







Kafka简介
Kafka(a distributed streaming platform )纠正一个观点,从本质上来讲并不是一种消息队列而是一种分布式流平台,在大数据里,常用来对接实时流处理平台(符合流平台的基本要求:高并发、低延时、高吞吐、高可靠),类似于消息中间,但不同于消息中间,(不同于消息中间:时序性、消息级分类等等区别);

类似于消息队列,可以用来处理大量数据状态下的消息队列,一般用来做日志的处理。Kafka拥有消息队列的相应的特性:
- 解耦合 如果是接口的方式客户端请求服务端,服务端再响应并返回消息,消息具有一定的延迟且不说,这种通过接口的方式,耦合度很高。而利用消息队列,可以将相应的消息发送到消息队列,这样的话,如果接口出了问题,将不会影响到当前的功能。
- 异步处理 异步处理替代了之前的同步处理,异步处理不需要让流程走完就返回结果,可以将消息发送到消息队列中,然后返回结果,剩下让其他业务处理接口从消息队列中拉取消费处理即可。
- 流量削峰 高流量的时候,使用消息队列作为中间件可以将流量的高峰保存在消息队列中,从而防止了系统的高请求,减轻服务器的请求处理压力。
值得强调提醒的是:
要处理对是对实时性具有强烈要求的数据还是建议用MQ; MQ和kafka之间还是存在一定差异的。
Kafka消费模式
Kafka的消费模式主要有两种:
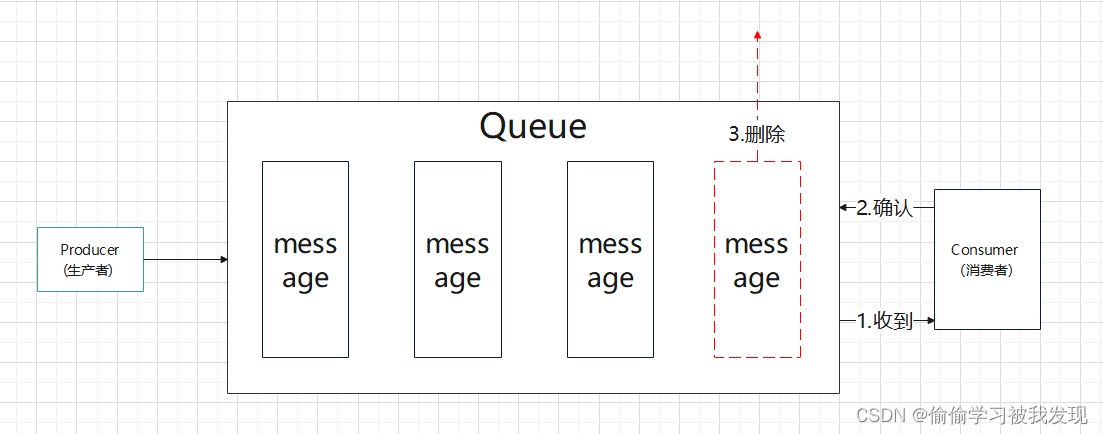
- 一对一的消费,也即点对点的通信,即一个发送一个接收。
- 一对多的消费,即一个消息发送到消息队列,消费者根据消息队列的订阅拉取消息消费。
一对一:
一对多:
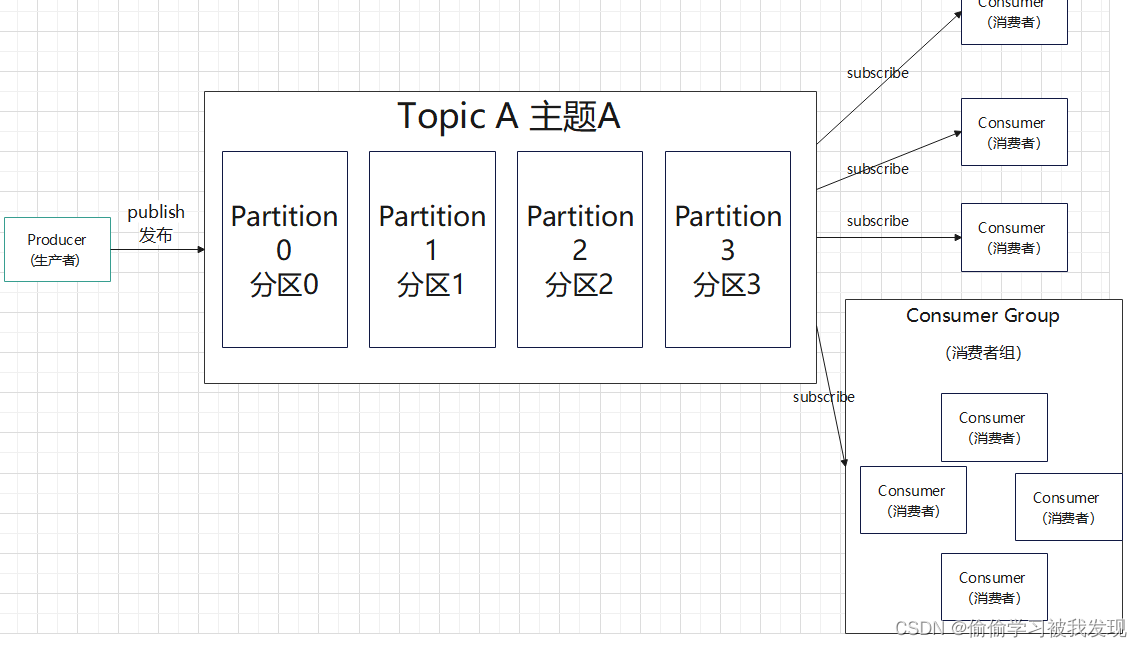
这种模式也称为发布/订阅模式,利用Topic存储消息,消息生产者将消息发布到Topic中,同时有多个消费者订阅此topic,消费者可以从中消费消息,注意发布到Topic中的消息会被多个消费者消费,消费者消费数据之后,数据不会被清除,Kafka会默认保留一段时间,然后再删除(消息在队列中能呆多久,可以修改 Kafka 的配置)。
