









1.参数初始化
import argparse
from utils.line import Line
from tqdm import trange
import torch
import sys
import pickle
import numpy as np
from decimal import Decimal
# 使用parser加载信息
parser = argparse.ArgumentParser()
# 输入文件
parser.add_argument('-g','--graph_path',type = str,default = './data/weighted.karate.edgelist')
# 模型信息输出文件
parser.add_argument('-save','--save_path',type = str,default = './model.pt')
# 模型损失函数值输出文件
parser.add_argument('-lossdata','--lossdata_path',type = str,default = './loss.pkl')
# 论文中的1st order, 2nd order
parser.add_argument("-order", "--order", type=int, default=2)
# 负样本数量
parser.add_argument("-neg", "--negsamplesize", type=int, default=5)
# embedding维度
parser.add_argument("-dim", "--dimension", type=int, default=128)
# batch大小
parser.add_argument("-batchsize", "--batchsize", type=int, default=5)
# epoch数量
parser.add_argument("-epochs", "--epochs", type=int, default=1)
# 学习率设置
parser.add_argument("-lr", "--learning_rate", type=float,
default=0.025) # As starting value in paper
# 负采样指数设置
parser.add_argument("-negpow", "--negativepower", type=float, default=0.75)
args = parser.parse_args(args=[])
2.读图方法
import collections
from tqdm import tqdm
import random
# 读图函数
# 初始化字典
def makeDist(graphpath,power = 0.75):
edgedistdict = collections.defaultdict(int)
nodedistdict = collections.defaultdict(int)
weightsdict = collections.defaultdict(int)
nodedegrees = collections.defaultdict(int)
maxindex = 0
weight_sum = 0
negprobsum = 0
lines = open(graphpath,'r',encoding = 'utf-8')
for line in lines:
line = line.strip().split()
src,tgt,weight = [int(l) for l in line]
# print(src,tgt,weight)
# node_name&normal_weight
nodedistdict[src] += weight
# alia_name&normal_weight
edgedistdict[tuple([src,tgt])] = weight
# 原数据,不做处理
# alia_name&weight
weightsdict[tuple([src,tgt])] = weight
# node_name&num_input_degress
nodedegrees[src] += 1
if max(src,tgt) > maxindex:
maxindex = max(src,tgt)
weight_sum += weight
negprobsum += np.power(weight,power)
lines = open(graphpath,'r',encoding = 'utf-8')
for line in lines:
line = line.strip().split()
src,tgt,weight = [int(l) for l in line]
nodedistdict[src] = np.power(nodedistdict[src],power) / negprobsum
edgedistdict[tuple([src,tgt])] /= weight_sum
return edgedistdict,nodedistdict,weightsdict,nodedegrees,maxindex
edgedistdict,nodedistdict,weightsdict,nodedegrees,maxindex = makeDist(graphpath = args.graph_path,power = 0.75)
3.采样方法
import random
class VoseAlias(object):
def __init__(self,dist):
self.dist = dist
self.alias_initialisation()
def alias_initialisation(self):
n = len(self.dist)
self.table_prob = {}
self.table_alias = {}
scale_prob = {}
larger = []
smaller = []
# 以1为界限进行划分
for o,p in self.dist.items():
scale_prob[o] = p * n
if scale_prob[o] > 1:
larger.append(o)
else:
smaller.append(o)
while larger and smaller:
large = larger.pop()
small = smaller.pop()
self.table_prob[small] = scale_prob[small]
scale_prob[large] = scale_prob[large] - (1 - scale_prob[small])
self.table_alias[small] = large
if scale_prob[large] > 1:
larger.append(large)
else:
smaller.append(large)
while larger:
self.table_prob[larger.pop()] = 1
while smaller:
self.table_prob[smaller.pop()] = 1
self.listprobs = list(self.table_prob)
def alias_generation(self):
col = random.choice(self.listprobs)
if random.uniform(0,1) <= self.table_prob[col]:
return col
else:
return self.table_alias[col]
def sample_n(self,size):
for i in range(size):
yield self.alias_generation()
voseAlias = VoseAlias({'a':1/2,'b':1/3,'c':1/12,'d':1/12})
list(voseAlias.sample_n(5))
4.模型定义
核心公式:
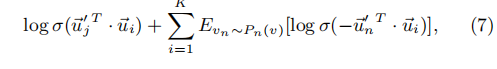
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class Line(nn.Module):
def __init__(self,size,embed_dim = 128,order = 1):
super(Line,self).__init__()
assert order in [1,2],'It is illegal!!'
