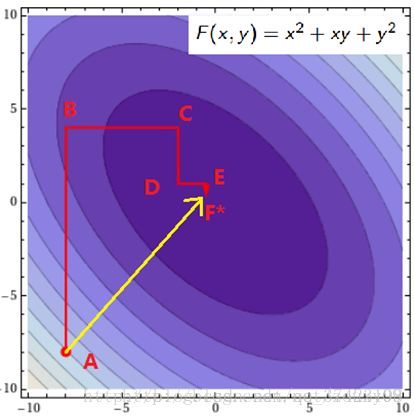
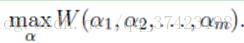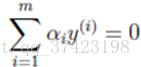SMO序列最小化优化算法 Sequential minimal optimization 优化目标是找到一组最优的αi*。一旦求出这些αi*,就很容易计算出权重向量w*和b,并得到分隔超平面了。 1.坐标下降法 求解下面问题 在这里需要求解m个变量 αi α i 一般来说是通过梯度下降(这里是求最大值,所以应该叫上升)等算法每一次迭代对所有m个变量αi也就是α向量进行一次性优化。通过误差每次迭代调整α向量中每个元素的值。而坐标上升法(坐标上升与坐标下降可以看做是一对,坐标上升是用来求解max最优化问题,坐标下降用于求min最优化问题)的思想是每次迭代只调整一个变量αi的值,其他变量的值在这次迭代中固定不变。 核心思想还是迭代 最里面语句的意思是固定除αi之外的所有αj(i不等于j),这时W可看作只是关于αi的函数,那么直接对αi求导优化即可。这里我们进行最大化求导的顺序i是从1到m,可以通过更改优化顺序来使W能够更快地增加并收敛。 2.坐标下降法示例 寻找函数 f(x,y)=x2+xy+y2 f ( x , y ) = x 2 + x y + y 2 的最小值处 (x∗,y∗) ( x ∗ , y ∗ ) (图是函数投影到xoy平面的等高线图,颜色越深值越小) 起始点A需要到达F,那最快的方法就是图中黄色线的路径,一次性就到达了,其实这个是牛顿优化法,但如果是高维的话,这个方法就不太高效了,如果是高维的情况,而且目标函数很复杂的话,再加上样本集很多,那么在梯度下降中,目标函数对所有αi求梯度或者在牛顿法中对矩阵求逆,都是很耗时的。 我们也可以按照红色所指示的路径来走。从A开始,先固定x,沿着y轴往让f(x, y)值减小的方向走到B点,然后固定y,沿着x轴往让f(x, y)值减小的方向走到C点,不断循环,直到到达F*。 3.SMO算法 一次迭代优化两个 α α 而不是一个 原因这个优化问题存在约束也就是 因此,我们需要一次选取两个参数做优化,比如αi和αj,此时αi可以由αj和其他参数表示出来。这样回代入W中,W就只是关于αj的函数了,这时候就可以只对αj进行优化了。在这里就是对αj进行求导,令导数为0就可以解出这个时候最优的αj了。然后也可以得到αi。这就是一次的迭代过程,一次迭代只调整两个拉格朗日乘子αi和αj。 算法步骤: 重复下面过程直到收敛{ (1)选择两个拉格朗日乘子αi和αj; (2)固定其他拉格朗日乘子αk(k不等于i和j),只对αi和αj优化w(α); (3)根据优化后的αi和αj,更新截距b的值 } 每次迭代都要选择最好的αi和αj,为了更快的收敛!那实践中每次迭代到底要怎样选αi和αj呢?采用启发式选择,主要思想是先选择最有可能需要优化(也就是违反KKT条件最严重)的αi,再针对这样的αi选择最有可能取得较大修正步长的αj。 4.凸优化问题终止条件: SMO算法的基本思路是:如果说有变量的解都满足此最优化问题的KKT条件,那么这个最优化问题的解就得到了。因为KKT条件是该最优化问题的充分必要条件(证明请参考文献)。所以我们可以监视原问题的KKT条件,所以所有的样本都满足KKT条件,那么就表示迭代结束了。但是由于KKT条件本身是比较苛刻的,所以也需要设定一个容忍值,即所有样本在容忍值范围内满足KKT条件则认为训练可以结束;








 本文介绍了SMO(Sequence Minimal Optimization)算法的基本原理及应用。重点讲述了坐标下降法在SMO算法中的实现方式,以及如何通过优化两个变量来进行快速迭代。此外还讨论了SMO算法在解决约束优化问题时的具体步骤。
本文介绍了SMO(Sequence Minimal Optimization)算法的基本原理及应用。重点讲述了坐标下降法在SMO算法中的实现方式,以及如何通过优化两个变量来进行快速迭代。此外还讨论了SMO算法在解决约束优化问题时的具体步骤。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言