- Topic 是生产者发送消息的目标地址,是消费者的监听目标。
- 如果是消费者组接收消息,Kafka 会把一条消息路由到组中的某一个服务。
一个服务可以监听、发送多个 Topics。
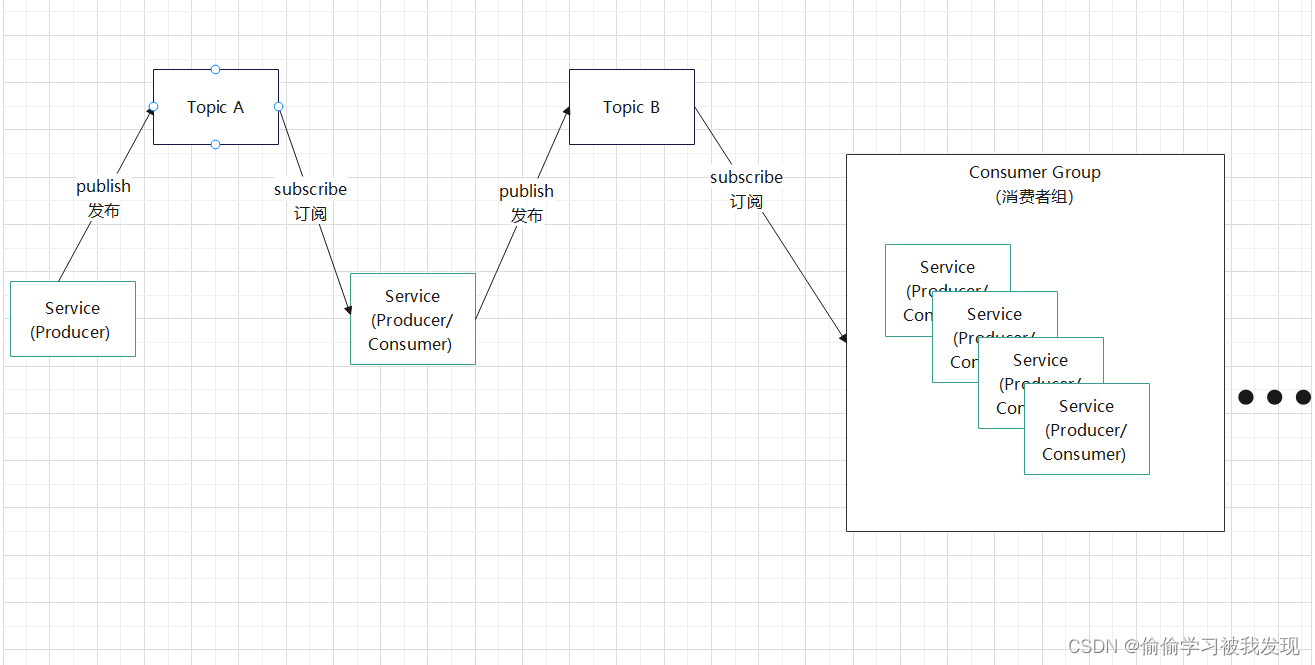
- 一个 Topic 可以由多个队列组成的,被称为Partition(分区),也可以由一个Partition组成。
- 生产者发送消息的时候,这条消息会被路由到此 Topic 中的某一个 Partition。
- 消费者监听的是所有分区。
- 生产者发送消息时,默认是面向 Topic 的,由 Topic 决定放在哪个 Partition,默认使用轮询策略。
- 也可以配置 Topic,让同类型的消息都在同一个 Partition。
- 消息在不同的 Partition 是不能保证有序的,只有一个 Partition 内的消息是有序的。
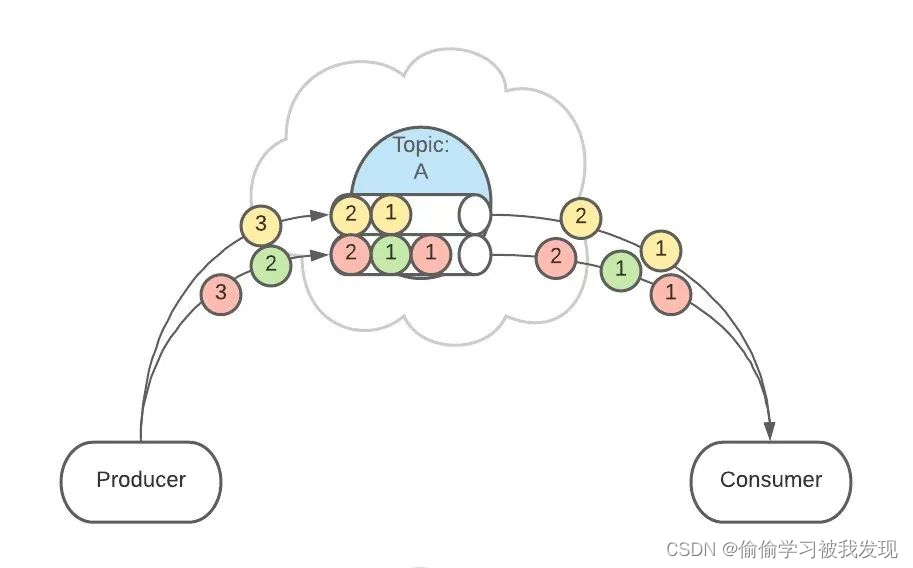
Kafka的基础架构
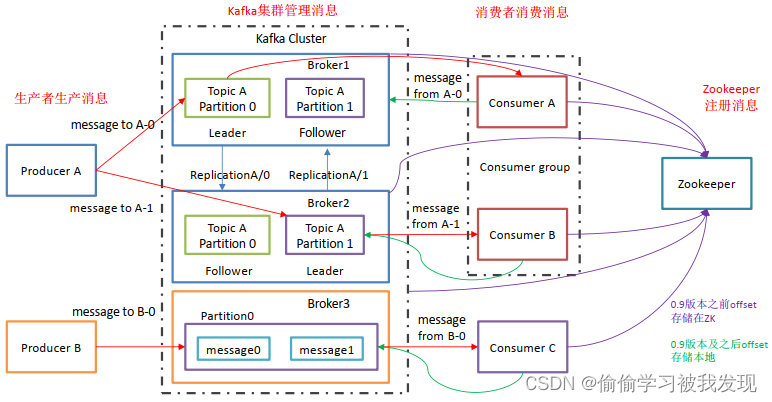
- Producer:消息生产者,向Kafka中发布消息的角色。 >
- Consumer:消息消费者,即从Kafka中拉取消息消费的客户端。
- Consumer Group:消费者组,消费者组则是一组中存在多个消费者,消费者消费Broker中当前Topic的不同分区中的消息,消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。某一个分区中的消息只能够一个消费者组中的一个消费者所消费。
- Broker:经纪人,一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic。
