






Kaldi 教程
Kaldi的开始
Kaldi下载
使用github得到最新的kaldi工具包
git clone https://github.com/kaldi-asr/kaldi.git
git经常由于网络不稳下载失败,建议本地开vpn之后下载上传
git下载结束后需要进行接下来的操作
cd kaldi/tools/
make
cd ../src
./configure
make
在tools路径下有INSTALL文件说明了如何安装和相关依赖
Kaldi的主要介绍
在kaldi-master路径中可以看到tools目录,tools是安装kaldi的依赖的地方。
最重要的子目录是openfst的子目录,其中包含比较重要的lib,bin目录,最重要的代码在fst目录中,深入了解Kaldi需要了解OpenFST。为此,最好的起点是http://www.openfst.org/。
在include/fst/fst.h中,包括一些抽象fst类型的声明
Kaldi实例
构建状态机,初始状态为0,一个有限状态机中只能有一个状态机,终止状态为2,它有一个最终权重为3.5。在状态0和1之间对输入a有一个状态转换,输出标签x,并且权重为0.5。
这个有限状态机对于ac到xz的转化有6.5的矩阵(arc和最终权重之和)
使用Kaldi运行状态机
首先使用fstcompile构建状态机状态机的输入主要是一个fst文件,构成文件的方式是
cat >text.fst <<EOF
0 1 a x .5
0 1 b y 1.5
1 2 c z 2.5
2 3.5
EOF
第一列是出发状态机,第二列是到达状态机,第三列是输入标签,第四列是输出标签,第五列是权重(可选),最后一行是终止状态只由状态和权重(可选)组成,行可以以任何顺序出现,但初始状态是第一行
arc的内部表示是实数。我们必须要提供一个输入输出的标签转换,构成文件的方式是
$ cat >isyms.txt <<EOF
<eps> 0
a 1
b 2
c 3
EOF
$ cat >osyms.txt <<EOF
<eps> 0
x 1
y 2
z 3
EOF
label可以用任何string,id可以用任何非负整数,0这个id是给epsilon标签的
定义了状态机结构后需要将fst文件转换为二进制文件并使用txt文件中定义的映射将符号转化为实数,这里使用fstcompile进行编码
$ fstcompile --isymbols=isyms.txt --osymbols=osyms.txt text.fst binary.fst
Kaldi的src目录
在该目录中,以bin结尾的子目录都是包含可执行文件的,代码和可执行文件在相同的目录中,其他的子目录包含内联代码。在Makefile中的include代码。
include ../kaldi.mk
在这个include中包含了一些与valgrind(内存调试)相关的规则,以变量形式包含一些特定于系统的配置,如CXXFLAGS,CXXFLAGS中的-O0表示启用的优化级别,-DKALDI_PARANOID在debug用到,使用最快的速度采用
-O2 -DNDEBUG
-O3 -DNDEBUG
与矩阵向量相关的函数在matrix/中,KALDI_ASSERT的相关定义在kaldi-utils.h中,KALDI_ASSERT主要在kaldi-math.h中使用。在出现错误时,不依赖人工对数据的检查而以错误形式退出。
text-utils.h中输入为第一个参数,输出通常为最后一个变量。不允许将非常量引用作为函数参数。
在kaldi的gmmbin目录下使用
./gmm-init-model
可以看到如下usage
Options:
--binary : Write output in binary mode (bool, default = true)
--var-floor : Variance floor used while initializing Gaussians (double, default = 0.01)
--write-occs : File to write state occupancies to. (string, default = "")
Standard options:
--config : Configuration file to read (this option may be repeated) (string, default = "")
--help : Print out usage message (bool, default = false)
--print-args : Print the command line arguments (to stderr) (bool, default = true)
--verbose : Verbose level (higher->more logging) (int, default = 0)
在Standard options中有一个–config可以用来传入configuration文件
使用Kaldi
首先是shell中if的使用讲解
https://www.cnblogs.com/senior-engineer/p/6206329.html
准备词典
用aishell为例子,首先运行aishell_prepare_dict.sh对lexicon.txt进行处理准备词典,会输出extra_questions.txt,nonsilence_phoes.txt,optional_silence.txt,silence_phones.txt。这里用到了awk,什么是awk呢?awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
