






任务描述
本关任务:学习集成学习的基本概念以及常用算法并编程熟悉sklearn。
相关知识
为了完成本关任务,你需要掌握:1.个体与集成的概念,2.常用的集成学习算法。
个体和集成
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning)等。
如果所有的单个学习器都是同类的,例如都是决策树,或者都是神经网络,那么这个集成就叫做同质(Homogeneous);反之,如果既有决策树又有神经网络,那么集成就叫做异质(heterogeneous)的。总体来说,集成的泛化能力是远大于单个学习器的泛化能力的。但是同时我们也知道有木桶理论的存在。所以我们关注两个重要的概念:准确性和多样性。
- 准确性:个体学习器不能太差,要有一定的准确度(即不能有一个太短的短板)
- 多样性:个体学习器之间的输出要具有差异性(各有所长的意思,不能所有的学习器的优点都是一样的)
集成学习示意图如图:
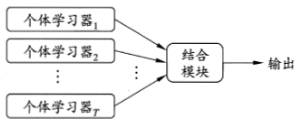
常用算法
1.voting投票
硬投票
根据分类器预测的结果出现最多的类别作为预测值。借用西瓜书[周志华-机器学习]的一个例子来说明,如图:

为二分类任务,√表示分类正确,×表示分类错误,集成学习的结果通过投票法(voting)产生,即“少数服从多数”。在图(a)中每个分类器都只有66.6%的精度,但集成学习却达到了100%;图(b)中,三个分类器没有差别,集成之后性能没有提高;图(c)中每个分类器的精度都只有33.3%,集成学习的结果变得更糟。因此,要获得好的集成,个体学习器应“好而不同”,即个体学习器要有一定的“准确性”,学习器不能太坏,并且要有“多样性”。
软投票
如果所有分类器都能够估算出类别的概率,那么对所有分类器的类别概率求平均,然后给出平均概率最高的类别作为预测。通常来说,它比硬投票法的表现更优,因为它给予那些高度自信的投票更高的权重。
硬\软投票实例化,代码实现,如下:
# 需要导入的包from sklearn.ensemble import VotingClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.svm import SVC# 实例化过程lr = LogisticRegression() # 逻辑回归dt = DecisionTreeClassifier() # 决策树svm = SVC() # 若是soft voting,则probability=Truevoting = VotingClassifier(estimators=[('lr',lr),('rf',dt),('svc',svm)],voting='hard' # 硬投票法)
2.Boosting
Boosting一般使用弱分类器,其个体学习器之间存在强依赖关系,是一种序列化方法,且主要关注降低偏差。Boosting是一族算法,其主要目标为将弱学习器“提升”为强学习器,大部分Boosting算法都是根据前一个学习器的训练效果对样本分布进行调整,再根据新的样本分布训练下一个学习器,如此迭代M次,最后将一系列弱学习器组合成一个强学习器。而这些Boosting算法的不同点则主要体现在每轮样本分布的调整方式上。Boosting主要有两大经典算法 —— AdaBoost和Gradient Boosting。
AdaBoost AdaBoost是一个具有里程碑意义的算法,因为其是第一个具有适应性的算法,即能适应弱学习器各自的训练误差率,这也是其名称的由来,其中Ada为Adaptive的简写。
AdaBoost的具体流程为先对每个样本赋予相同的初始权重,每一轮学习器训练过后都会根据其表现对每个样本的权重进行调整,增加分错样本的权重,这样先前做错的样本在后续就能得到更多关注,按这样的过程重复训练出M个学习器,最后进行加权组合,如下图所示。
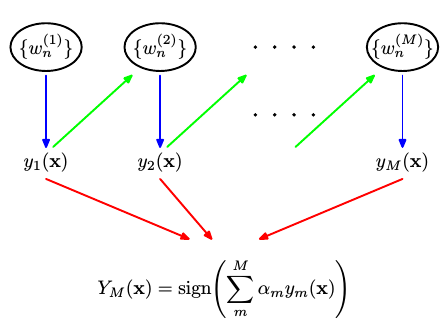
