










前言
最近忙于工作,有一段时间没更新自己的博客了,也就意味着囤积了一波需要梳理总结并记录的知识点,但可以保证的是所有都是零星的知识点,不会涉及工作内容。
一、MPP简介
MPP (Massively Parallel Processing),即大规模并行处理,将任务并行的分散到多个服务器和节点上,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似),每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据库服务。
1、MPP本质上是基于数据库的集群架构,基于数据库并区别于传统单节点数据库,支持多节点分布式存储和计算。(值得一提的是并不是所有的数据库集群方案都是基于分布式存储的)
2、MPP应该是多用作数据仓库,支撑查询和分析类应用场景。(个人理解)。
3、用关系型数据库(例如PostgreSQL),搭建一个分布式存储和计算的多节点集群,就基本形成了一个MPP数据库系统。
二、数据库非共享集群、数据库共享集群
MPP属于数据库非共享集群,故在此对数据库非共享集群、数据库共享集群进行简单区分,便于理解。
1、数据库非共享集群
在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据库服务。非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。
2、数据库共享集群
Data Shared Cluster 数据共享集群,简称DSC,是并行集群,位于不同服务器系统的DM实例同时访问同一个数据库,节点之间通过私有网络进行通信,所有的控制文件、联机日志和数据文件存放在共享的设备上,能够被集群中的所有节点同时访问。
DSC的优点主要在于高可用和负载均衡,一台机器宕机不影响应用访问数据库。
传统的单节点不属于集群,双机热备或Oracle RAC等,均是基于共享存储的。
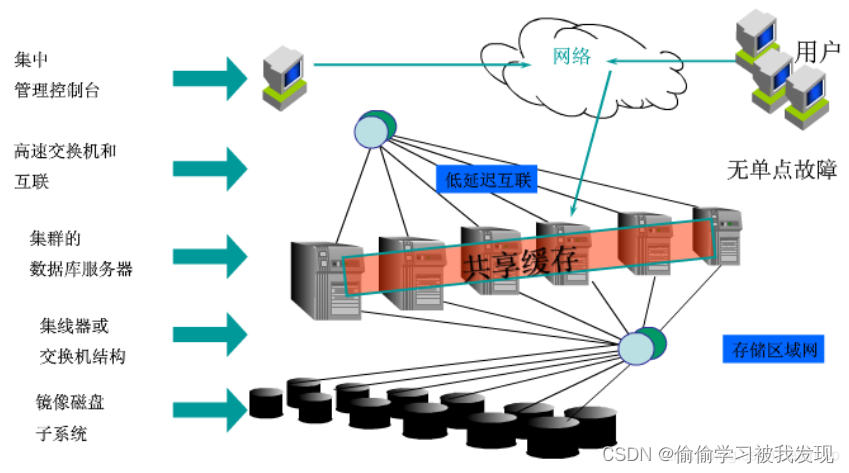
Oracle RAC集群架构图:
三、MPP架构
1、MPP架构特征
(1)任务并行执行
基于MPP架构,数据库支持大规模任务并行执行。
(2)私有资源
基于MPP架构,每个节点都有独立的磁盘存储系统和内存系统。
(3)数据分布式存储(本地化)
基于MPP架构,分布式数据存储场景,每个节点都有独立的磁盘存储系统,可以本地化存储数据。
(4)分布式计算
基于MPP架构,分布式数据存储场景,每个节点都有独立的内存系统,数据在各节点上完成计算后再存入各节点的物理磁盘。
(5)横向扩展
基于MPP架构,各个节点独立,故便于横向拓展。
(6)Shared Nothing架构。
shared noting(SN)是一种分布式计算架构。这这种架构中,每一个节点都是独立的,自给的,在系统中不存在单点竞争。更明确地说,没有节点共享存储和硬盘。人们通常将SN和大量保存中央存储状态信息的系统进行对比,无论是在数据库,应用服务器或者是其他相似的单点竞争。
SN相对中央控制架构有很大的优点。SN可以避免单点故障,拥有自我恢复能力,并且在不破坏原有系统的情况下进行升级。
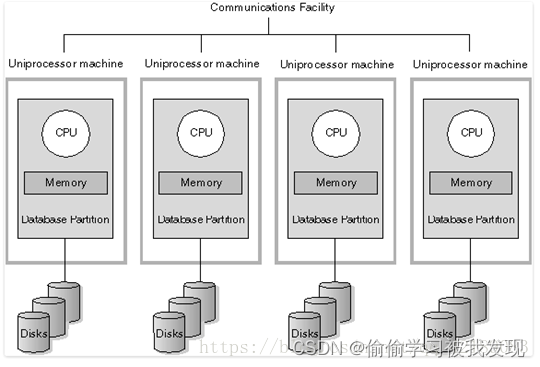
2.MPP部署架构
MPP部署架构是由多个SMP(对称多处理器结构,Symmetrical Multi-Processing)服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。其基本特征是由多个SMP服务器(每个SMP服务器称节点)通过节点互联网络连接而成,每个节点只访问自己的本地资源(内存、存储等),是一种完全无共享(Share Nothing)结构,因而扩展能力最好,理论上其扩展无限制。