使用方法:
awk '{pattern+action}' {filenames}
pattern表示awk在数据中查找的内容,而action是在找到匹配内容
awk '{for(n=2;n<=NF;n++){phone[$n]=1;}} END{for (p in phones) print p}'
这里是将lexicon除第一行之外的字符串提取出来
简单perl学习
perl可以分为交互式编程和脚本式编程,交互式编程使用以下语句
$perl -e 'print "Hello World\n"'
脚本式编程要在脚本开头指定解释器
$!/usr/bin/perl
perl脚本代码可以卸载一个后缀为pl的文本文件中
perl注释方法
# 单行注释
=pod 注释
多行注释
=cut
perl是一种弱类型语言,解释器根据上下文自动选择匹配类型,最基本的数据类型包括:标量、数组、哈希。
标量:$scalar=123;
数组:@arr=(1,2,3)
哈希:%h=('a'=>1,'键'=>值)
perl实际上把整数存在浮点寄存器中,可以被当做浮点数看待,但是整形的比较仍然可以用==。perl的浮点数的指数范围为-309和+308。
perl的字符串使用一个标量来表示,在perl中的双引号可以正常解析一些转移字符与变量,而单引号无法解析转字符
数组变量在访问时使用 + 变 量 名 + [ 下 标 ] , 下 标 从 零 开 始 ; 哈 希 变 量 在 访 问 时 使 用 +变量名+[下标],下标从零开始;哈希变量在访问时使用 +变量名+[下标],下标从零开始;哈希变量在访问时使用+变量名+{‘键’}来访问。
使用数组赋值给标量时,返回数组元素个数。
字符串连接使用.,同样数字和字符串连接也使用.
$str = "hello"."world"
perl有特殊字符,以下字符直接使用不需要使用$
__FILE__文件名
__LINE__行号
__PACKAGE__包名
可以添加和删除数组元素
push(@array,"ba"); 在数组结尾添加元素
unshift(@array,"ba"); 在数组开头添加元素
pop(@array); 删除数组末尾元素
shift(@array); 删除数组开头元素
可以使用(1…20)生成从1到20,相差为1的递增序列
splice(@array,起始位置,替换的元素个数,替换元素列表)————数组替换
split(分隔符,指定字符串,LIMIT(指定该参数,则返回数组的元素个数))————字符串转化为数组
join(连接符,列表或数组)————将数组转换为字符串
$[为数组第一索引值
脚本代码解读(aishell_prepare_dict.sh:18行到21行)
- while(<>){}表示从标准输入输出流中获取信息。这里的作用是检测输出的结尾
- chomp的作用是去除结尾的换行符
- $_表示默认输入和模式匹配的内容,这里可以理解为分割后的一段字符
- next这里的作用是跳过处理sil字符
- m表示跨行匹配
- 正则表达式前半部分表示匹配0次以上重复的非数字字符,后半部分表示匹配0或0次以上的数字字符,前面的^表示匹配开头的字符
- 如果匹配失败则结束脚本
- 以匹配到的非数字字符为键,存入音素并不断拼接
- 最后将词典整个输出,并以第一个token排序并存入文件中
同理第31到32行是将音素以末尾音调进行分类,将同一音调的音素分为一类
准备词典共3个输出silence_phones.txt,extra_questions.txt,nonsilence_phones
准备数据,分为test、dev、train集
使用aishell_data_prep.sh将数据分成test、dev、train集
awk命令中的$NF代表浏览记录的域的个数
sed命令是一种流编辑器,处理文本时,把当前的行存储在临时缓冲区内,接着用sed命令处理缓冲区中的内容,处理成后,把缓冲区的内容送往屏幕显示。地址用于决定对哪些行进行编辑。地址的形式可以是数字。这里的两个sed作用都是去掉.wav
paste命令用于合并文件的列,把每个文件以列对列的方式,一列列加以合并,-d指定分割符号
filter_scp用于从语音的id中生成一个scp文件
词典、语言文件准备,生成对应的数据关系
utils/prepare_lang.sh --position-dependent-phones false data/local/dict \
"<SPOKEN_NOISE>" data/local/lang data/lang
其中,数据关系保存在/data/dev里,文件解释如下:
- spk2gender包含说话人的性别信息
- spk2utt包含说话人编号和说话人的语音信息
- text包含语音编号和语音文本之间的关系
- utt2spk语音编号和说话人编号之间的关系
- wav.scp包含了原始语音的路径信息
训练语言模型
使用text和lexicon.txt作为输入,语言模型参数3gram-mincount/lm_unpruned.gz,得到语言模型
使用语言模型生成有限状态机
使用format_lm.sh将语言模型转化为状态机,并进行一定的format
MFCC特征提取
make_mfcc_pitch.sh将语音信号转化为mfcc域后提取特征,输入为train dev test中的语音文件,输出为raw_mfcc_pitch_XXX.X.ark和raw_mfcc_pitch_XXX.X.scp