- Topic:主题,可以理解为一个队列,生产者和消费者都是面向一个Topic。
- Partition:分区,为了实现扩展性,一个非常大的Topic可以分布到多个Broker上,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序)
- Replica:副本Replication,为保证集群中某个节点发生故障,节点上的Partition数据不丢失,Kafka可以正常的工作,Kafka提供了副本机制,一个Topic的每个分区有若干个副本,一个Leader和多个Follower。
- Leader:每个分区多个副本的主角色,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
- Follower:每个分区多个副本的从角色,实时的从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。
工作流程
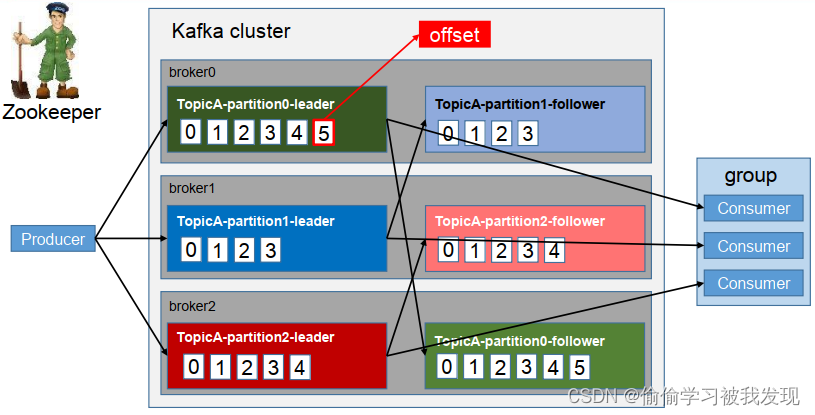
Topic是逻辑上的改变,Partition是物理上的概念,每个Partition对应着一个log文件,该log文件中存储的就是producer生产的数据,topic=N*partition;partition=log
Producer生产的数据会被不断的追加到该log文件的末端,且每条数据都有自己的offset,consumer组中的每个consumer,都会实时记录自己消费到了哪个offset,以便出错恢复的时候,可以从上次的位置继续消费。
流程:Producer => Topic(Log with offset)=> Consumer.

















 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











