









举例场景:爬取腾讯课堂中,查询python的所有课程的封面图、课程标题、课程数量、课程价格,这4个部分的内容。
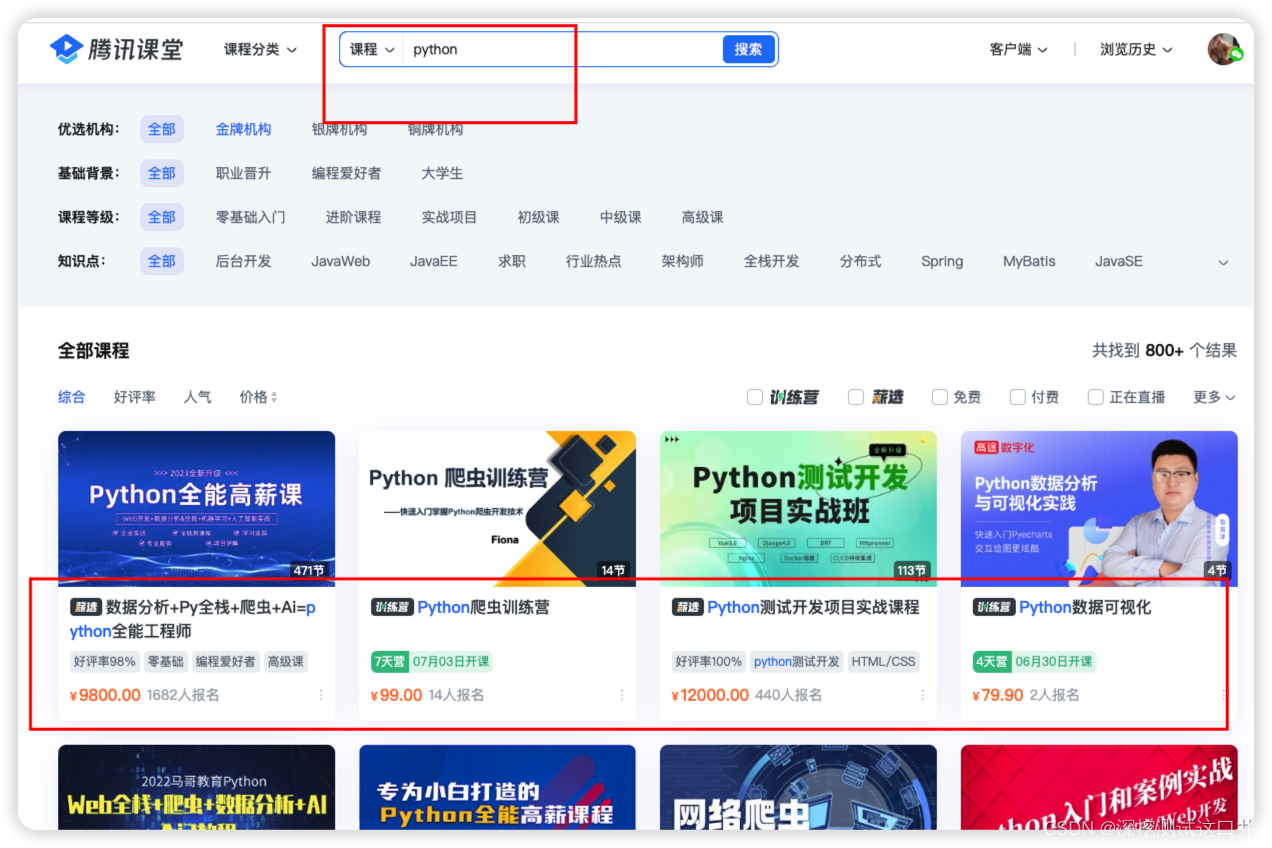
代码如下:
import requests
# import lxml # 导入用于请求的包lxml
from bs4 import BeautifulSoup # 导入用于请求的包bs4
from math import ceil # 向上取整
from pprint import pprint
BASE_URL = "https://ke.qq.com/course/list/python" # 腾讯课堂的网站,搜索python的第一个页面
def get_content(url:str):
"""对某一个url进行http请求,获取返回的文本"""
header = {'user-agent':"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"}
response = requests.get(url, headers=header)
response_text = response.content.decode("utf-8")
return response_text
def get_pages(one_page_num:int):
"""计算网页的总页数"""
content = get_content(BASE_URL)
# 实例化bs4对象
soup = BeautifulSoup(content, 'lxml')
# 找到页面上显示的总结果数
total_courses = int(soup.find('em', class_="result__count").text.replace("+", "")) # 去掉数字后面的+,例如,200+
# 计算中页数,向上取整
return ceil(total_courses/one_page_num)
def get_pages_url(pages:int):
"""拼接每一页的url"""
# 定义一个页面url存放的list
url_list = []
for page in range(1, pages+1):
url_list.append(BASE_URL + '?page=' + str(page))
return url_list
def get_info(url:str):
"""抓取某个页面的内容:封面图、课程标题、课程数量、课程价格"""
content = get_content(url) # 腾讯课堂的网站,搜索python,一页上抓取某些内容
# 实例化bs4对象
soup = BeautifulSoup(content, 'lxml')
# 第一次筛选
first_filter = soup.find_all('div', class_='course-list')[0] # 仅又一个值,注意class后面带有下划线_
# 第二次筛选
second_filter = first_filter.find_all('section', class_="course-card-expo-wrapper") # 一页中共有24个值
# print(len(second_filter))
# print(second_filter)
# 定一个集合,使用循环来遍历第二次抓取出的内容
page_info = []
for one in second_filter:
temp_dict = {}
# 抓取封面图片地址
img = one.find('div', class_="kc-course-card-cover").img.attrs['src']
# img = one.find('div', class_="kc-course-card-cover").find('img').attrs['src']
temp_dict["img"] = img
# 抓取课程title
title = one.find('div', class_="kc-course-card-content").h3.attrs['title']
temp_dict['title'] = title
# 抓取课程数量
try: # 有的课程没有展示课程数量,找不到对应的字段信息,因此添加一个异常捕获
course_num = one.find('div', class_="kc-course-card-cover-course-num---tapHtg").text
except AttributeError as e:
pprint(e)
temp_dict['course_num'] = "没有在展示出课程数量"
else:
temp_dict['course_num'] = course_num
# 抓取课程价格
price = one.find('span', class_="kc-course-card-price").text
temp_dict['price'] = price
# 添加到集合中
page_info.append(temp_dict)
return page_info
def get_all_info(urls:list):
"""抓取所有页面的内容"""
# 定义一个list存放所有页面上抓取到的内容
all_info = []
for url in urls:
# 抓取某一页的内容,extend在列表末尾扩展序列元素
all_info.extend(get_info(url))
return all_info
if __name__ == '__main__':
# 一页展示的数量
one_page_num = 24
# 计算总页数
pages = get_pages(one_page_num)
# 获取所有页的url
urls = get_pages_url(pages)
# 抓取所有页面的内容
results = get_all_info(urls)
# 打印抓取总课程数量
pprint(len(results))
# 循环打印出抓取的每门课程的课程数量
for one in results:
pprint(one['course_num'])















 3460
3460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