在make_mfcc_pitch.sh中最重要的两个命令是cumpute-mfcc-feats 和copy-feats,其在src中编译好的
compute_cmvn_stats.sh计算倒谱均值和方差归一化,输入仍然为train dev test,输出为cmvn_XXX.ark和cmvn_XXX.scp,scp文件中是语音段和特征对应,ark中保存特征
单音素训练
使用train_mono.sh脚本,输入为train的data和字典lang,输出为exp/mono,里面以.mdl结尾的文件保存了模型的参数。
kaldi统一使用ParseOptions注册参数,方法是
ParseOptions po(usage)
po.Register(名字,引用,说明)
po.Read(argc,argv)
这样可以将命令行中输入的参数对应到注册的参数上,获取参数使用下面代码
po.GetArg(n) 获取第n个参数
kaldi对每个音素建立一个HMM模型,叫HMMEntry,由三个state组成
transition state(int) map: phone_id, hmm-state(0,1,2), pdf-id
transition-index map: pair(nextstate, transmission/emitting probability)
transition-id maps: (transition-state, transition-index)
gmm-init-mono
作用初始化单音素GMM,可以在kaldi-master/src/gmmbin中找到代码,使用方法为
Usage: gmm-init-mono <topology-in> <dim> <model-out> <tree-out>
-
计算所有特征数据的每一维特征的全局均值、方差
使用维度参数定义全局均值、方差glob_inv_var,glob_mean,并设置为1.0 -
读取topo文件,创建共享音素列表,根据共享音素列表创建ctx_dep
构建单音素解码图
mkgraph.sh主要生成了HCLG.fst和words.txt这两个重要的文件,后续识别主要利用了三个文件,分别是final.mdl、HCLG.fst、words.txt。
解码:分别针对开发集和测试集的解码
使用decode.sh对开发集和测试集的解码。解码的日志保存在exp/mono.decode_dev/log和exp/mono/decode_test/log里
Veterbi对齐
使用align_si.sh进行Veterbi对齐,之后是和训练单因素一样,训练两次deltas,一次LDA+MLLT,一次fMLLR(FMLLR对齐),一次SAT(fmllr对齐)
脚本作用总结
- train_mono.sh 用来训练单音子隐马尔科夫模型,一共进行40次迭代,每两次迭代进行一次对齐
- train_deltas.sh 用来训练与上下文相关的三音子模型
- train_lda_mllt.sh 用来进行线性判别分析和最大似然线性转换
- train_sat.sh 用来训练发音人自适应,基于特征空间最大似然线性回归
- nnet3/run_dnn.sh 用nnet3来训练DNN,包括xent和MPE
- chain/run_dnn.sh 用chain训练DNN
注意在运行nnet3/run_dnn.sh过程中要设定训练ivector所要用到的gpu数量。这个数量要在steps/online/nnet2/train_ivector_extractor.sh中设置num_processes的值,在该文件的注释中提到了相关参数的设置
在运行时多次因为占不到卡而报错退出,log文件为exp/nnet3/tdnn_sp/log/train.0.1.log
三音素GMM
在单音素GMM中,我们对每一个音素建立一个HMM模型,并相应于音素开头、中间和结尾使用了3个发射状态(emitting state),每个发射状态对应一个GMM模型,然而这种建模方式只是对一个音素单独建模而没有考虑到发音是个连续的过程。
由于协同发音情况的存在,一个音素在很大程度上与前一个或者后一个音素关联,所以需要上下文音素一起建模,因此有了三音素GMM。
什么是三音素GMM
三音素的HMM模型属于CD phone(依赖于上下文音素),表示在特定左侧上下文和特定右侧上下文中的音素。
[a-b+c]前[a]后[c]
[a-b]前[a]
[b+c]后[c]
但是由于排列组合导致的建模单元大量增加,对于50个音素的音素集来说。需要$50^3$个三音素,但是一些组合事实上是不会存在的,因此有必要减少需要训练的三音素数量。
而最普通的办法是对于某些上下文进行聚类,把上下文在同一类别的状态捆绑起来。例如:左侧以[n]开头的音素与左侧以[m]开头的音素看起来很相近,因此可以将[m-eh+d]和[n-eh+d]中开头的第一个次音素绑定起来,从而共享同一个高斯模型。
那么怎样决定究竟要聚类什么样的上下文呢?最普通的方法就是使用决策树。对于每一个音素的每一个状态都分别建立一棵树。首先把相同中心的三音素模型放到同一个根节点上。然后根据对上下文的提问,把当前的聚类分离成两个较小的聚类。在决策树中所提的问题是关于音素的左侧或者右侧是否具有某种语音特征。
决策树的如何训练出来呢?通过迭代的方式,决策树从根部开始自顶向下。在每一轮迭代时,算法要考虑树中每一个可能的问题q和每一个可能的结点n。对于每一个问题,算法要考虑新的分离对于训练数据的声学似然度的影响。如果由于问题q引起了被捆绑模型基础的分离,那么,算法要计算出训练数据的当前声学似然度与新的似然度之间的差别。算法选取给出最大似然度的结点n和问题q。不断迭代过程直到每一个叶子结点的实例数都达到最大的阈值为止。