self.order = order
self.embed_dim = embed_dim
self.node_embedding = nn.Embedding(size,embed_dim)
# 二阶相似度
if order == 2:
self.context_embedding = nn.Embedding(size,embed_dim)
self.context_embedding.weight.data = self.context_embedding.weight.data.uniform_(-0.5,0.5) / embed_dim
self.node_embedding.weight.data = self.node_embedding.weight.data.uniform_(-0.5,0.5) / embed_dim
def forward(self,v_i,v_j,neg_samples,device = 'cpu'):
v_i = self.node_embedding(v_i).to(device) # [batch_size,emb_dim]
if self.order == 1:
v_j = self.context_embedding(v_j).to(device)
neg_samples = -self.context_embedding(neg_samples).to(device) # [batch_size,num_neg,emb_dim]
else:
v_j = self.node_embedding(v_j).to(device)
neg_samples = -self.node_embedding(neg_samples).to(device) # [batch_size,num_neg,emb_dim]
formula_1 = F.logsigmoid(torch.sum(torch.mul(v_i,v_j),dim = 1)) # [batch_size,1]
formula_2_1 = torch.sum(torch.mul(v_i.unsqueeze(1),neg_samples),dim = 2) # [batch_size,num_neg]
formula_2 = torch.sum(F.logsigmoid(formula_2_1),dim = 1) # [batch_size,1]
loss = formula_1 + formula_2 # [batch_size,1]
return -torch.mean(loss)
#model = Line(28,order = 2)
#model(torch.ones(5).long(),torch.ones(5).long(),torch.ones(5,3).long())
def negSampleBatch(sourcenode,targetnode,negsamplesize,weights,nodedegrees,nodesaliassampler,t = 10e-3):
negsamples = 0
while negsamples < negsamplesize:
sample_node = list(nodesaliassampler.sample_n(1))[0]
# 与起点与终点不能一样
if sample_node == sourcenode or sample_node == targetnode:
continue
else:
negsamples += 1
yield sample_node
def makeData(samplededges,negsamplesize,weights,nodedegress,nodesaliassampler):
for src,tgt in samplededges:
yield [src,tgt] + list(negSampleBatch(src,tgt,negsamplesize,weights,nodedegrees,nodesaliassampler))
#voseAlias = VoseAlias({'a':0.3,'b':0.4,'c':0.1,'d':0.2})
#list(negSampleBatch('a','b',4,None,None,voseAlias))
#list(makeData([['a','b'],['c','d']],2,None,None,voseAlias))
5.读图、模型定义与采样数据初始化
edgedistdict, nodedistdict, weights, nodedegrees, maxindex = makeDist(
args.graph_path, args.negativepower)
edgesaliassampler = VoseAlias(edgedistdict)
nodesaliassampler = VoseAlias(nodedistdict)
line = Line(maxindex + 1,embed_dim = args.dimension,order = 2)
opt = optim.SGD(line.parameters(),lr = args.learning_rate,momentum = 0.9,nesterov=True)
6.模型训练
device = 'cpu'
helper = 0
print('start training......')
batchrange = int(len(edgedistdict) / args.batchsize)
losses = []
for epoch in range(10):
for t in range(batchrange):
sampleEdges = edgesaliassampler.sample_n(args.batchsize)
batch = torch.LongTensor(
list(
makeData(sampleEdges,args.negsamplesize,weights,nodedegrees,nodesaliassampler)
)
)
if helper == 0:
print(list(batch))
helper = 1
v_i = batch[:,0]
v_j = batch[:,1]
neg_samples = batch[:,2:]
loss = line(v_i,v_j,neg_samples)
# 开始优化
opt.zero_grad()
loss.backward()
opt.step()
losses.append(loss)
7.kmeans聚类效果
# k-means聚类
from sklearn import cluster
import pandas as pd
embedding_node = []
for i in range(1,35):
input_ = torch.LongTensor([i])
t = line.node_embedding(input_)
embedding_node.append(t.tolist()[0])
embedding_node = np.matrix(embedding_node).reshape((34,-1))
y_pred = cluster.KMeans(n_clusters = 5,random_state = 9).fit_predict(embedding_node)
import matplotlib.pyplot as plt
import networkx as nx
G = nx.Graph()
G.add_edges_from(list(edgedistdict.keys()))
change_preds = [y_pred[i-1] for i in list(G.nodes())]
nx.draw(G,with_labels = True,edge_color = 'b',node_color = change_preds)
















 1205
1205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









