







 文章探讨了CLIP模型在图像和文本连接方面的应用,如VQGAN和DALL-E,以及GPT系列的演化,强调了大型预训练模型在零样本学习和微调下游任务的能力。GPT-3展示了Zero-Shot、One-Shot和Few-Shot学习的不同方法,而CODEX展示了GPT-3在代码生成上的专业应用。
文章探讨了CLIP模型在图像和文本连接方面的应用,如VQGAN和DALL-E,以及GPT系列的演化,强调了大型预训练模型在零样本学习和微调下游任务的能力。GPT-3展示了Zero-Shot、One-Shot和Few-Shot学习的不同方法,而CODEX展示了GPT-3在代码生成上的专业应用。
CLIP
GPT:有足够大的语料,可以完成相关的下游任务
总结:
Contrastive Language-Image Pre-Training(利用文本的监督信号训练一个迁移能力强的视觉模型),预训练模型直接zero-shot,迁移能力强。
泛化能力强,不需要训练也能认识。
可以在CLIP基础上做拓展。
打通图像和文本的连通,对抗生成网络
CLIP下游应用:VQGAN、DALL-E
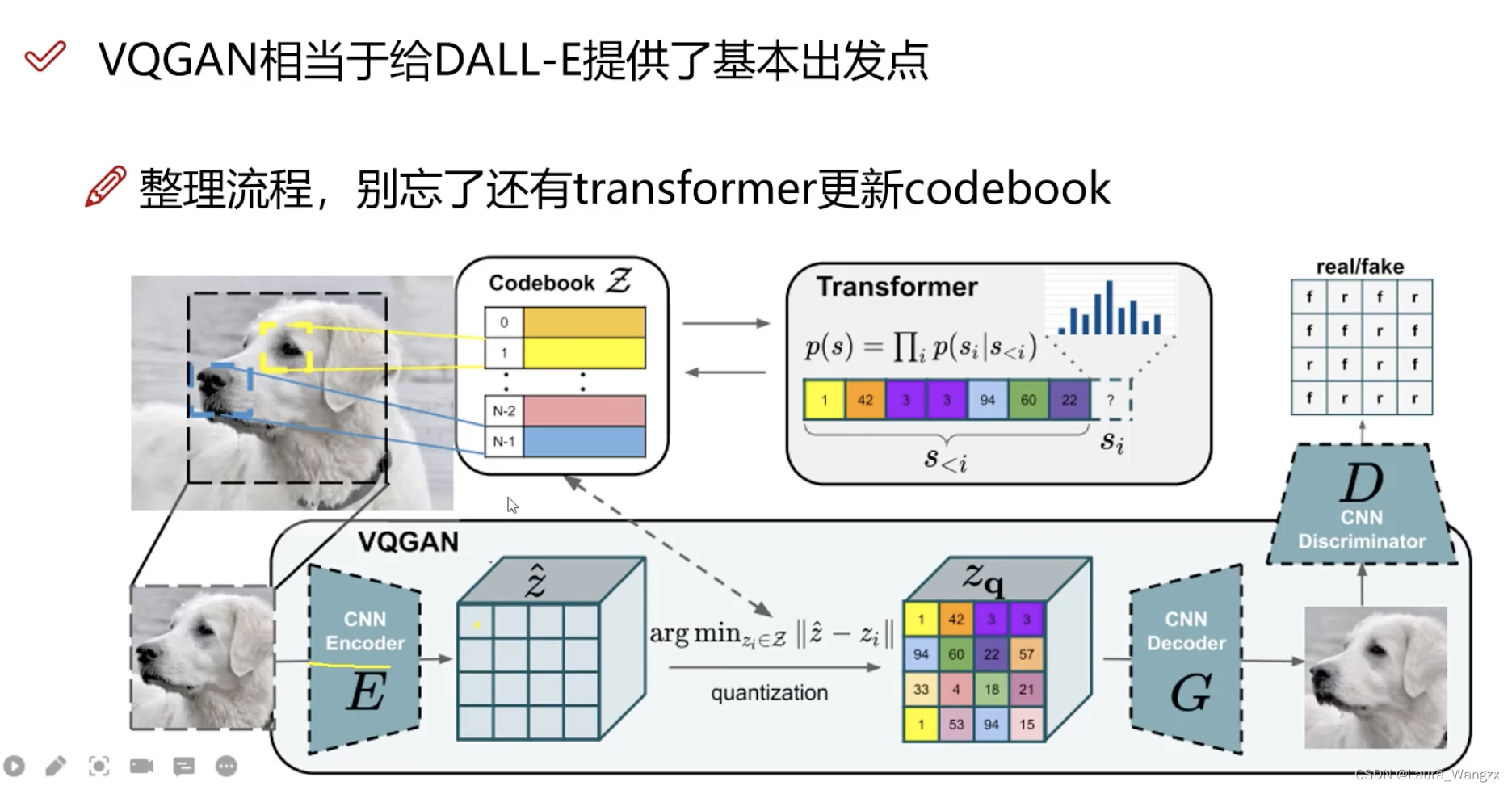
总体思路:将关键词/离散特征组装特征为连续特征。
本质:图像离散化特征。
流程:编码器(模型学出来的)得到特征——根据相似度得到离散特征——查codebook表,得到最后实际编码后的特征。
基于VQGAN:建立Codebook,计算相似度
CLIP-Event:Connecting Text and Images with Event Structures
能将事件中的人与动作链接起来。
相当于先通过文本时间抽取得到一些关系组合,再与图像进行配对
新闻事件抽取——知识图谱的抽取——先把新闻抽取成一个三元组,然后还要再讲他们组合成一句话
正负样本的制作——正样本就是抽取的事件——负样本可以替换事件——也可以替换主体——类似hard negative
正负样本组合
Hierarchical Text-Conditional Image Generation with CLIP Latents
github代码: DALLE2-pytorch
-
对比学习:无监督近似有监督的效果。4亿对配对文本,可以训练出一个模型。prior生成clip的image embedding——decoder生成一个图像。(扩散模型:diffusion model,U-Net,扩散过程:对图片逐渐加噪、马尔科夫过程;逆扩散过程:从噪声中逐渐复原出图片。
