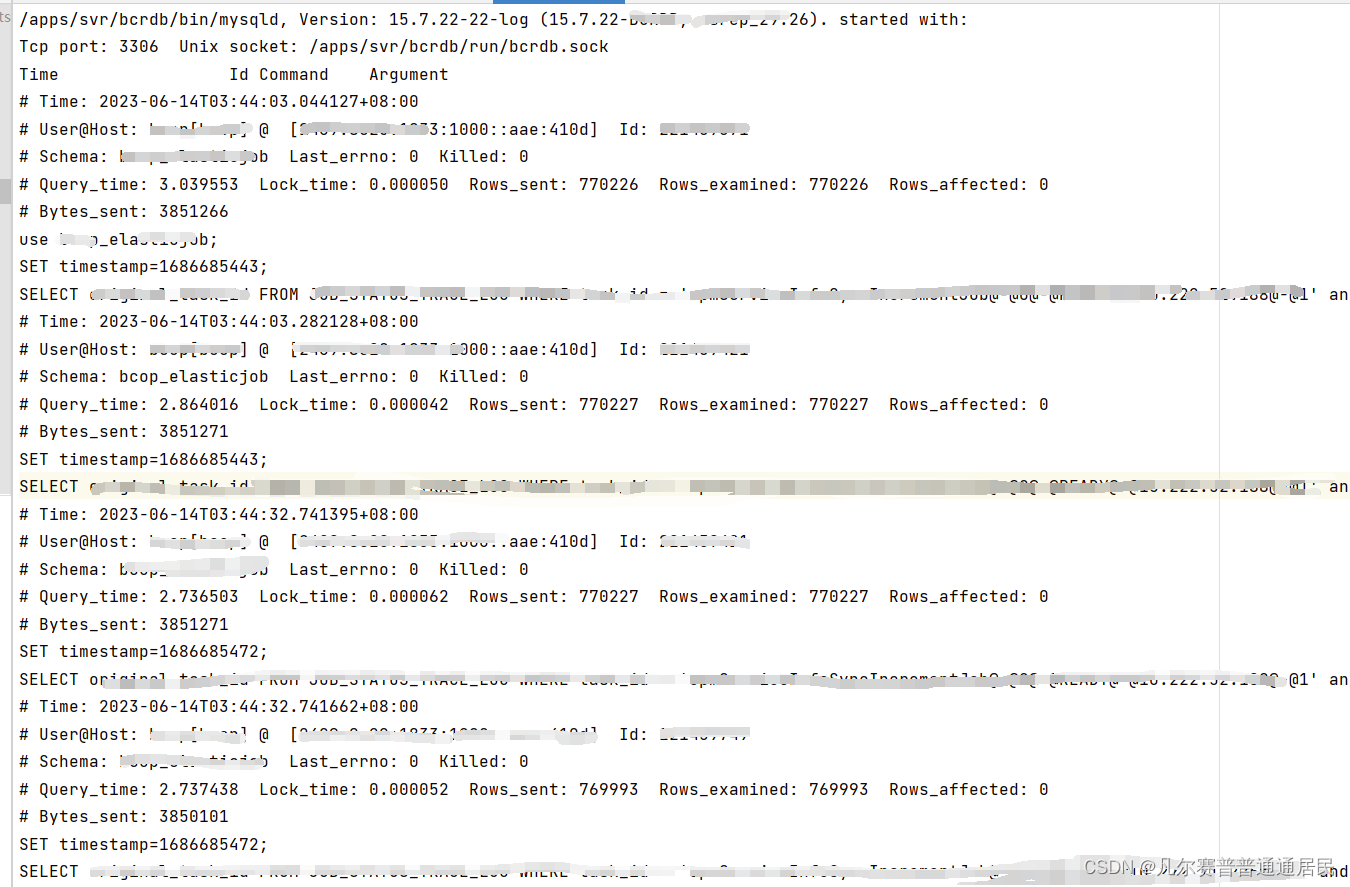
下图是slow日志里的内容,可以看到是按每次查询来记录的,每条查询包含了很多属性,如time、user、query_time、查询内容等。我们在使用这个slow日志的时候,一般都是先捞取一定时间段的内容,所以time这个字段很关键,其他属性可以自己按需所加,从按time筛选捞出来的数据进一步筛选,比如还需要符合query_time大于0.1的记录。
因此,我们代码的思路就是:
- 让用户输入一个开始时间starttime跟结束时间endtime,然后输入一些其他筛选条件。
- 读取日志文件,开始截取start跟end时间段内的日志,将结果暂存以备后面进行筛选
- 继续筛选其他条件,比如quertime大于一定的值。
- 一直筛选到所有条件都结束,输出结果
四、代码细节
import time
class GetLog:
query=1
print("提取慢日志")
key1 = '2023-06-14 03:44'.replace(' ','T')
key2 = '2023-06-14 03:46'.replace(' ', 'T')
timearray = time.strptime('2023-06-14 03:44', "%Y-%m-%d %H:%M")
s_timestamp=int(time.mktime(timearray))
timearray = time.strptime('2023-06-14 03:46', "%Y-%m-%d %H:%M")
e_timestamp=int(time.mktime(timearray))
with open("slow1.log", encoding="utf-8") as f:
lineind = []
result=f.read()
start_len = 0
startind=[]
while True:
num = result.find(key1, start_len)
if num == -1: # 找不到则返回-1
break
start_len = num + 1
startind.append(num)
endind=[]
while True:
num = result.find(key2, start_len)
if num == -1: # 找不到则返回-1
endind.append(result.find('Time', start_len))
break
start_len = num + 1
endind.append(num)
print()
# 根据正则将匹配到多行数据组成一行日志。
temlog=result[startind[0] - 8:endind[-1] - 8].split('\n')
for i,line in enumerate(temlog):
if "Time:" in line and int(time.mktime(time.strptime(line.split(' ')[2].split('.')[0], "%Y-%m-%dT%H:%M:%S")))>s_timestamp:
if int(time.mktime(time.strptime(line.split(' ')[2].split('.')[0], "%Y-%m-%dT%H:%M:%S")))<e_timestamp:
lineind.append(i)
else:
lineind.append(i)
break
else:
continue
for i in lineind:
if float(temlog[i+3].split()[2]) < float(query):
lineind.remove(i)
if lineind:
for i in temlog[lineind[0]:lineind[-1]]:
print(i)
print(lineind)
print(len(lineind))
if __name__ == '__main__':
a = GetLog()
五、小结
以上代码就是用python的一些基础函数进行slow日志中符合一定条件的筛选,通过筛选可以快速的找到日志中的相应记录,以备进一步分析使用。
















 763
763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











