









线性回归算法是基于已知样本并在已知样本数据范围内预测的一种监督学习算法
线性回归的特点:目标预测的是连续的数值
二维问题中,在训练样本中,需要学习映射函数f(x) 表达y
设f(x) = ax+b, 用一条直线来拟合样本数据
三位问题中,设预测函数 h(θ) = θ0+θ1*x1+θ2*x2
则在n为问题中,预测函数为:h(θ)==y
为了评估预测结果的准确度,通过Gradient Descent(梯度下降算法),最小化损失函数,来确定参数值,最终将参数带入计算。
损失函数= J(θ)=1/2m * [hθ(χ(i))-y(i)]^2
while(min_θj>θj){ //一直重复,知道求出来的
θj :=θj-α*(σ/σθj)J(θ)
},其中损失函数求偏导的步骤为:
θj′: = θj+(𝑦𝑖-hθ(𝑋𝑖))𝑋𝑗𝑖
=[ 1/2𝑚 * θ𝑗𝑋𝑖+θ0−𝑦𝑖^2]′ (对θj进行求导)
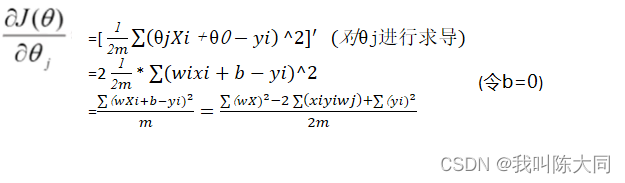
误差:真实值和预测值之间存在的差异ε 对于每个样本: y(i) = θ^Tx(i)+ε(i)
误差ε(i)是独立具有相同的分布,并且服从均值为0方差为θ^2的高斯分布(大部分数据方差分布趋向于0 )
损失函数:把模型关于单个样本预测值与真实值的差称为损失
通过使损失函数最小,来寻找最优权重参数
最小二乘法表示: J(θ) = 1/2 𝑘=0𝑚𝑦𝑖−θT𝑥(𝑖)2![]()
目标函数:J(θ) = 1/2 (Xθ-y)^T * (Xθ-y)
对θ求偏导:
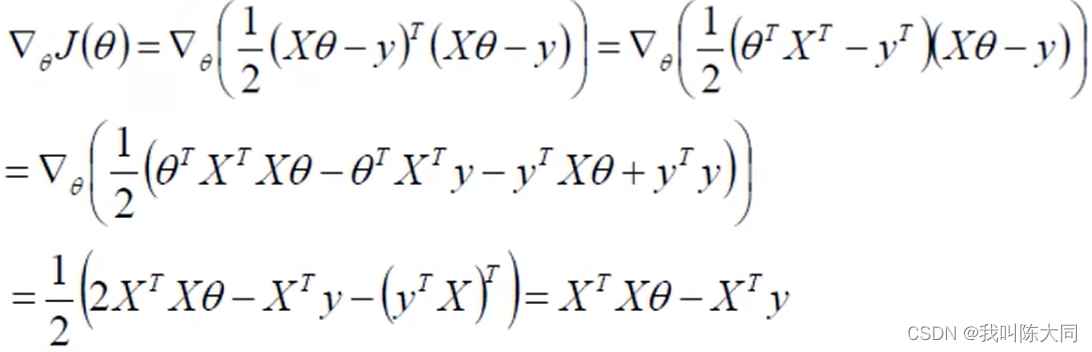
令 偏导为0,即𝑋𝑇*𝑋θ=𝑋𝑇y => θ=(𝑋𝑇𝑋)−1𝑋𝑇y (不一定成立)
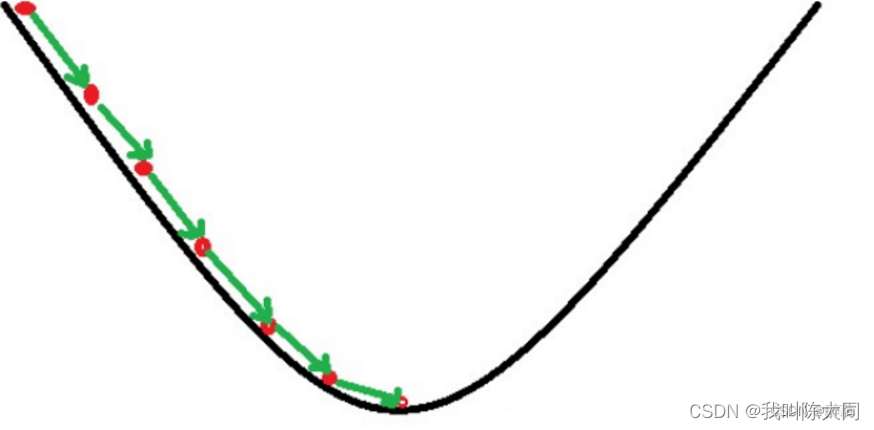
梯度下降算法
按照目标函数学习,朝着这个方向一步步完成迭代优化
注:梯度下降公式中 i 是对所有样本进行迭代,j是当前第j个参数位置对应的xj
学习率:对结果产生巨大影响
批量梯度下降:容易得到最优解,但需要考虑所有样本,速度较慢
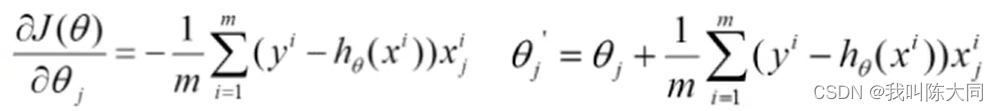
随机梯度下降:每次找一个样本,迭代速度快,但不一定每次都向收敛方向
θj′: = θj+(y^i-hθ(X^i))*Xj^i
随机梯度下降:每次找一个样本,迭代速度快,但不一定每次都向收敛方向
θj′: = θj+(y^i-hθ(X^i))*Xj^i
小批量梯度下降:每次更新选择一小部分数据训练
θj′: = θj-α110𝑘=𝜄𝜄+9hθ(𝑋𝑘)−𝑦𝑖𝑋𝑗𝑖 注: 𝑋𝑗𝑖 为第j个参数对应的样本所有𝑋𝑗的数据
直到θj迭代到最低点即为最优解参数,将θj与测试数据代入预测函数得到预测标签
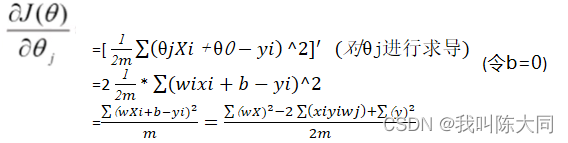
![]()
![]()
