









问题描述
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
示例 1:
输入: s = “anagram”, t = “nagaram”
输出: true
示例 2:
输入: s = “rat”, t = “car”
输出: false
说明:
你可以假设字符串只包含小写字母。
进阶:
如果输入字符串包含 unicode 字符怎么办?你能否调整你的解法来应对这种情况?
分析和实现
统计法
可以使用额外的空间进行字符串的统计,对于第一个字符串,统计各个字符出现的次数;对于第二个字符串,和统计结果进行比较即可。
对于统计的方法,可以使用 Map 和数组,因为字符集合只有 26 个,所以使用这两种是很自然也很方便的。
具体实现如下:
// Map
class Solution {
public boolean isAnagram(String s, String t) {
if(s.length() != t.length()){
return false;
}
Map<Character, Integer> sMap = new HashMap<>();
for (int i = 0; i < s.length(); i++) {
Character sTemp = s.charAt(i);
if (sMap.containsKey(sTemp)) {
sMap.put(sTemp, sMap.get(sTemp) + 1);
} else {
sMap.put(sTemp, 1);
}
}
for (int i = 0; i < t.length(); i++) {
Character tTemp = t.charAt(i);
if (sMap.containsKey(tTemp)) {
if (sMap.get(tTemp) - 1 == 0) {
sMap.remove(tTemp);
} else {
sMap.put(tTemp, sMap.get(tTemp) - 1);
}
}else{
return false;
}
}
return true;
}
}
效果:时间 17% 空间 23%

// 数组
class Solution {
public boolean isAnagram(String s, String t) {
if(s.length() != t.length()){
return false;
}
int[] temp = new int[26];
for (int i = 0; i < s.length(); i++) {
Character sTemp = s.charAt(i);
temp[sTemp-'a']++;
}
for (int i = 0; i < t.length(); i++) {
Character tTemp = t.charAt(i);
if (temp[tTemp-'a'] > 0) {
temp[tTemp-'a'] --;
}else{
return false;
}
}
return true;
}
}
效果:时间 30% 空间 89%
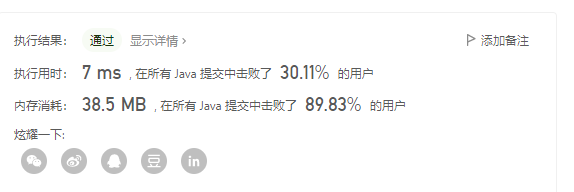
相较于第一种解法,在时间提升不算高,空间上还是很好的。















 1072
1072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









