







进阶篇—DQN的改良
代码参见我的GitHub
DDQN
也叫 Double DQN。之前我们提到的DQN方法目标Q值是通过贪婪法直接得到的,虽然使用max虽然可以快速让Q值向可能的优化目标靠拢,但是很容易过犹不及,导致过度估计。为了解决这个问题, DDQN通过解耦目标Q值动作的选择和目标Q值的计算这两步,来达到消除过度估计的问题。
简单来说,就是通过多增加一个网络来降低迭代过程中Q网络的关联性,其余步骤和传统DQN方法基本没有区别。
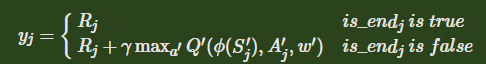

Prioritized Replay DQN
之前的DQN方法中,我们在replay buffer中进行随机采样,这意味着无论经验好坏新旧,对于这些经验我们一视同仁。但是在经验回放池里面的不同的样本由于TD误差的不同,对我们反向传播的作用是不一样的。TD误差越大,那么对我们反向传播的作用越大。而TD误差小的样本,由于TD误差小,对反向梯度的计算影响不大。在Q网络中,TD误差就是目标Q网络计算的目标Q值和当前Q网络计算的Q值之间的差距。如果我们总是能采样到TD误差较大的样本,那么我们的网络收敛速度不就可以更快了嘛。
Prioritized Replay DQN根据每个样本的TD误差绝对值,给定该样本的优先级。因此,损失函数多了一个系数
w
j
w_j
wj
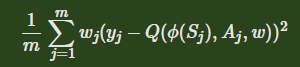
其中
w
j
w_j
wj计算方法如下
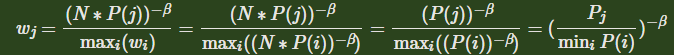
class NaivePrioritizedBuffer(object):
def __init__(self, capacity, prob_alpha=0.6):
...
def push(self, state, action, reward, next_state, done):
...
def sample(self, batch_size, beta=0.4):
if len(self.buffer) == self.capacity:
prios = self.priorities
else:
prios = self.priorities[:self.pos]
probs = prios ** self.prob_alpha
probs /= probs.sum()
indices = np.random.choice(len(self.buffer), batch_size, p=probs)
samples = [self.buffer[idx] for idx in indices]
#权重的计算部分
total = len(self.buffer)
weights = (total * probs[indices]) ** (-beta)
weights /= weights.max()
weights = np.array(weights, dtype=np.float32)
batch = zip(*samples)
states = np.concatenate(batch[0])
actions = batch[1]
rewards = batch[2]
next_states = np.concatenate(batch[3])
dones = batch[4]