则损失函数可简化为:J(w) = (a*w^2 - 2bw + c)/m
代码实现:
list_x = [ 1.5, 2.5, 3.0, 4.5, 5.0, 5.5, 6.5, 8.5, 9.0, 9.5, 10.5, 12.0, 13.0, 14.5, 15.0, 16.5, 16.5, 18.0, 19.0,20.5]
list_y = [ 4.0, 8.0, 9.0, 13.5, 15.0, 16.0, 19.0, 25.0, 27.0, 28.0, 32.0, 35.5, 38.5, 43.0, 45.0, 49.5, 50.0, 54.5, 57.5,61.0]
print("训练样本X: ",list_x)
print("训练样本Y: ",list_y)
def max_k():
max_k = 0.0
for i in range(0,len(list_x)):
temp_k = list_y[i]/list_x[i]
if(temp_k>max_k):
max_k = temp_k
return max_k
max_k = max_k()
print(max_k)
list_e = []
list_w = []
step = 0.1
def costFunction(): #最小二乘法
a = 0 b = 0 c = 0
for i in range (0,20):
a += list_x[i]*list_x[i]
b += list_x[i]*list_y[i]
c += list_y[i]*list_y[i]
return a,b,c
a,b,c = costFunction() # 计算损失函数系数项
def gradientDescent():
w = 0.0
n = len(list_x)
while(w<max_k):
e = (a*pow(w,2)-2*b*w+c)/2
list_e.append(e)
list_w.append(w)
w+=step
print("权值列表: ", list_w)
print("代价函数列表: ", list_e)
print("最小代价值位置: ", list_e.index(min(list_e)))
print("最小代价值参数: ", list_w[list_e.index(min(list_e))])
return list_w[list_e.index(min(list_e))]
result = gradientDescent()
def test():
input_x = 11.0
input_y = result*input_x
print("测试样本: ",input_x)
print("测试结果: ",input_y)
test()















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









