






字典编码本质上是将在字典中出现过的字符串使用一个索引值代替,以此来达到压缩目的。基于字典的压缩算法有很多,LZ77和LZ78是最原始的两个算法,后者是前者的变体,原理基本上相似。本文对LZ77字典编码的压缩和解压缩流程进行介绍。
一、什么是LZ77字典编码
LZ77算法是无损压缩算法,由以色列人Abraham Lempel发表于1977年,是典型的基于字典的压缩算法,现在很多压缩技术都是基于LZ77。
LZ77字典编码把整个滑动窗口分为2个区域,左侧为字典区,右侧为待编码区。
LZ77编码器在字典区查找,直到找到匹配的字符串。匹配字符串的开始位置与离字典区右边的距离称为“偏移值”,匹配字符串的长度称为“匹配长度”。LZ77在编码时,会一直在字典区中搜索,直到找到最大匹配字符串,然后输出一个三元祖(off, len, char),off表示偏移值,len表示匹配长度,char为待编码区第一个等待编码的字符。
偏移值实际上可以有两种,第一种是匹配字符串的开始位置离字典区左边的距离,第二种是匹配字符串的开始位置离字典区右边的距离,一般使用第二种。
二、LZ77编码的压缩流程
在编码前要指定滑动窗口的大小,这里设置为8,其中字典区窗口大小为5,待编码区窗口大小为3。
现在有字符串“AABCBBABC”,现在对其进行编码。
(1)编码开始,窗口初始位置如图

由上图可见,待编码区有“AAB”三个字符,此时字典区为空。现在编码第一个字符A,由于字典区为空,故匹配不到的字符串。当匹配不到字符串时,规定偏移值为0,匹配长度也为0,此时待编码区第一个等待编码的字符为A,故输出(0,0, A),然后滑动窗口右移一个单位,如下图

(2)如上图可知,此时待编码区为“ABC”。现在编码“A”,在字典区可以匹配到字符串"A",继续编码“AB”,由于在字典区没有可以匹配到的字符串,无法编码,因此只能编码"A"。
字典区匹配到的“A”的开始位置离字典区右边的距离为1,匹配字符串的长度也为1,待编码区第一个等待编码的字符为A,故输出(1,1,A),滑动窗口右移一个单位,如下图
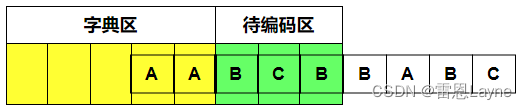
(3)继续编码,此时待编码区为“BCB”。现在编码“B”,字典区没有匹配到,无法编码,输出(0,0,B),滑动窗口右移一个单位,如下图
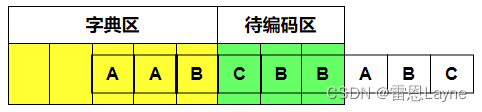
(4)待编码区为“CBB”,现在编码“C”,字典区没有匹配到,无法编码,输出(0,0,C),滑动窗口右移一个单位,如下图
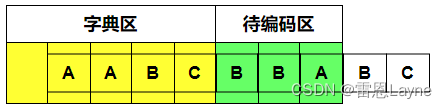
(5)待编码区为“BBA”,现在编码“B”,字典区可以匹配到,继续编码“BB”,字典区匹配不到,无法编码,输出(2,1,B),滑动窗口右移一个单位,如下图
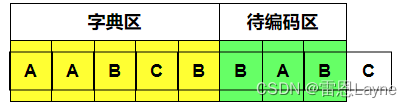
(6)待编码区为“BAB”,现在编码“B”,字典区可以匹配到,继续编码“BA”,字典区匹配不到,无法编码,输出(3,1,B),滑动窗口右移一个单位,如下图
字典区有从左到右匹配的,上图中字典区第一个“B”离字典区右边的距离为3。
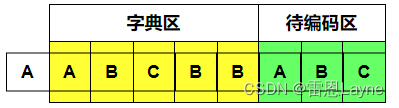
(7)待编码区为“ABC”,现在编码“A”,字典区可以匹配到,继续编码“AB”,字典区也可以匹配到,继续编码“ABC”,字典区能够匹配。待编码区中的字符都编码完了(即编码位置已经达到了待编码窗口右边界,如果继续编码,就会超过窗口边界),输出(5,3,A),长度3,滑动窗口右移3个单位,如下图
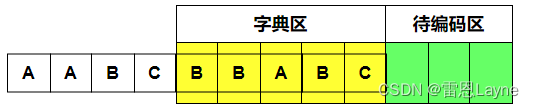
此时待编码缓冲区为空,结束编码。所以,当我们输入字符串“AABCBBABC”最后得到的三元组序列为(0,0, A),(1,1,A),(0,0,B),(0,0,C),(2,1,B),(3,1,B),(5,3,A)
上面是最原始的匹配方法,具体实现时可以进行优化,比如利用字典树(TrieTree)匹配。
三、LZ77编码的解压缩流程
解压缩码相对起来就简单许多了,就是编码流程的逆过程,具体流程如下
- 按需读取三元组进行,并进行解压
- 如果
off=0,表示原字符,直接输出char - 如果
off<>0,读取字典中的字符,找到偏移值为off的位置(距离字典右侧的偏移),截止len个字符,比如 dict = “ABCD”,编码为(3,2,E),找到偏移值为3的位置(即B),截取2个字符,输出为BC - 获取下一个三元组,直到所有的三元组解析完毕
现在,输入三元组序列为(0,0, A),(1,1,A),(0,0,B),(0,0,C),(2,1,B),(3,1,B),(5,3,A),字典大小为5,具体解压如下:
| 步骤 | 输入 | 当前字典 | 解码 | 输出 |
|---|---|---|---|---|
| 1 | (0,0, A) | A | A | |
| 2 | (1,1,A) | A | A | AA |
| 3 | (0,0,B) | AA | B | AAB |
| 4 | (0,0,C) | AAB | C | AABC |
| 5 | (2,1,B) | AABC | B | AABCB |
| 6 | (3,1,B) | AABCB | B | AABCBB |
| 7 | (5,3,A) | ABCBB | ABC | AABCBBABC |
参考资料















 147
147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