-
已知:加载预训练模型,获得文本embedding、图像embedding。
-
输入:text embedding
-
过程:训练两个UNET:先验prior+decoder
-
(1)先验prior生成初始化图像向量:通过caption去生成图像embedding。
AR先验:VQGAN通过codebook将图像离散化
diffusion model扩散模型:使用Gaussian噪声不断去还原。
文本输入(全局向量cls部分+每个词对应的向量token部分)+时间步输入+随机初始化噪音 -
输出:构建图像
GPT系列算法
- 基于Transformer做的,数据量大/参数多。目前适用于:不自己训练语言模型,微调GPT适应下游任务。
- 使用Huggingface里面的,微调
- GPT历史:
2018年,GPT-1,5GB文本,1.17亿参数量。
2019年,GPT-2,约40GB文本,15亿参数量。
2020年,GPT-3,45TB文本,1750亿参数量。 - BERT与GPT区别:BERT完形填空,结合上下文——简单任务,是一个编码器;GPT:自回归模型,只给上文来预测下文,是一个解码器。
GPT-1:
整体结构就是transformer解码器。所有下游任务都需要微调(再训练)
GPT-2:
下游任务不需要微调。
Zero-Shot:不做任何训练、不做任何微调,只通过提示表示。提示在实际任务中没有训练。
(1)采样策略相关:
自回归模型要进行预测,但是会陷入一个死循环呢。成语接龙:一一得一,一一得一,一一得一,一一得一,一一得一。我们希望模型有点多样性,在生成中优先选概率高的,小概率选边缘化的东西。
(2)采样参数相关:
Temperature温度:对预测结果进行概率重新设计,默认温度为1就相当于还是softmax。温度越高,相当于多样性越丰富(雨露均沾),温度越低相当于越希望得到最准的那个
Top k与Top p:TOPK和TOPP都是要剔除掉那些特别离谱的结果。T0PK比如概率排序后,选前10个,那之后的值就全部为0;TOPP就跟那个CUMSUM似的,算累加,一般累加到0.9或者0.95,之后的值就全部为0。
GPT-3:
不做微调。GPT-3训练的数据包罗万象,上通天文下知地理。 虽然没提供源码,但是提供了付费API来微调。单独训练“提示”,其实中文模型也有很多,百度文心大模型应该也能媲美一下。
