






一、字符串
- 字符串一种特殊的顺序表,可以用数组或链表存储,一般用数组存储
- “good” 字符串长度为 4 但需要 5 个字节,最后一个为 ‘\0’
二、术语
- 字符串查找也叫模式匹配
- 比如在 T = “aaabbbccc” 字符串中查找 P = “bbb” 的字符串
- T 叫做目标串或主串,P 叫做模式串或子串
三、字符串查找算法
- 朴素的模式匹配算法
- KMP 算法
- BM 算法
1. 朴素的模式匹配算法
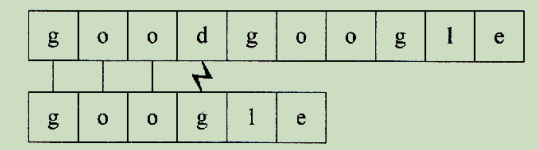
在 T = "goodgoogle" 字符串中查找 P = "google" 字符串的位置
-
从 T 第一个位置开始,T 与 P 前三个字符匹配成功,但第四个字符 ‘d’ 匹配失败
-
从 T 第二个位置开始,‘o’ 与 ‘g’ 不相等,失败

-
从 T 第三个位置开始,‘o’ 与 ‘g’ 不相等,失败

-
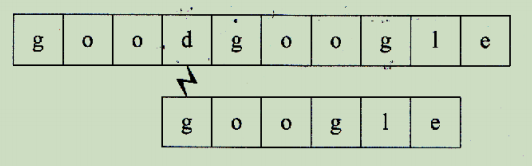
从 T 第四个位置开始,‘d’ 与 ‘g’ 不相等,失败
-
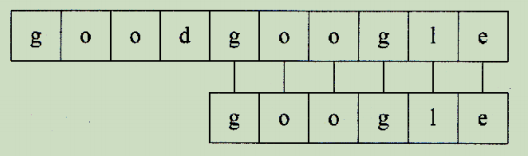
从 T 第五个位置开始,剩下字符全部匹配,成功
-
朴素的模式匹配算法时间复杂度分析:
假设目标串 T 长度为 n,模式串长度为 m,假设 T 中 存在 P- 最好情况:O(m) 如 “googlegood” 中查找 “google”
- 最坏情况:O((n - m + 1) * m) 如在 ‘‘000…0001’’ 中查找 “001”,每次不匹配发生在串 P 的最后一个字符处
- 平均情况:O(n + m) 每次不匹配发生在串 P 的首字母处,最好为 m, 最坏为 n,平均为 (n + m) / 2,为 O(n + m)
-
缺点:目标串 T 需要回溯,比如 “goodgoogle” 匹配 “google”
2. KMP 算法
- 目标串 T 一直向右前进,不会向左回溯,是精确的模式匹配算法
- 如何避免回溯?利用模式串 P 自身的重复模式
例1: 模式串 P 无重复模式

例2 模式串 P 有重复模式

当 T[i] ≠ P[j] 时,下一次该比较 T 和 P 的哪两个字符?




- 在 P 的第一个字符不匹配时,下一次匹配 T[i+1] 和 P[1],case2
- 若 P 成功匹配的子串没有重复模式,下一次匹配 T[i] 和 P[1],case1
- 若 P 成功匹配的子串有重复模式,下一次匹配 T[i] 和 P[ next[j] ],case3 case4
2.1 什么是 next 数组?
- next 数组表示下一次从 P 的第几个字符开始比较,P 下标从 1 开始,表示从第一个字符开始比较

- 把 T 串各个位置的 j 值的变化定义为一个数组 next,next 长度为 T 串的长度
- next[j] 定义
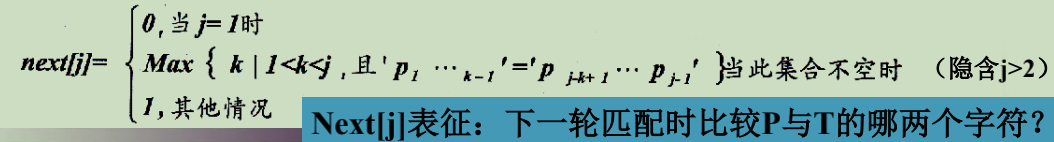
2.2 KMP 算法的主要思想
- 将模式串 P 的重复模式保存在 next 数组中,匹配失败时用 next 数组计算下一次 P 比较字符的位置
- 若 T[i] ≠ P[j] ,下一轮比较过程:
- 若 next[j] ≠ 0,匹配 T[i …] 与 P[ next[j] …]
- 若 next[j] = 0,匹配 T[i …] 与 P[1 …]
- 可见目标串 T 一直向右前进,不会向左回溯
2.3 计算 next 数组




2.4 next 数组应用


2.5 KMP 改进
- 若 T[i] ≠ P[j] 失配了,同时 P[j] = P[ next[j] ],此时右移 P 还是失配的,因为 T[i] ≠ P[ next[j] ]
- 使用 nextval 数组替代 next 数组
- nextval 计算规则:
nextval[1] = 0 for (j > 1; j <= n; j++) if P[j] == P[next[j]] then nextval[j] = nextval[next[j]] if P[j] != P[next[j]] then nextval[j] = next[j] 简单记忆:相同用自己的 nextval[next[j]],不同照写上面 next[j]
2.6 nextval 示例

2.7 nextval 应用

2.8 KMP 总结
- 时间复杂度为
O(n + m),O(n) 表示比较时间,O(m) 表示计算 next 数组时间 - 目标串不出现回溯
- 目标串每个字符比较 1-2 次
- 当
模式串有重复模式时,KMP 才比朴素模式匹配快,因为next 数组可以跳过一些字符 - 当每次失配发生在
模式串第一个字符时,KMP退化成朴素模式匹配
3. BM 算法
- 一种
精确的字符串匹配算法 - 模式串匹配方向:
从右到左,不同于 KMP 的从左到右 - 匹配过程:每次 T 与 P 右对齐,从右到左开始匹配,若发生失配,确定下一次 T 的开始位置并与 P 对其,重复该过程
- 关键是如何确定下一次 T 的开始位置,即目标串查找指针的移动距离,或者说目标串中指针
向右跳跃的距离 dist
3.1 辅助概念-坏字符和好后缀
- 失配时 T[i] ≠ P[j],此时
坏字符 x = T[i],好后缀 P’ = P[(k+1) … (len( P) - 1)],后缀即为已匹配的部分字符串 - 如何计算失配时,目标串查找指针
跳跃距离 dist[i]- 跳过字符(
坏字符规则)CharJump[x],根据坏字符 x 计算 T 中 dist[i] - 重复模式(
好后缀规则)MatchJump[k],根据 P 中失配位置 k 计算 dist[i]
- 跳过字符(
3.2 BM 算法思想

-
好后缀三种情况
-
好后缀 u 重复出现在 P

-
好后缀 u 部分出现在 P 中

-
好后缀 u 没有出现在 P 中

-
-
坏字符两种情况
-
坏字符 x 出现在模式串 P 中

-
坏字符 x 没有出现在 P 中

-
3.3 CharJump 数组
- 坏字符 x 出现在 P 中


- 坏字符 x 没有出现在 P 中


3.4 坏字符规则

- CharJump 计算


- 坏字符应用

未完待续。。。















 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









