







https://blog.csdn.net/weiqifa0/article/details/118917820
大家好,我是你们的工具人老吴。
今天,和大家分享一下几个 Linux 内核的调试小技巧。
当你遇到一个 bug,你调试了 1 年半载都解决不了,这其实一件好事。
因为它会时刻提醒你平时写代码时要谨慎、要多看书、多去认识一些更资深的人,别问我为什么会有这样的感受,因为是亲身经历~
掌握一个调试工具是需要学习成本的,这里只是列举我自己会用到的工具,如果有某个你觉得特别牛逼的工具而我没提到的话,请原谅我。
好,下面开始正文。
最重要的是:思路
调试 bug 时不要急着做实验,先梳理一下思路。
一般可以总结成如下步骤:
1、理解问题;
2、重现问题;
3、定位问题,找到相关的代码;
4、尝试修复问题;
5、如果失败,回到第 1 步;
bug 一般分为这几类:
1、Crash,最常遇到的,可能是因为我是做设备驱动开发的缘故;
2、Lockup,比较少,这类问题预防比事后调试更重要;
3、Logic/implementation error,这个也比较容易遇到,一般是运行不报错,但是运行的结果不符合预期;
4、Resource leak,偶尔会遇到;
5、Performance,偶尔会遇到,对于做驱动开发的话,一般是先考虑功能,当性能达不到要求时,再考虑优化性能。
调试工具的类别:
1、很多人不知道,调试最重要的工具是:我们的大脑。换句话说,也就是我们对内核个子系统、驱动开发的理解;
2、Logs and dump analysis。内核很贴心,许多异常发生时都会有一堆的 Kernel Panic 的信息,经常能让我们直接定位到引起异常的代码;
3、Tracing/profiling。这类工具一般能让我们理解程序的运行流程,不仅适合用来调试问题,也适合用来学习和理解内核的各种功能实现。
4、Interactive debugging。主要就是 gdb,我个人用得很少。
5、Debugging frameworks。许多的调试工具经过不断地发展和完善后,就慢慢地形成了一整套的调试框架,例如 Ftrace、SystemTap。
下面是几个我常用的调试技巧 / 工具。
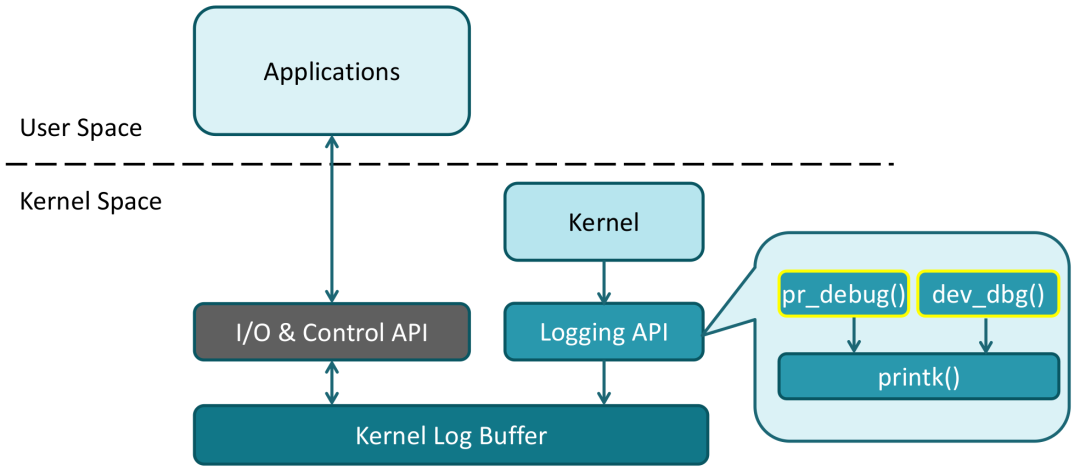
最常用的方法:打印
点击查看大图
关于打印的工具,主要是这 3 种:
1、printk()
最原始的打印 api,可以用但是主流观点已经不推荐使用了。
与之相关的是启动参数 loglevel,它决定了可以被打印出来的信息的最低优先级。
2、pr_*()
推荐用 pr_*() 来代替 printk(),这是一个函数族:
pr_emerg(), pr_alert(), pr_crit(), pr_err(), pr_warning(), pr_notice(), pr_info(), pr_cont(), pr_debug()
例如:
pr_info("Booting CPU %d\n", cpu);
内核会打印:
[ 202.350064] Booting CPU 1
3、dev_*()
同样是一个函数族:
dev_emerg(), dev_alert(), dev_crit(), dev_err(), dev_warn(), dev_notice(), dev_info(), dev_dbg()
它们的最大特点是需要传入一个 struct device 的参数,并且会打印出这个 device 的名字,一边是在驱动相关的代码里使用。
例如:
dev_info(&pdev->dev, "in probe\n");
内核会打印:
[ 25.878382] serial 48024000.serial: in probe
关于 pr_debug() and dev_dbg()
要使用这两个 api,需要在对应的代码里 #deinfe DEBUG。
当内核使能了 CONFIG_DYNAMIC_DEBUG,我们就可以通过 /sys/kernel/debug/dynamic_debug/control 动态地是否要打印 log,以及打印哪些 log。
使用方法,大致如下:
-
$ mount -t debugfs none /sys/kernel/debug/ -
$ cd /sys/kernel/debug/dynamic_debug/ -
$ echo “file xxx.c +p” > control -
$ echo “file svcsock.c line 1603 +p” > control -
$ echo “file drivers/usb/core/* +p” > control -