为了训练依赖于上下文的模型,首先使用标准的嵌入式算法来训练独立于上下文的模型,多次使用EM算法,对于单音素的每一个次音素都形成不同的高斯模型,然后克隆每一个单音素模型到三音素模型。但是转移矩阵A不克隆(?),但是要把所有的三音素绑定在一起。再次运行EM迭代,再次训练三音素高斯模型。对于所有的单音素,使用决策树的聚类算法,把依赖于上下文的三音素都聚类,选择一个典型的状态作为类别的例子,其他状态与这个状态进行捆绑。
接下来训练高斯混合模型,首先使用嵌入式训练对上述的每一个捆绑的三音素状态训练一个单独的高斯混合模型,然后把每一个状态分离到两个等同的高斯模型中,使用某个$\epsilon$来干扰并调整每一个值,再次运行EM,对这些值再次进行训练,直到对于每一个状态中的观察,都得到一个恰当的高斯混合模型为止。
三音素kaldi代码
EventMap之EventType
决策树用于对三音素的状态进行绑定,在kaldi中使用什么数据表示三音素呢?
一种方法是使用一对数表示三音素的位置和该位置上的音素,C++表示就是pair<int,int>。另外除了知道三音素三个位置上的音素各是什么,我们还要知道一个HMM状态是三音素的第几个HMM状态,在表示三音素时使用一对数表示,在表示HMM状态的时候使用同样的方法,第一个int取-1则表示这对数是HMM状态信息,第二个数取HMM状态编号,表示这是该三音素第几个HMM状态。
表示三音素的三对数和表示HMM状态的一对数放在一起,可以描述特定三音素模型的某一HMM状态
typedef std::vector<std::pair<EventKeyType, EventValueType>> EventType
在这里EventKeyType和EventValueType只是对int32的重定义,当前音素是a(10)/b(11)/c(12)时,那么该三音素的第二个HMM状态为:
EventType e = {(-1,1),(0,10),(1,11),(2,12)}
什么是EventMap呢?EventMap是EventType到EventAnswerType的一个映射,其中EventAnswerType是一个int32的值表示pdf-id。我们知道每一个HMM状态都会关联一个概率密度函数,这个关联就是EventMap。EventMap::Map(EventType e, &EventAnswerType ans)返回bool并将pdf-id存到ans中,如果e没有对应任何pdf则返回false。
EventMap是一个纯虚类,它有三个具体的实现:
ConstantEventMap:可以看做决策树叶节点。此类存储EventAnswerType类型的整数,它的Map()函数始终是返回该值
SplitEventMap:可以看做决策树非叶节点,它查询某个键的值并根据答案转到True或False子节点。它的map函数调用相应子节点map函数,它存储的是一组答案为True的kAnswerType类型的整数。(除了存储的整数以外,剩余的是False)
TableEventMap:它对特定的键进行完全拆分。例如:我们可能首先完全对中间音素进行完全拆分之后对该音素的每一个值都有一个独立的决策树。在它的内部存储的是一个EventMap*指针的向量。它查找与拆分的键相对应的值,并在向量的相应位置调用eventmap的Map()函数
使用ConstantEventMap和SplitEventMap构成决策树,而TableEventMap去选择决策树
Clusterable和GuassClusterable
Clusterable是一个纯虚类,作为kaldi聚类机制的统一接口。在三音素决策树状态绑定这一块,我们主要用到的是继承自该类的GuassClusterable。
Clusterable对象的主要作用是把统计量累加在一起,和计算目标函数。两个Clusterable的距离用分别计算两个Clusterable的目标函数,然后再把两个Clusterable加起来计算目标函数,目标函数下降的负值就是两个Clusterable的距离。
在forced alignment之后,从左到右扫描对齐数据,我们从中得到(三音素及HMM状态)和其对应的特征向量,也就是得到一个EventType和其对应的特征向量。在扫描过所有训练数据后,出现每个EventType会对应多个特征向量。
在计算目标函数时,也就是状态集的似然L(S),根据L(S)的公式,我们需要知道状态机S产生的所有观测的协方差,对角协方差的对角线上是特征向量集每一维的方差,每一维方差就需要知道特征向量集的和以及特征向量集的平方和(D(X)=E(X2)-(EX)2);计算L(S)除了知道协方差还需要知道状态集S产生的特征向量的个数,也就是状态集S出现的次数,因为kaldi使用Viterbi训练,得到对齐后,我们就不需要计算posterior概率,可以用状态集S对应的特征向量的个数代替posterior概率。
于是,与一个EventType相关的统计量包括EventType对应的特征向量的个数、这些特征向量的累加、这些特征向量的平方的累加,这三个值,就是GuassClusterable中需要保存的统计量,根据这三个统计量可以计算该EventType的似然。如果把多个EventType的统计量累加到一起,可以计算这些EventType组成的状态集的似然,如果把多个EventType统计量累加在一起就可以计算这些EventType组成的状态集的似然。