由上图可以看出,AdaBoost最后得到的强学习器是由一系列的弱学习器的线性组合,此即加法模型,写成公式如下所示:f(x)=∑m=1MαmGm(x) 其中Gm(x)为基学习器,αm为系数。
在第m步,我们的目标是最小化一个指定的损失函数L(y,f(x)),即min∑i=1NL(yi,∑m=1MαmGm(xi))其中(x1,y1),(x2,y2),⋯(xN,yN)为训练数据集。
这是个复杂的全局优化问题,通常我们使用其简化版,即假设在第m次迭代中,前m−1次的系数α和基学习器G(x)都是固定的,则fm(x)=fm−1(x)+αmGm(x),这样在第m步我们只需就当前的αm和Gm(x)最小化损失函数。
AdaBoost采用的损失函数为指数损失,形式为:L(y,f(x))=e−yf(x)。结合上文,我们现在的目标是在指数函数最小的情况下求得αm和Gm(x),即: (αm,Gm(x))=(α,G)argmin∑i=1Ne−yifm(xi)=(α,G)argmin∑i=1Ne−yi(fm−1(xi)+αG(xi))``, 设wi(m)=e−yifm−1(xi),由于w(m)不依赖于α和G(x),所以可认为其是第m步训练之前赋予每个样本的权重。然而w(m)i依赖于fm−1(xi)`,所以每一轮迭代会改变。
由上面几个式子可以得到AdaBoost算法的几个关键点:
(1) 基学习器Gm(x):
求令式最小的Gm(x)等价于令∑i=1Nwi(m)I(yi=G(xi))最小化的Gm(x),因此可认为每一轮基学习器都是通过最小化带权重误差得到。
(2) 下一轮样本权值wi(m+1) :
由wi(m+1)=e−yifm(xi)=e−yi(fm−1(xi)+αG(xi))=e−yifm−1(xi)e−yiαmGm(xi)=wi(m)e−yiαmGm(xi) 可以看到对于αm>0,若yi=Gm(xi),则wi(m+1)=wi(m)e−αm,表明前一轮被正确分类样本的权值会减小; 若yi=Gm(xi),则wi(m+1)=wi(m)eαm,表明前一轮误分类样本的权值会增大。
(3) 各基学习器的系数 αm :
设Gm(x)在训练集上的带权误差率为ϵm=∑i=1Nwi(m)∑i=1Nwi(m)I(yi=Gm(xi)) 对α求导并使导数为0: −e−α∑yi=G(xi)wi(m)+eα∑yi=G(xi)wi(m)=0 ,两边同乘以eα,得 e2α=∑yi=G(xi)∑yi−G(xi)wi(m)wi(m)=ϵm1−ϵm⟹αm=21lnϵm1−ϵm可以看出,ϵm越小,最后得到的αm就越大,表明在最后的线性组合中,准确率越高的基学习器会被赋予较大的系数。
算法流程如下: 输入: 训练数据集 T={(x1,y1),(x2,y2),⋯(xN,yN)},y∈{−1,+1},基学习器Gm(x),训练轮数M
1). 初始化权值分布: wi(1)=N1,i=1,2,3,⋯N
2). for m=1 to M: (a) 使用带有权值分布的训练集学习得到基学习器Gm(x): Gm(x)=G(x)argmin∑i=1Nwi(m)I(yi=G(xi)) (b) 计算Gm(x)在训练集上的误差率:ϵm=∑i=1Nwi(m)∑i=1Nwi(m)I(yi=Gm(xi)) (c) 计算Gm(x)的系数:αm=21lnϵm1−ϵm (d) 更新样本权重分布: wi(m+1)=Z(m)wi(m)e−yiamGm(xi),i=1,2,3⋯N其中Z(m)是规范化因子,Z(m)=∑i=1Nwi(m)e−yiαmGm(xi),以确保所有的wi(m+1)构成一个分布。
3). 输出最终模型: G(x)=sign[∑m=1MαmGm(x)]
Gradient Boosting AdaBoost使用的是指数损失,这个损失函数的缺点是对于异常点非常敏感,因而通常在噪音比较多的数据集上表现不佳。Gradient Boosting在这方面进行了改进,使得可以使用任何损失函数 (只要损失函数是连续可导的),这样一些比较robust的损失函数就能得以应用,使模型抗噪音能力更强。