$ echo “file xxx.c -p” > control
具体地,可以参考:
https://training.ti.com/sites/default/files/docs/Kernel-Debug-Series-Part4-dynamic-debug.pdf
分析 Kernel Panic 的 信息
举个例子,下面是一次 Kernel Panic:
-
$ cat /sys/class/gpio/gpio504/value -
[23.688107] Unable to handle kernel NULL pointer dereference at virtual address 00000000 -
[23.696431] pgd = (ptrval) -
[23.699167] [00000000] *pgd=28bd4831, *pte=00000000, *ppte=00000000 -
[23.705596] Internal error: Oops: 17 [#1] SMP ARM -
[23.710316] Modules linked in: -
[23.713394] CPU: 1 PID: 177 Comm: cat Not tainted 4.19.17 #8 -
[23.719060] Hardware name: Freescale i.MX6 Quad/DualLite (Device Tree) -
[23.725606] PC is at mcp23sxx_spi_read+0x34/0x84 -
[23.730241] LR is at _regmap_raw_read+0xfc/0x384 -
[23.734866] pc : [<c0539c44>] -
lr : [<c067d894>] -
psr: 60040013 -
[23.741142] sp : d8c6da48 ip : 00000009 fp : d8c6da6c -
[23.746375] r10: 00000040 r9 : d8a94000 r8 : d8c6db30 -
[23.751608] r7 : c12ed9d4 r6 : 00000001 r5 : c0539c10 r4 : c1208988 -
[23.758145] r3 : d8789f41 r2 : 2afb07c1 r1 : d8789f40 r0 : 00000000 -
[...] // 省略
关键信息:
-
PC is at mcp23sxx_spi_read+0x34
-
pc : [<c0539c44>]
PC 是当前执行的指令的地址。
接下来,我们可以借助 addr2line, 定位到具体是哪一行代码引起了panic:
-
$ arm-linux-addr2line -f -e vmlinux 0xc0539c44 -
mcp23sxx_spi_read -
/home/sprado/elce/linux/drivers/pinctrl/pinctrl-mcp23s08.c:357
另外,还可以用 gdb 来定位代码:
-
$ arm-linux-gdb vmlinux -
(gdb) list *(mcp23sxx_spi_read+0x34) -
0xc0539c44 is in mcp23sxx_spi_read (drivers/pinctrl/pinctrl-mcp23s08.c:357)
earlyprintk
earlyprintk 一般用来处理一些发生在启动初期时的异常。
最常见的现象就是系统打印完 Starting Kernel... 后就 hang 住了。
用法:
1、配置内核:
-
CONFIG_EARLY_PRINTK -
CONFIG_DEBUG_LL
2、设置启动参数,类似:
root=/dev/mmcblk0p2 rootwait rw earlyprintk console=ttyS0,115200
WARN_ON()
这个函数可以打印出当前的函数调用栈。
我一般会在高度可疑的地方使用它。
举个例子:
-
static int sun6i_spi_probe(struct platform_device *pdev) -
{ -
struct spi_master *master; -
struct sun6i_spi *sspi; -
[...] -
// 用于调试 -
WARN_ON(1); -
master = spi_alloc_master(&pdev->dev, sizeof(struct sun6i_spi)); -
[...]