在扫描对齐数据累积统计量时,一个EventType对应一个GaussClusterable对象。在这个GaussClusterable对象中,成员count_保存EventType出现的次数,stats_矩阵的第一行保存该EventType对应的所有特征向量的和,stats_矩阵的第二行保存着该EventType对应的所有特征向量的平方和
聚类算法
- RefineClustersOptions
- ClusterKMeansOptions
- TreeClusterOptions

BuildTreeStatsType
构建决策树时,我们需要知道的所有信息就是从训练数据的对齐中得到的所有EventType,和每个EventType对应的Clusterable对象,我们可以把这两者的对应关系保存在一对数据中pair<EventType, Clusterable*>,然后把所有的这些对保存成一个vector,所以构建决策树所用到的统计量可以表示成:
typedef std::vector<std::pair<EventType, Clusterable*>> BuildTreeStatsType
acc-tree-stats
作用:Accumulate statistic for phonetic-context tree building 该程序为决策树的构建累积相关统计量。
代码位置:kaldi-master/src/bin/acc-tree-stats
输入:声学模型、特征、对齐
输出:统计量(也就是BuildTreStatsType)
过程:输入的声学模型一般为单音素训练得到的GMM模型
- 打开声学模型并从中读取TransitionModel,打开特征文件、打开对齐文件,这里使用一个代码块来读取mdl文件,binary携带是否为二进制文件。使用SequentialBaseFloatMatrixReader来打开特征文件,使用RandomAccessInt32VectorReader来打开对齐文件
TransitionModel trans_model;
{
bool binary;
Input ki(model_filename, &binary);
trans_model.Read(ki.Stream(), binary);
}
SequentialBaseFloatMatrixReader feature_reader(feature_rspecifier);
RandomAccessInt32VectorReader alignment_reader(alignment_rspecifier);
- 对每一句话的特征和对应的对齐,调用程序AccumulateTreeStats()累积统计量tree_stats,tree_stats变量使用std::map<EventType,GaussClusterable*>用来构建决策树。逐条读入特征数据,检查该特征数据对应键值是否在对齐中(值得注意的是这里如果键值不再对齐中的话将继续读取下一个特征),如果在的话获取特征和对齐的状态,检查特征和对齐的维度是否相同,相同则调用AccumulateTreeStats计算累积量并将结果输出到tree_stats中
std::map<EventType, GuassClusterable*> tree_stats
AccumulateTreeStats(trans_model,
acc_tree_stats_info,
alignment,
mat,
&tree_stats)
- 将tree_stats转移到BuildTreeeStatsType类型的变量stats中,将stats写到文件JOB.treeacc,使用std::map生成的迭代器循环将tree_stats复制到BuildTreeStatsType中,并保存在std::pair<>数据类型保存。使用代码块输出到文件中,这里使用的binary是定义在函数的binary为true
{
Output ko(accs_out_wxfilename,binary);
WriteBuildTreeStats(ko.Stream, binary, stats);
}
工具使用方法:
acc-tree-stats $context_opts --ci-phones=$ciphonelist $alidir/final.mdl "$feats" \
"ark:gunzip -c $alidir/ali.JOB.gz|" $dir/JOB.treeaacc
AccumulateTreeStats()功能详解
该函数的实现是在hmm/tree-accu.cc中,先说它的函数定义
void AccumulateTreeStats(const TransitionModel &trans_model, //单因素模型
const AccumulateTreeStatsInfo &info, //参数
const std::vector<int32> &alignment, //一条特征序列对应的对齐状态
const Matrix<BaseFloat> &features, //一条特征序列
std::map<EventType, GaussClusterable*> *stats
在讲解这个函数前首先要介绍几个AccumulateTreeStatsInfo的参数
- phone_map 这是旧音素id到新音素id的映射
- context_width 上下文相关音素窗口大小
