







目录
1 目的和思想
LINE 模型的目的:将图的顶点表示为向量
LINE 的整体思想:不仅仅考虑一阶相似(直接相连的 node),同时考虑二阶相似(不直接相连的 node,但是邻居有较多公共 node)
模型出自论文: LINE: Large-scale Information Network Embedding
2 模型原理
模型实现(两个不同的模型):
第一个模型:First-order Proximity
第二个模型:Second-order Proximity
First-order Proximity:一阶相似,表示两个node直接连接,6和7
Second-order Proximity:二阶相似,表示两个node没有直接向量,但是他们的邻居有很多相同,5和6

2.1 First-order Proximity
仅能用于无向图

- 对于每个无向边(i,j),我们定义顶点
v
i
v_i
vi 和
v
j
v_j
vj 之间的联合概率
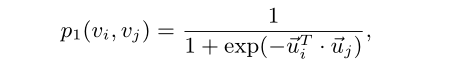
u i ∈ R d u_i ∈R^d ui∈Rd, u i u_i ui 是低维表示节点的向量 - 根据边的权重,分布之间的经验概率

- 简单的最小化的目标函数
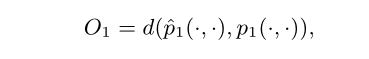
d ( ⋅ , ⋅ ) d(·,·) d(⋅,⋅) 表示两个分布之间的距离 - 利用 KL-散度 代替
d
(
⋅
,
⋅
)
d(·,·)
d(⋅,⋅) ,并省略一些常数,最终目标函数
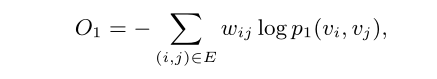
2.2 Second-order Proximity
适用于有向图和无向图,无向图可以认为是方向相反,权重相同的边

- 顶点可作为当前顶点或其他顶点的上下分布,有相似的上下分布的顶点是相似的
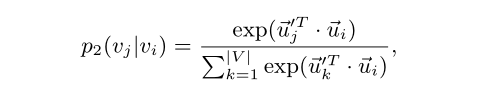
u i ⃗ \vec{u_i} ui 表示 v i v_i vi 被当作顶点,
u i ⃗ ′ \vec{u_i}^{'} ui′ 表示 v i v_i vi 被当作顶点的上下顶点
∣ V ∣ |V| ∣V∣ 表示上下顶点个数 - 经验分布

w i j w_{ij} wij 表示边权重
d i d_i di 表示顶点 i i i 的出度

N ( i ) N(i) N(i) 是 v i v_i vi 的出度集合 - 目标函数
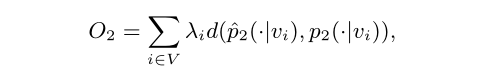
d ( ⋅ , ⋅ ) d(·,·) d(⋅,⋅) 表示两个分布之间的距离 - 同样利用 KL-散度 代替
d
(
⋅
,
⋅
)
d(·,·)
d(⋅,⋅) ,并省略一些常数,最终目标函数
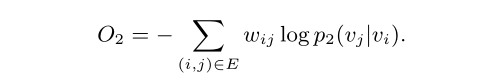
3 优化
对于目标函数,计算量大,采用负采样,得到新目标函数
4 LINE 相关知识
4.1 KL-散度
KL-散度 就是 相对熵
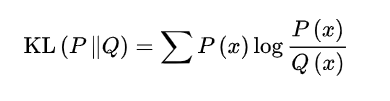
P代表真实分布,Q代表预测分布,当预测接近真实,散度就越小,则损失也就越小
5 LINE 总结
LINE 能够解决一阶相似和二阶相似,但是graph embedding需要两个模型的联合才能得到更好的效果














 1105
1105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