当运行到 WARN_ON(1) 时,内核会打印:
-
[ 1.847018] WARNING: CPU: 1 PID: 1 at drivers/spi/spi-sun6i.c:549 sun6i_spi_probe+0x20/0x3ac -
[ 1.855454] Modules linked in: -
[ 1.858525] CPU: 1 PID: 1 Comm: swapper/0 Not tainted 4.14.111 #196 -
[ 1.864781] Hardware name: sun8i -
[ 1.868032] [<c02287fc>] (unwind_backtrace) from [<c0225398>] (show_stack+0x10/0x14) -
[ 1.875776] [<c0225398>] (show_stack) from [<c0a1ba3c>] (dump_stack+0x94/0xa8) -
[ 1.882997] [<c0a1ba3c>] (dump_stack) from [<c0240c24>] (__warn+0xe8/0x100) -
[ 1.889953] [<c0240c24>] (__warn) from [<c0240cec>] (warn_slowpath_null+0x20/0x28) -
[ 1.897517] [<c0240cec>] (warn_slowpath_null) from [<c06a03c0>] (sun6i_spi_probe+0x20/0x3ac) -
[ 1.905953] [<c06a03c0>] (sun6i_spi_probe) from [<c0617980>] (platform_drv_probe+0x4c/0xb0) -
[ 1.914299] [<c0617980>] (platform_drv_probe) from [<c06160dc>] (driver_probe_device+0x234/0x2f0) -
[ 1.923162] [<c06160dc>] (driver_probe_device) from [<c0616244>] (__driver_attach+0xac/0xb0) -
[ 1.931592] [<c0616244>] (__driver_attach) from [<c06144ec>] (bus_for_each_dev+0x68/0x9c) -
[ 1.939762] [<c06144ec>] (bus_for_each_dev) from [<c0615654>] (bus_add_driver+0x198/0x210) -
[ 1.948020] [<c0615654>] (bus_add_driver) from [<c0616aec>] (driver_register+0x78/0xf8) -
[ 1.956017] [<c0616aec>] (driver_register) from [<c0201a70>] (do_one_initcall+0x40/0x16c) -
[ 1.964193] [<c0201a70>] (do_one_initcall) from [<c1000e6c>] (kernel_init_freeable+0x1c8/0x264) -