- central_position 窗口的中间位置
- ci_phone 上下文无关音素列表
主要功能: - 首先这个函数拿到单因素模型,对齐序列(transition_id序列),注意transition_id可以一对一的对应到一个HMM状态。使用(SplitToPhones())能够从transition_id得到对应的音素序列split_alignment
- 然后使用一个context_width大小的窗在split_alignment上滑动,并找出中间位置在对齐序列中的情况
- 从phone_map中获取新的中间音素的phone_id,并在ci_phone中查找,若未找到则证明该音素是上下文相关的
- 查找窗内所有音素的id号(超出对齐列表的使用0作为代替),并将id号和音素对应位置的二元组记录下来存入EventType
- 之后对于每一组三音素需要得到HMM状态id号,通过transition_id得到三音素的HMM状态id,从而得到一个个EventType。
- 经过排序后,使用AddStats()函数计算累计统计量,这个函数计算了每个EventType对应出现的次数,观测累和、观测平方累和该函数定义如下
void AddStats(
const VectorBase<BaseFloat>& vec,
BaseFloat weight=1.0
)
具体例子参照开拓师兄博客中的例子:

如何自动形成问题集
cluster_phone
- 作用:kaldi使用cluster_phone作为驱动形成问题集,对多个音素或多个音素集进行聚类
- 输入:决策树相关统计量treeacc,多个音素集文件sets.int
- 输出:自动生成的问题集questions.int
- 使用方法:
cluster-phones $context_opts $dir/treeacc $lang/phones/sets.int \
$dir/questions.int
- 过程:
- 从treeacc中读取统计量到BuildTreeStatsType stats;从pdf_class_list_str中读取pdf_class_list这是一个vector<int32>类型的变量用于指示考虑的HMM状态id号,默认只有1,也就是只考虑三个状态HMM的中间状态。从sets.int中读取phone_sets,默认三音素的参数为N=3(有3个音素组成),P=1(中间音素编号为1)
- 若指定的mode为questions调用AutomaticallyObtainQuestions()自动生成问题集 phone_sets_out;若指定的mode为k-means,调用KMeansClusterPhones(),具体详见论文《Tree-Based State Tying For High Accuracy Acoustic Modelling》
- 将上述函数自动生成的phone_sets_out写道questions.int中
- 输入文件输出文件:以下是sets.txt和 sets.int的截图,看到这个文件的形式我梦能对其有一个直观的印象,并且输出文件是同样的形式,只是每一行的内容有所改变


AutomaticallyObtainQuestion()
该函数是cluster_phone的核心函数,其主要功能是通过对音素自动聚类获得问题集;他把音素聚集为一个树,对树中的每个节点,把从该节点可以到达的所有叶子节点结合走一起构成一个音素集。该函数的定义如下:
void AutomaticallyObtainQuestions(
BuildTreeStatsType &stats,
const std::vector<std::vector<int32> > &phone_sets_in,
const std::vector<int32> &all_pdf_classes_in,
int32 P,
std::vector<std::vector<int32> > *questions_out
)
代码解读:
- 首先读取phone_sets_in中每一个音素集中的音素并保存在vector<int32> phones,phone_sets_in在驱动程序中由sets.int得到
- 使用FilterStatsByKey()函数把stats中只属于三音素第二个HMM状态的统计量留下。该函数的定义如下
void FilterStatsByKey (
const BuildTreeStatsType & stats_in,
EventKeyType key,
std::vector< EventValueType > & values,
bool include_if_present,
BuildTreeStatsType * stats_out
)
该函数通过特定键的值过滤统计量,当include_if_present为true的时候,输出特定键的值在values中的统计量,否则输出不在values中的统计量,那么为什么说是第二个HMM状态的值呢?这个就是由values决定的,在程序中是这样调用的
FilterStatsByKey(stats, kPdfClass, all_pdf_classes,
true, // retain only the listed positions
&retained_stats);
kPdfClass为-1指示的是HMM状态id,all_pdf_classes就是cluster-phones中的参数pdf_class_list,我们先前提到了它在默认情况下只有1,所以是第二个状态。输出为retained_stats
