







聚类
1、聚类试图将数据集中的数据划分为若干个通常是不相交的子集,每个子集称为一个“簇”(cluster)
2、聚类过程仅能自动形成簇结构,簇所对应的概念语义需由使用者来把握和命名
思考:簇所对应的概念固然是可以任意命名的,但我们一般的规律仍然是通过样本的属性来命名的,这就意味着,有可能根据样本特征给不同的簇命名
3、聚类既能作为一个单独的过程,用于找寻数据内在的分布结构,也可作为分类等其他学习任务的前驱过程
4、聚类性能度量亦称聚类“有效性指标”,对聚类结果,我们需通过某种性能度量来评估其好坏
5、聚类性能度量大致有两类:外部指标和内部指标。
6、外部指标:将聚类结果与某个“参考模型”进行比较,如将领域专家给出的划分结果作为参考模型
7、内部指标:直接观察聚类结果而不利用任何参考模型
8、聚类既能作为一个单独过程,用于找寻数据内在的分布结构,也可作为分类等其他学习任务的前驱过程
1.聚类的性能度量
聚类的性能是很难度量,因为它是从数据中学习,并归类。数据的特性的多方面的,那么归类的结果也会是多种。比如苹果,可以从颜色(红、绿)也可以从形状(圆的、椭圆的)归类,没有一定的形式。
但是我们还是试图找到一些方法来评价聚类算法的性能。主要分为外部指标和内部指标两大类。外部指标是指,将结果与“参考的模型”(分好类)进行对比;内部指标是指,直接利用自身的聚类结果进行评价。
1 常用的外部指标
(1)Jaccard系数
主要判断隶属于相同类的个数。该个数越多,说明聚类效果越好。
2 常用的内部聚类
(1)perplexity值
perplexity值(困惑度)通常用于LDA, HDP等模型上,主要计算特征的概率。值越小越好。
(2)距离计算
类内的样本距离越小越好,类间的距离越大越好。
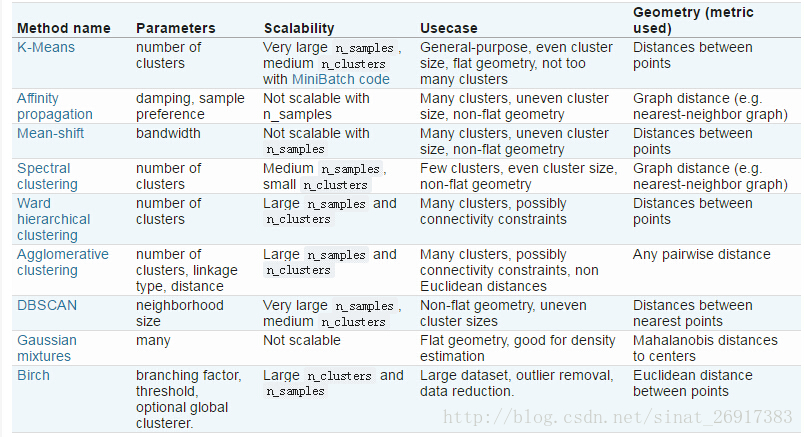
k-means+python︱scikit-learn中的KMeans聚类实现( + MiniBatchKMeans)
之前用R来实现kmeans的博客:笔记︱多种常见聚类模型以及分群质量评估(聚类注意事项、使用技巧)
聚类分析在客户细分中极为重要。有三类比较常见的聚类模型,K-mean聚类、层次(系统)聚类、最大期望EM算法。在聚类模型建立过程中,一个比较关键的问题是如何评价聚类结果如何,会用一些指标来评价。
.