[ 1.972884] [<c1000e6c>] (kernel_init_freeable) from [<c0a2ef4c>] (kernel_init+0x8/0x114) -
[ 1.981054] [<c0a2ef4c>] (kernel_init) from [<c0222058>] (ret_from_fork+0x14/0x3c) -
[ 1.988686] ---[ end trace dc4e090f55ad2de8 ]---
我们可以很清晰地看到 sun6i_spi_probe() 被调用的流程。
这个方法跑起来很简单,但是每次使用都得编译和更新内核,非常不方便,只适合轻度使用。
Pstore
如果发生 Kernel panic 时,我们并没有连接串口终端,那么这一次的崩溃信息就丢失了。
Pstore (persistent storage) 就可以用来处理这种情况。
当发生 Kernel painic 时,Pstore 会自动保存 oops 和 panic 的 log,并且在软重启后仍可以查看 log 信息。
默认情况下,log 是存储在 RAM 的某个保留区域中,但也可以使用存储设备,例如闪存。
用法:
1、配置内核:
-
CONFIG_PSTORE -
CONFIG_PSTORE_RAM
2、配置 dts,为 Pstore 预留一块内存,类似:
-
reserved-memory { -
#address-cells = <1>; -
#size-cells = <1>; -
ranges; -
ramoops: ramoops@0b000000 { -
compatible = "ramoops"; -
reg = <0x20000000 0x200000>; /* 2MB */ -
record-size = <0x4000>; /* 16kB */ -
console-size = <0x4000>; /* 16kB */ -
}; -
};
3、假设刚发生了一次 Panic,并且已经软重启:
-
$ mount -t pstore pstore /sys/fs/pstore/ -
$ ls /sys/fs/pstore/ -
dmesg-ramoops-0 -
dmesg-ramoops-1
通过上面这两个文件就可以看到内核的崩溃信息了。
内核文档:
Documentation/admin-guide/ramoops.rst
devmem2
这是一个命令行工具,它可以在用户空间去读写内存。
大多数情况,我是用它来读写寄存器,简单粗暴。
用法:
$ apt-get install devmem2
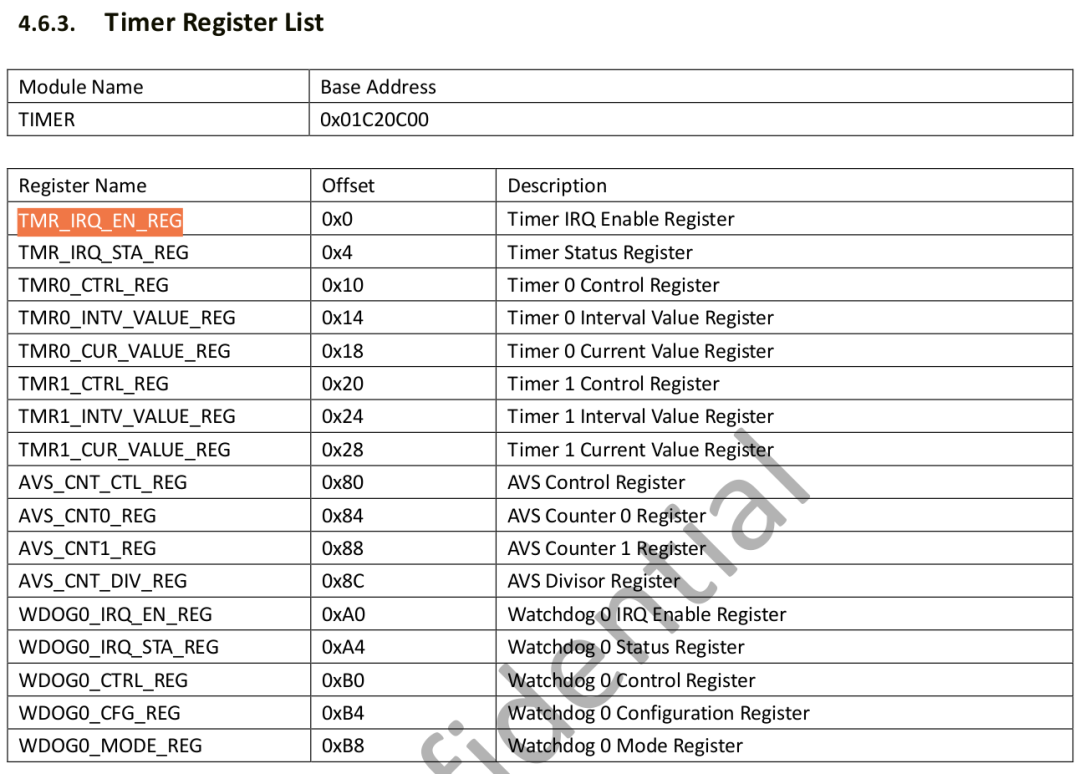
1、查看寄存器 TMR_IRQ_EN_REG:
-
$ devmem2 0x0x01C20C00 -
/dev/mem opened. -
Memory mapped at address 0xb6f38000. -
Value at address 0x0 (0xb6f38000): 0xEA000016
2、修改 TMR_IRQ_EN_REG:
-
