







TF-IDF
以下内容部分摘录于百度百科。
什么是TF-IDF?
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)。
TF-IDF的原理:
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF的作用:
TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
TF-IDF怎么计算?
TF-IDF实际上是:TF * IDF,TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。
其中:TF表示词条在文档d中出现的频率。
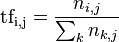
IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。
如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF式得到的IDF的值会小,就说明该词条t类别区分能力不强。
但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处. 在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)
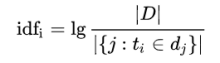
分子|D|:语料库中的文件总数;
分母包含词语的文件数目(即的文件数目),如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用下式作为分母。
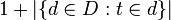
再计算TF与IDF的乘积。
TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TfidfVectorizer语法语法:
•vectorizer=TfidfVectorizer(stop_words=None,…)#返回词的权重矩阵
•TfidfVectorizer.fit_transform(X,y) #学习到一个字典,并返回Document-term的矩阵(即词典中的词在该文档中出现的频次) 其中Fit步骤学习idf vector,一个全局的词权重_idf_diag。输入的X是一个稀疏矩阵,行是样本数,列是特征数。Transform步骤是把X这个计数矩阵转换成tf-idf表示, X = X * self._idf_diag,然后进行归一化。#X:文本或者包含文本字符串的可迭代对象;返回值:返回sparse矩阵
•TfidfVectorizer.inverse_transform(X)#X:array数组或者sparse矩阵;返回值:转换之前数据格式
•TfidfVectorizer.get_feature_names()#返回值:单词列表
例子:
from sklearn.feature_extraction.text import TfidfVectorizer
dir=['@04Nakula sebenarnya mau nelikung koalisi dr '\
,'@Achmadr06327297 @fadlizon realita aja soal keunggulan itu']
vectorizer = TfidfVectorizer()#从训练数据集中学习到词典包含所有词
Frequent = vectorizer.fit_transform(dir)#Fit_transform学习到一个字典,并返回Document-term的矩阵(即词典中的词在该文档中出现的频次)_Frequent
#Fit步骤:学习idf_vector,一个全局的词权重_idf_diag。输入的X是一个稀疏矩阵,行是样本数,列是特征数。
#Transform步骤:是把X这个计数矩阵转换成tf-idf表示, X = X * self._idf_diag,然后进行归一化.
print('\n',Frequent.toarray())
print(vectorizer.get_feature_names())
test=['@fadlizon @Gerindra @prabowo Saya dukung pak prabowo capres,namun plihan #2019TetapJokowi','a b c']
#测试样本,会生成document-term矩阵,矩阵中的数是该文档中该词出现的次数,即tf;然后tf*idf(从idf vector中查找),最后归一化。
print(vectorizer.transform(test).toarray())
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