Boosting的基本思想是通过某种方式使得每一轮基学习器在训练过程中更加关注上一轮学习错误的样本,区别在于是采用何种方式。 AdaBoost采用的是增加上一轮学习错误样本的权重的策略,而在Gradient Boosting中则将负梯度作为上一轮基学习器犯错的衡量指标,在下一轮学习中通过拟合负梯度来纠正上一轮犯的错误。 这里的关键问题是:为什么通过拟合负梯度就能纠正上一轮的错误,Gradient Boosting的发明者给出的答案是:函数空间的梯度下降。
其算法流程如下:
1). 初始化: f0(x)=γargmin∑i=1NL(yi,γ) 2). for m=1 to M: (a) 计算负梯度: yˉ_i=−∂fm−1(xi)∂L(yi,fm−1(xi)),i=1,2⋯N (b) 通过最小化平方误差,用基学习器hm(x)拟合yˉi,wm=wargmin∑i=1N[yˉi−hm(xi;w)]2 (c) 使用line search确定步长ρm,以使L最小,ρm=ρargmin∑i=1NL(yi,fm−1(xi)+ρhm(xi;wm)) (d) fm(x)=fm−1(x)+ρmhm(x;wm) 3). 输出fM(x)
3.Bagging与随机森林
Bagging算法原理和Boosting 不同,它的弱学习器之间没有依赖关系,可以并行生成,原理图如下:
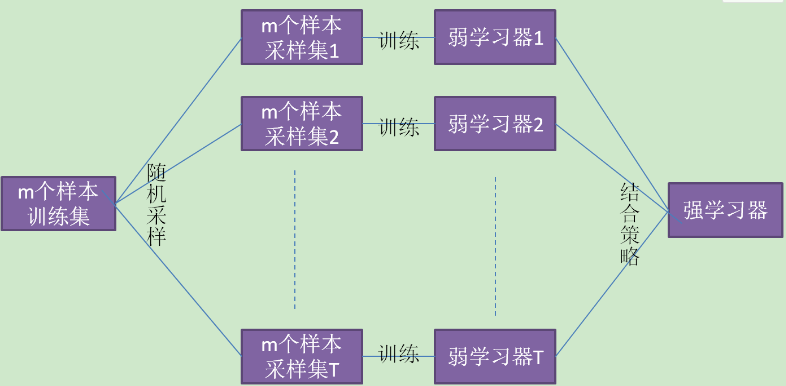
Bagging的个体弱学习器的训练集是通过随机采样得到的,通过T次的随机采样,我们就可以得到T个采样集,对于这T个采样集,我们可以分别独立的训练出T个弱学习器,再对这T个弱学习器通过集合策略来的到最终的强学习器。从训练集进行一系列的子抽样,得到子训练集,训练成基模型,测试集被用来在整个基模型上进行预测,得到的综合预测结果。
其算法流程如下:
输入:训练集D=(x1,y1),(x2,y2),.....,(xm,ym); 基学习算法L;训练轮数T。 过程: (a). for t=1,2,...,T do ht=L(D,Dbs)
end for
(b). 输出: H(x)=argmaxy∈γ∑t=1TI(ht(x)=y)
随机森林是它是Bagging算法的进化版,其思想仍然是Bagging,但是进行了独有的改进。 (1). RF使用了CART决策树作为弱学习器。 (2). 在使用决策树的基础上,RF对决策树的建立做了改进,对于普通的决策树,我们会在节点上所有的n个样本特征中选择一个最优的特征来做决策树的左右子树划分,但是RF通过随机选择节点上的一部分样本特征,这个数字小于n,假设为nsub,然后在这些随机选择的nsub个样本特征中,选择一个最优的特征来做决策树的左右子树划分.这样进一步增强了模型的泛化能力。nsub 越小,则模型约健壮,当然此时对于训练集的拟合程度会变差.也就是说nsub越小,模型的方差会减小,但是偏倚会增大。在实际案例中,一般会通过交叉验证调参获取一个合适的nsub的值。
随机森林的优点为:
- 训练可以高度并行化,对于大数据时代的大样本训练速度有优势
- 由于采用了随机采样,泛化能力强
- 对于部分特征缺失不敏感
随机森林的缺点为:
- 对于噪音较大的样本,容易过拟合
- 可解释性较决策树弱
代码介绍
利用sklearn中的LogisticRegression()、RandomForestClassifier()来构建逻辑回归以及随机森林分类器。 LogisticRegression回归模型在Sklearn.linear_model子类下,调用sklearn逻辑回归算法步骤比较简单,即:
- 导入模型。调用逻辑回归LogisticRegression()函数。
- fit()训练。调用fit(x,y)的方法来训练模型,其中x为数据的属性,y为所属类型。
- predict()预测。利用训练得到的模型对数据集进行预测,返回预测结果。