# devmem2 0x0x01C20C00 w 0xEA000018 -
/dev/mem opened. -
Memory mapped at address 0xb6fe8000. -
Value at address 0x0 (0xb6fe8000): 0xEA000016 -
Written 0xEA000018; readback 0xEA000018
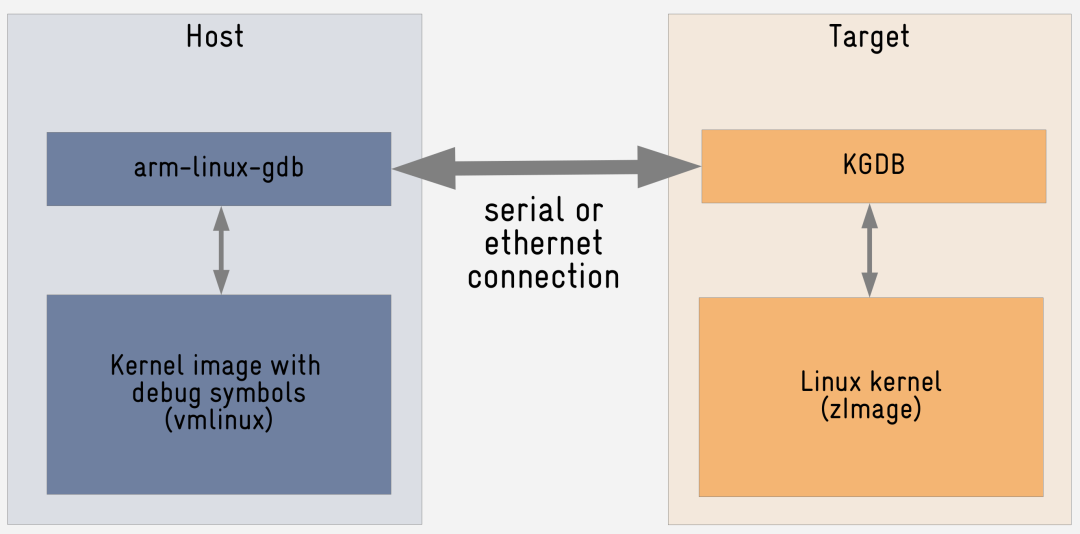
GDB
如果你想完全控制内核的运行,例如单步执行、查看变量等,可以用 GDB。
点击查看大图
这里采用的是 C/S 架构,在板子上运行 server (kgdb),在 PC 机上运行 client (gdb),通讯的方式可以是串口,或者网络,我一般是用串口。
如何配置:
1、配置内核:
-
CONFIG_KGDB -
CONFIG_KGDB_SERIAL_CONSOLE -
CONFIG_KGDB_KDB
2、设置启动参数:kgdoc
console=ttyS0,115200 kgdboc=ttyS0,115200 earlyprintk root=/dev/mmcblk0p2 oops=panic panic=0
ttyS0 是板子的调试串口。
要使用 kgdb,必须为其设置一个 I/O driver,我一般使用 kgdb over serial console (简称 kgdboc)
oops=panic panic=0 很重要。
另外,也通过在启动后设置 kgdboc:
echo ttyS0 > /sys/module/kgdboc/parameters/kgdboc
3、让内核进入 debug 模式:
-
$ echo g > /proc/sysrq-trigger -
[ 1958.025927] sysrq: SysRq : DEBUG -
[ 1958.029191] KGDB: Entering KGDB
4、让 PC 机连接板子
-
$ arm-linux-gdb vmlinux -
(gdb) set serial baud 115200 -
(gdb) target remote /dev/ttyUSB0 -
Remote debugging using /dev/ttyUSB0 -
0xc02c3540 in kgdb_breakpoint ()
举个例子:
配置好之后,通过 gdb 调试内核跟通过 gdb 调试应用的操作是一样的。
这里我举一个小例子。
首先,人为让内核 Crash:
-
$ echo WRITE_KERN > /sys/kernel/debug/provoke-crash/DIRECT -
Entering kdb (current=0xffffffc0de55f040, pid 1470) on processor 4 Oops: (null) -
due to oops @ 0xffffff80108bfa48 -
CPU: 4 PID: 1470 Comm: bash Not tainted 5.3.0-rc2+ #13 -
pc : __memcpy+0x48/0x180 -
lr : lkdtm_WRITE_KERN+0x4c/0x90 -
...