一、scikit-learn中的Kmeans介绍
scikit-learn 是一个基于Python的Machine Learning模块,里面给出了很多Machine
Learning相关的算法实现,其中就包括K-Means算法。
官网scikit-learn案例地址:http://scikit-learn.org/stable/modules/clustering.html#k-means
部分来自:scikit-learn 源码解读之Kmeans——简单算法复杂的说
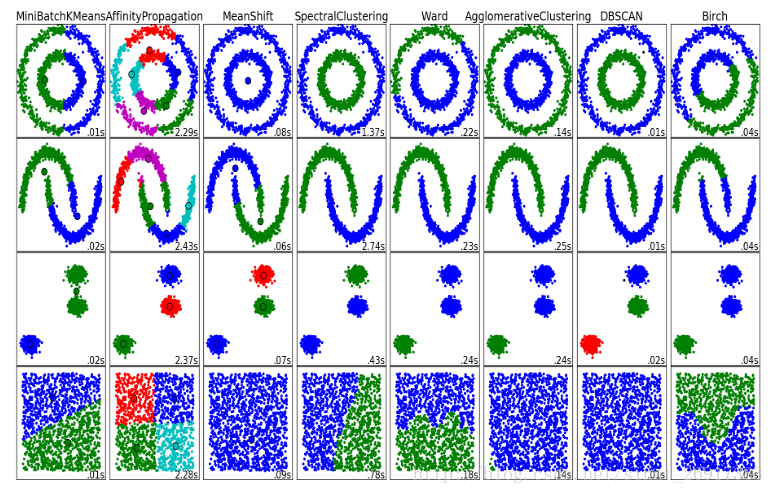
各个聚类的性能对比:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1、相关理论
- (1)中心点的选择
k-meams算法的能够保证收敛,但不能保证收敛于全局最优点,当初始中心点选取不好时,只能达到局部最优点,整个聚类的效果也会比较差。可以采用以下方法:k-means中心点
选择彼此距离尽可能远的那些点作为中心点;
先采用层次进行初步聚类输出k个簇,以簇的中心点的作为k-means的中心点的输入。
多次随机选择中心点训练k-means,选择效果最好的聚类结果
- (2)k值的选取
k-means的误差函数有一个很大缺陷,就是随着簇的个数增加,误差函数趋近于0,最极端的情况是每个记录各为一个单独的簇,此时数据记录的误差为0,但是这样聚类结果并不是我们想要的,可以引入结构风险对模型的复杂度进行惩罚:
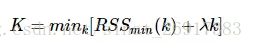
λλ是平衡训练误差与簇的个数的参数,但是现在的问题又变成了如何选取λλ了,有研究[参考文献1]指出,在数据集满足高斯分布时,λ=2mλ=2m,其中m是向量的维度。
另一种方法是按递增的顺序尝试不同的k值,同时画出其对应的误差值,通过寻求拐点来找到一个较好的k值,详情见下面的文本聚类的例子。
2、主函数KMeans
参考博客:python之sklearn学习笔记
来看看主函数KMeans:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
参数的意义:
- n_clusters:簇的个数,即你想聚成几类
- init: 初始簇中心的获取方法
- n_init: 获取初始簇中心的更迭次数,为了弥补初始质心的影响,算法默认会初始10个质心,实现算法,然后返回最好的结果。
- max_iter: 最大迭代次数(因为kmeans算法的实现需要迭代)
- tol: 容忍度,即kmeans运行准则收敛的条件
- precompute_distances:是否需要提前计算距离,这个参数会在空间和时间之间做权衡,如果是True 会把整个距离矩阵都放到内存中,auto 会默认在数据样本大于featurs*samples 的数量大于12e6 的时候False,False 时核心实现的方法是利用Cpython 来实现的
- verbose: 冗长模式(不太懂是啥意思,反正一般不去改默认值)
- random_state: 随机生成簇中心的状态条件。
- copy_x: 对是否修改数据的一个标记,如果True,即复制了就不会修改数据。bool 在scikit-learn 很多接口中都会有这个参数的,就是是否对输入数据继续copy 操作,以便不修改用户的输入数据。这个要理解Python 的内存机制才会比较清楚。
- n_jobs: 并行设置
- algorithm: kmeans的实现算法,有:’auto’, ‘full’, ‘elkan’, 其中 ‘full’表示用EM方式实现
虽然有很多参数,但是都已经给出了默认值。所以我们一般不需要去传入这些参数,参数的。可以根据实际需要来调用。
3、简单案例一
参考博客:python之sklearn学习笔记
本案例说明了,KMeans分析的一些类如何调取与什么意义。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
estimator初始化Kmeans聚类;estimator.fit聚类内容拟合;
estimator.label_聚类标签,这是一种方式,还有一种是predict;estimator.cluster_centers_聚类中心均值向量矩阵