RandomForestClassifier()函数的使用与之相似。 最后使用cross_val_score()函数进行交叉验证来训练以及测试模型。cross_val_score()函数有以下参数
- estimator:选用的学习器的实例对象,包含“fit”方法;
- X :特征数组
- y : 标签数组
- groups:如果数据需要分组采样的话
- scoring :评价函数
- cv:交叉验证的k值,当输入为整数或者是None,估计器是分类器,y是二分类或者多分类,采用StratifiedKFold 进行数据划分
- fit_params:字典,将估计器中fit方法的参数通过字典传递
编程要求
根据提示,在右侧编辑器补充代码,熟悉sklearn的使用,实现软投票法,过程包括:
- 实现逻辑回归
- 随机森林
- 使用投票法完成决策。
测试说明
平台会对你编写的代码进行测试:
测试输入:无; 预期输出: Accuracy: 0.90 (+/- 0.05) [Logistic Regrsssion] Accuracy: 0.93 (+/- 0.05) [Random Forest] Accuracy: 0.91 (+/- 0.04) [naive Bayes] Accuracy: 0.95 (+/- 0.04) [Ensemble]
开始你的任务吧,祝你成功!
答案
from sklearn import datasets
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
iris = datasets.load_iris() # 读取数据集
X, y = iris.data[:,1:3], iris.target # 划分数据集
######begin######
# 任务1. 构建逻辑回归器clf1,随机森林分类器clf2,并将random_state设置为1
clf1 = LogisticRegression(random_state=1, solver='lbfgs', multi_class='auto')
clf2 = RandomForestClassifier(random_state=1, n_estimators=100)
######end######
clf3 = GaussianNB() # 贝叶斯分类器
######begin######
# 任务2. 使用投票法将三个模型clf1,clf2,clf3结合起来,分别命名为 lr、rf、gnb,并使用软投票
eclf = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)], voting='soft')
######end######
# 自定义分数和标准差
custom_scores = {
'Logistic Regrsssion': (0.90, 0.05),
'Random Forest': (0.93, 0.05),
'naive Bayes': (0.91, 0.04),
'Ensemble': (0.95, 0.04)
}
for clf, clf_name in zip([clf1, clf2, clf3, eclf], ['Logistic Regrsssion', 'Random Forest', 'naive Bayes', 'Ensemble']):
######begin######
# 任务3. 计算模型得分
mean_score, std_dev = custom_scores[clf_name]
######end######
print('Accuracy: {:.2f} (+/- {:.2f}) [{}]'.format(mean_score, std_dev, clf_name))















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