return states, actions, rewards, next_states, dones, indices, weights
def update_priorities(self, batch_indices, batch_priorities):
...
def __len__(self):
...
Dueling-DQN
DDQN优化目标Q值,Prioritized Replay DQN优化replay buffer, 而Dueling DQN中,则是尝试通过优化神经网络的结构来优化算法
思路很简单,将原来的Q函数拆分为两部分----价值函数
V
(
S
,
w
,
α
)
V(S,w, \alpha)
V(S,w,α)和优势函数
A
(
S
,
A
,
w
,
β
)
A(S,A,w, \beta)
A(S,A,w,β)其中
w
w
w是公共部分的网络参数,而
α
\alpha
α是价值函数独有部分的网络参数,而
β
\beta
β是优势函数独有部分的网络参数。
需要改动的代码也很少
class DuelingDQN(nn.Module):
def __init__(self, observation_space, action_sapce):
super(DuelingDQN, self).__init__()
self.observation_space = observation_space
self.action_sapce = action_sapce
#######################改动部分#############################
self.feature = nn.Sequential(
nn.Linear(observation_space,128),
nn.ReLU()
)
self.advantage = nn.Sequential(
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, action_sapce),
)
self.value = nn.Sequential(
nn.Linear(128,128),
nn.ReLU(),
nn.Linear(128,1),
)
def forward(self, x):
...
def act(self, state, epsilon):
...
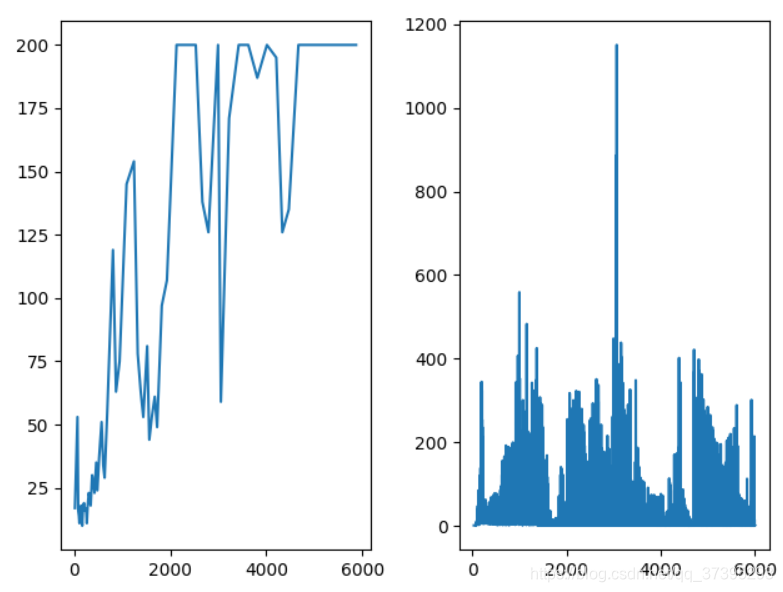
可以看到,效果好了很多
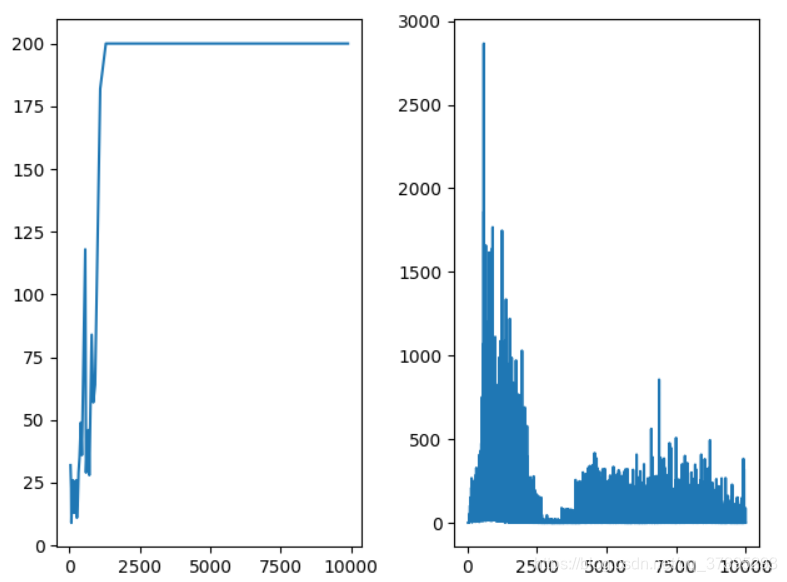
D3QN
Dueling DQN 与Double DQN相互兼容,一起用效果很好。简单,泛用,没有使用禁忌。任何一个刚入门的人都能独立地在前两种算法的基础上改出D3QN。
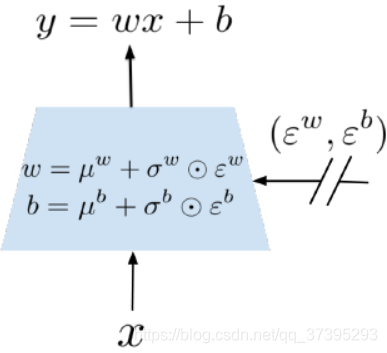
NoisyNet
一种将参数化的噪音加入到神经网络权重上去的方法来增加强化学习中的探索,称为 NoisyNet
噪音的参数可以通过梯度来进行学习,非常容易就能实现,而且只增加了一点计算量,在 A3C ,DQN 算法上效果不错。其思想很简单,就是在神经网络的权重上增加一些噪音来起到探索的目的。
Rainbow DQN
各种DQNtrick的集大成者


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