四、MPP数据库
1、MPPDB简介
MPPDB是一款 Shared Nothing 架构的分布式并行结构化数据库集群,具备高性能、高可用、高扩展特性,可以为超大规模数据管理提供高性价比的通用计算平台,并广泛地用于支撑各类数据仓库系统、BI 系统和决策支持系统。
2、MPPDB架构
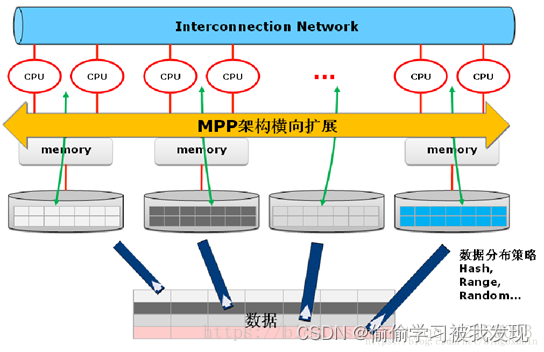
MPPDB 采用完全并行的MPP + Shared Nothing 的分布式扁平架构,这种架构中的每一个节点(node)都是独立的、自给的、节点之间对等,而且整个系统中不存在单点瓶颈,具有非常强的扩展性。
3、MPPDB特征
(1) 低硬件成本
完全使用 x86 架构的 PC Server,不需要昂贵的 Unix 服务器和磁盘阵列。
(2) 集群架构与部署
完全并行的 MPP + Shared Nothing 的分布式架构,采用 Non-Master 部署,节点对等的扁平结构。
(3) 海量数据分布压缩存储
可处理 PB 级别以上的结构化数据,采用 hash分布、random 存储策略进行数据存储;同时采用先进的压缩算法,减少存储数据所需的空间,可以将所用空间减少 1~20 倍,并相应地提高 I/O 性能;
(4) 数据加载高效性
基于策略的数据加载模式,集群整体加载速度可达2TB/h。
(5) 高扩展、高可靠
支持集群节点的扩容和缩容,支持全量、增量的备份/恢复。
(6) 高可用、易维护
数据通过副本提供冗余保护,自动故障探测和管理,自动同步元数据和业务数据。提供图形化工具,以简化管理员对数据库的管理工作。
(7) 高并发
读写不互斥,支持数据的边加载边查询,单个节点并发能力大于 300 用户。
(8) 行列混合存储
提供行列混合存储方案,从而提高了列存数据库特殊查询场景的查询响应耗时。
(9) 标准化
支持SQL92 标准,支持 C API、ODBC、JDBC、ADO.NET 等接口规范。
4、常见MPPDB
国外DBMPP产品:
GREENPLUM(EMC)
Greenplum是一个面向数据仓库应用的关系型数据库,它基于流行的PostgreSQL开发,有良好的体系结构,在数据存储,高并发,高可用,线性扩展,反应速度,易用性和性价比等方面有非常明显的优势.大数据,Greenplum的性能在TB级别数据量的表现上非常优秀,单机性能相比Hadoop要快上好几倍;在功能和语法上,要比Hadoop上的SQL引擎Hive好用很多,普通用户更加容易上手,Greenplum有着完善的工具,整个体系都比较完善,不需要像Hive一样花太多的时间和精力进行改造.非常适合作为一些大型数据仓库的解决方案.Greenplum能够方便地与Hadoop进行结合,直接把数据卸载Hadoop上,并且能够直接在数据库上写MapReduce任务,同时配置简单.
Asterdata(Teradata)、Nettezza(IBM)、Vertica(HP)
国内DBMPP产品:
DM达梦、TiDB (pingCAP)、OpenGauss & GaussDB (高斯数据库)、SequoiaDB(巨杉数据)、OB & PolarDB (阿里)、TDSQL(腾讯)、GBase 8a MPP cluster(南大通用)
















 8377
8377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