- 使用SplitStatsByKey(),根据三音素的中间音素对retained_stats进行划分,把属于每个音素的统计量放在一个BuildTreeStatsType中。该函数的定义如下:
void SplitStatsByKey(
const BuildTreeStatsType& stats_in
EventKeyType key,
std::vector<BuildTreeStatsType>* stats_out
)
这个函数的主要作用将按key对应的值的不同对统计量进行划分,在程序中,这个函数是这样调用的:
SplitStatsByKey(retained_stats, P, &split_stats);
我们前面提到P为1,所以例如我们音素集中共有215个音素,且这些些音素都出现在三音素的中间位置,则split_stats元素个数是215
- 使用SumStatsVec()把刚刚按中间音素进行划分的统计量加起来,得到每个中间音素的统计量,也就是输出summed_stats,该函数在函数内部通过循环调用SumStats将每个音素的统计量累加起来,该函数在程序中是这样调用的:
SumStatsVec(split_stats, &summed_stats);
- 到上一步为止,我们已经获得了每一个音素的统计量,为了计算聚类,我们还需要得到原本音素集的累积统计量,根据sets.int指定的集合,累加同一个集合中的音素的统计量,我们之前提到了sets.int中的数据形式,sets.int文件同一行的音素表示在一个音素集合中,我们最后得到的输出是summed_stats_per_set,它的维数就是sets.int的行数
std::vector<Clusterable*> summed_stats_per_set(phone_sets.size(), NULL);
for (size_t i = 0; i < phone_sets.size(); i++) {
const std::vector<int32> &this_set = phone_sets[i];
summed_stats_per_set[i] = summed_stats[this_set[0]]->Copy();
for (size_t j = 1; j < this_set.size(); j++)
summed_stats_per_set[i]->Add(*(summed_stats[this_set[j]]));
}
- 准备工作完成,到了真正开始聚类的时候,调用TreeCluster()对summed_stats_per_set进行聚类,生成一系列信息,对于这部分的讲解我们先往后搁搁,这个函数是这样调用的
TreeClusterOptions topts;
topts.kmeans_cfg.num_tries = 10; // This is a slow-but-accurate setting,
// we do it this way since there are typically few phones.
std::vector<int32> assignments; //assignment of phones to clusters. dim == summed_stats.size().
std::vector<int32> clust_assignments; // Parent of each cluster. Dim == #clusters.
int32 num_leaves; // number of leaf-level clusters.
TreeCluster(summed_stats_per_set,
summed_stats_per_set.size(), // max-#clust is all of the points.
NULL, // don't need the clusters out.
&assignments,
&clust_assignments,
&num_leaves,
topts);
- 最后的最后我们从上一步的结果中获取信息生成问题集。使用的函数是ObtainSetsOfPhones(),该函数定义方法如下:
static void kaldi::ObtainSetsOfPhones(
const std::vector<std::vector<int32>>& phone_sets//由sets.int生成
const std::vector<int32>& assignments//phone_sets中每个元素所属的cluster,上一步生成了树,每个phone_sets的元素都属于该树的一个叶子节点
const std::vector<int32>& clust_assignments//上一步生成的树的每个节点的父节点
int32 num_leaves//上一步生成树的叶子个数
std::vector<std::vector<int32>>* sets_out//生成的问题集
)
该函数执行过程为:首先得到每个cluster(叶子节点)中的音素集;将子节点的音素集加入到其父节点的音素集中;把原始的phone_set插入到问题集;过滤问题集的重复项、空项,生成最终的问题集。
TreeCluster()
该函数的定义如下:
BaseFloat TreeCluster(const std::vector<Clusterable*> &points,
int32 max_clust, // this is a max only.