- 3种核心的下游任务方式:Zero-shot、One-shot、Few-shot。
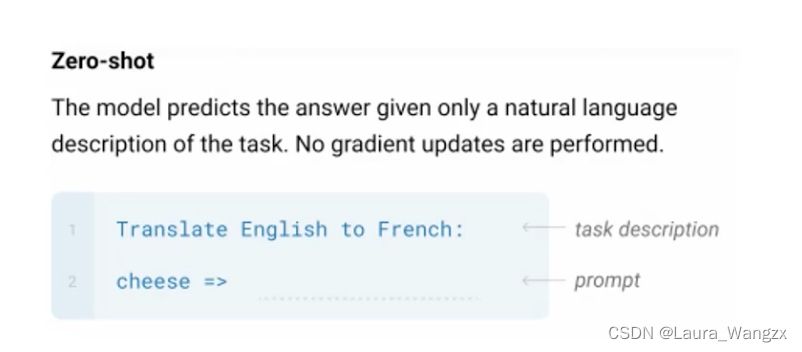
(1)Zero-shot:The model predicts the answer given only a natural languaged escription of the task.No gradient updates are performed.模型只给出任务的自然语言描述来预测答案。不执行梯度更新。
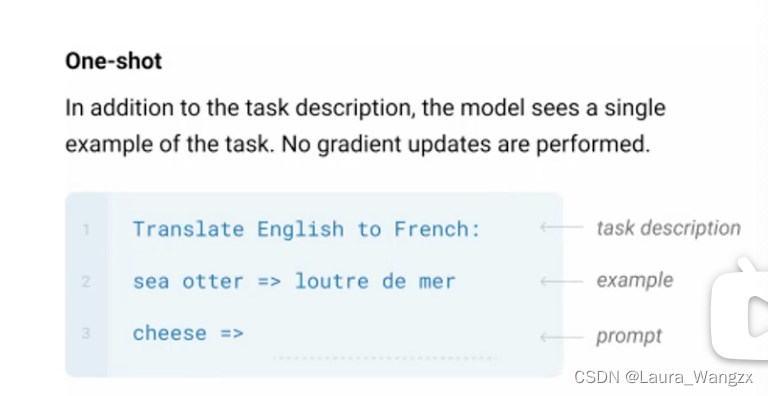
(2)One-shot:In addition to the task description,the model sees a singleexample of the task.No gradient updates are performed.除了任务描述之外,模型还看到了任务的单个示例(将提示例子与输入一起输入到模型中,一个提示都有效果)。不执行梯度更新。
(3)Few-shot:In addition to the task description,the model sees a fewexamples of the task.No gradient updates are performed.除了任务描述之外,模型还会看到一些任务的例子(将提示所有例子与输入一起输入到模型中,一个提示都有效果)。不执行梯度更新。

3种方式的对比:这三种都没有更新模型,肯定few的效果好一些,但是问题就是API更贵了,输入序列长度更长了。
准备数据:
1.数据集得大,清洗
2.质量判断,对爬取的网页,进行分类任务看其质量ok不
3.对网页进行筛选,剔除掉一些重要性低的(这些算法设计起来也不容易)
4.包括了前几代版本的训练数据,整合一块后开始训练
GPT-3应用:Evaluating Large Language Models Trained on Code:CODEX
用GPT-3模型重新训练(注意不是微调),面向GITHUB编程。
专业定制化


















 1960
1960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