下面开始调试。
1、查看调用栈:
-
(gdb) bt -
Call trace: -
dump_backtrace+0x0/0x138 -
show_stack+0x20/0x2c -
kdb_show_stack+0x60/0x84 -
... -
do_mem_abort+0x4c/0xb4 -
el1_da+0x20/0x94 -
__memcpy+0x48/0x180 -
lkdtm_do_action+0x24/0x44 -
direct_entry+0x130/0x178
2、查看栈帧的内容:
-
(gdb) frame 1 -
#1 0xffffff801056584c in lkdtm_WRITE_KERN () at .../drivers/misc/lkdtm/perms.c:116 -
116 -
memcpy(ptr, (unsigned char *)do_nothing, size);
基本可以确定是使用 memcpy() 时导致 Crash。
3、查看相关代码:
-
(gdb) list -
112 size = (unsigned long)do_overwritten - (unsigned long)do_nothing; -
[...] -
116 memcpy(ptr, (unsigned char *)do_nothing, size);
需要核查一下 ptr、do_nothing、size,这 3 个参数是否合法。
4、打印变量值:
-
(gdb) print size -
$3 = 18446744073709551584 -
(gdb) print do_overwritten - do_nothing -
$4 = -32
最后发现 18446744073709551584 其实就是 (unsigned long) 的 -32。memcpy 的数据大小是 -32,导致了内核崩溃。
Ftrace
Ftrace 的作用是帮助开发人员了解 Linux 内核的运行时行为,以便进行故障调试或性能分析。
最早 Ftrace 是一个 function tracer,仅能够记录内核的函数调用流程。如今 ftrace 已经成为一个 framework,采用 plugin 的方式支持开发人员添加更多种类的 trace 功能。
用法:
-
$ mount -t tracefs none /sys/kernel/tracing -
$ cd /sys/kernel/tracing/ -
$ cat available_tracers -
hwlat blk mmiotrace function_graph wakeup_dl wakeup_rt wakeup function nop
跟踪器 tracer 表示的是要跟踪的目标。
假设我们抓一次 spi 传输的过程:
-
echo 0 > tracing_on -
echo function_graph > current_tracer -
echo *spi* > set_ftrace_filter -
echo *dma* >> set_ftrace_filter -
echo *spin* >> set_ftrace_notrace -
echo 1 > tracing_on -
./spidev_test -
echo 0 > tracing_on -
cat trace
得到的信息:
-
1) + 41.292 us | spidev_open(); -
1) | spidev_ioctl() { -
1) | spi_setup() { -
1) 0.417 us | __spi_validate_bits_per_word.isra.0(); -
1) | sunxi_spi_setup() { -
1) 0.834 us | sunxi_spi_check_cs(); -
1) 0.875 us | spi_set_cs(); -
1) 0.625 us | sunxi_spi_cs_control(); -
1) + 17.125 us | } -
1) 0.833 us | spi_set_cs(); -
1) + 30.458 us | } -
1) ! 699.875 us | } -
[...]
相关参考:
https://blog.csdn.net/Guet_Kite/article/details/101791125
Kdump
这个工具我没有用过,但是它似乎很强大,所以我觉得应该简单介绍一下。
kdump 是一种基于 kexec 系统调用 的内核崩溃转储机制。
当系统崩溃时,kdump 使用 kexec 启动进入到第二个内核 (dump-capture kernel),从而获得 coredump 信息。
用法:
1、设置启动参数:
crashkernel=64M
2、运行 kexec:
-
$ kexec --type zImage -p /boot/zImage \ -
--initrd=<initrd-for-dump-capture-kernel> \ -
--dtb=<dtb-for-dump-capture-kernel> \ -
--command-line="XXX"
运行完 kexec 后,dump-capture kernel 就被加载进内存了。
以后如果发生了 kernel panic,dump-capture kernel 会被加载并运行。
我们可以在 dump-capture kernel 下,获得 coredump 文件:
$ cp /proc/vmcore <dump-file>
然后就可以在 PC 上使用 gdb/crash 来调试分析了:
-
$ arm-linux-gdb path/to/vmlinux -c path/to//vmcore -
$ crash path/to/vmlinux path/to/vmcore
内核文档:
Documentation/kdump/kdump.txt
总结
预防为主,调试为辅。
软件开发没有银弹,同样的,bug 调试也没有银弹。但是多熟悉一些调试工具,是有好处的。
当然还有很多调试工具、技巧是我不知道了,欢迎大家分享给我。
Anyway, what we know is a drop, what we don't know is an ocean.
祝周末愉快。
—— The End ——















 2136
2136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