std::vector<Clusterable*> *clusters_out,
std::vector<int32> *assignments_out,
std::vector<int32> *clust_assignments_out,
int32 *num_leaves_out,
TreeClusterOptions cfg)
程序中调用方法:
TreeClusterOptions topts;
topts.kmeans_cfg.num_tries = 10; // This is a slow-but-accurate setting,
// we do it this way since there are typically few phones.
std::vector<int32> assignments; //assignment of phones to clusters. dim == summed_stats.size().
std::vector<int32> clust_assignments; // Parent of each cluster. Dim == #clusters.
int32 num_leaves; // number of leaf-level clusters.
TreeCluster(summed_stats_per_set,
summed_stats_per_set.size(), // max-#clust is all of the points.
NULL, // don't need the clusters out.
&assignments,
&clust_assignments,
&num_leaves,
topts);
该函数其实只包含两行代码:
TreeClusterer tc(point, max_clust, cfg);
BaseFloat ans = tc.Cluster(clusters_out, assignments_out, clust_assignments_out, num_leaves_out)
kaldi将所有的聚类操作全部继承到一个类中,实现了程序之间的解耦合。首先初始化一个TreeCluster对象,把统计量points传给对象;然后调用该对象的Cluster方法获取关于聚类结果的相关信息。ObtainSetsOfPhones()根据这些信息就可以生成问题集。
TreeClusterer对象和Node数据结构
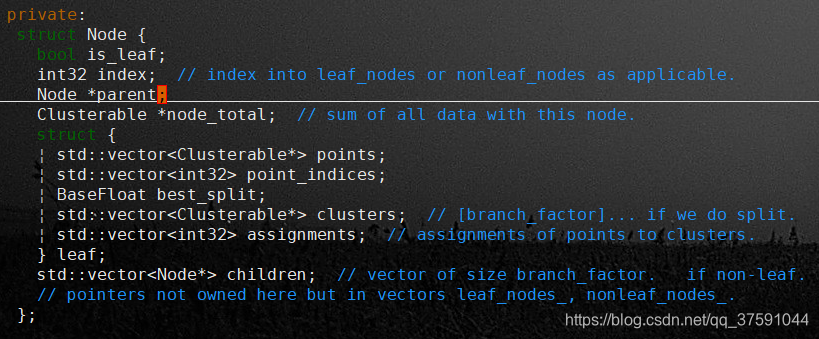
TreeClusterer是使用自顶向下的树进行聚类的一个对象。有树的地方就有节点Node,Node数据结构中保存了以下信息
-
Node保存着指向其父节点的指针parent。以及指向其儿子节点的指针children,注意到children是一个Node指针的vector,vector的大小由TreeClusterOptions中的branch_factor参数指定,这个值默认为2,所以我们这里使用的树是二叉树,每个节点最多只有两个孩子节点。
-
保存着属于该节点的所有统计量之和node_total(统计量就是该节点中的音素对应的所有特征向量的出现次数count_、特征向量之和stats_(0)、特征向量的平方和stats_(1),统计量用来计算该节点的似然L(s))
-
还保存着该节点是否是叶子节点,以及是叶子节点时在leaf_nodes中的索引和不是叶子节点时在nonleaf_nodes节点中
-
如果是叶子节点,保存着属于该叶子的那些点的统计量points,以及该叶子节点上拥有的那些点在所有点组成的vector上的索引(也就是在TreeClusterer对象point_成员中的索引)。用best_split保存着对该叶子节点进行最优划分时,获得的最大的似然提升。对该叶子节点划分意味着生成两个新的簇(或者说两个新的孩子节点),assignment中就保存着对该叶子节点进行最优划分后,该叶子节点中的点分别被划分到哪个簇,其元素值为0、1。
从这里我们就注意到了一件事,那就是统计量全部存储在叶子几点中,那么之前的一句话他把音素聚集为一个树,对树中的每个节点,把从该节点可以到达的所有叶子节点结合在一起构成一个音素集。
接着看一下TreeClusterer的数据成员有哪些














 2051
2051











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