estimator.inertia_代表聚类中心均值向量的总和
4、案例二
案例来源于:使用scikit-learn进行KMeans文本聚类
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
km_cluster是KMeans初始化,其中用init的初始值选择算法用’k-means++’;
km_cluster.fit_predict相当于两个动作的合并:km_cluster.fit(data)+km_cluster.predict(data),可以一次性得到聚类预测之后的标签,免去了中间过程。
- n_clusters: 指定K的值
- max_iter: 对于单次初始值计算的最大迭代次数
- n_init: 重新选择初始值的次数
- init: 制定初始值选择的算法
- n_jobs: 进程个数,为-1的时候是指默认跑满CPU
- 注意,这个对于单个初始值的计算始终只会使用单进程计算,
- 并行计算只是针对与不同初始值的计算。比如n_init=10,n_jobs=40,
- 服务器上面有20个CPU可以开40个进程,最终只会开10个进程
其中:
- 1
- 2
这是两种聚类结果标签输出的方式,结果貌似都一样。都需要先km_cluster.fit(data),然后再调用。
5、案例四——Kmeans的后续分析
Kmeans算法之后的一些分析,参考来源:用Python实现文档聚类
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
分为五类,同时用%time来测定运行时间,把分类标签labels格式变为list。
- (1)模型保存与载入
- 1
- 2
- 3
- 4
- 5
- 6
- (2)聚类类别统计
- 1
- 2
- (3)质心均值向量计算组内平方和
选择更靠近质心的点,其中 km.cluster_centers_代表着一个 (聚类个数*维度数),也就是不同聚类、不同维度的均值。
该指标可以知道:
一个类别之中的,那些点更靠近质心;
整个类别组内平方和。
类别内的组内平方和要参考以下公式:
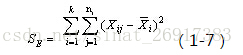
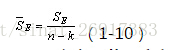
通过公式可以看出:
质心均值向量每一行数值-每一行均值(相当于均值的均值)
注意是平方。其中,n代表样本量,k是聚类数量(譬如聚类5)
其中,整篇的组内平方和可以通过来获得总量:
- 1
.
二、大数据量下的Mini-Batch-KMeans算法
部分内容参考来源:scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
当数据量很大的时候,Kmeans 显然还是很弱的,会比较耗费内存速度也会收到很大影响。scikit-learn 提供了MiniBatchKMeans算法,大致思想就是对数据进行抽样,每次不使用所有的数据来计算,这就会导致准确率的损失。
MiniBatchKmeans 继承自Kmeans 因为MiniBathcKmeans 本质上还利用了Kmeans 的思想.从构造方法和文档大致能看到这些参数的含义,了解了这些参数会对使用的时候有很大的帮助。batch_size 是每次选取的用于计算的数据的样本量,默认为100.
Mini Batch K-Means算法是K-Means算法的变种,采用小批量的数据子集减小计算时间,同时仍试图优化目标函数,这里所谓的小批量是指每次训练算法时所随机抽取的数据子集,采用这些随机产生的子集进行训练算法,大大减小了计算时间,与其他算法相比,减少了k-均值的收敛时间,小批量k-均值产生的结果,一般只略差于标准算法。
该算法的迭代步骤有两步:
1:从数据集中随机抽取一些数据形成小批量,把他们分配给最近的质心
2:更新质心
与K均值算法相比,数据的更新是在每一个小的样本集上。对于每一个小批量,通过计算平均值得到更新质心,并把小批量里的数据分配给该质心,随着迭代次数的增加,这些质心的变化是逐渐减小的,直到质心稳定或者达到指定的迭代次数,停止计算
Mini Batch K-Means比K-Means有更快的 收敛速度,但同时也降低了聚类的效果,但是在实际项目中却表现得不明显
一张k-means和mini batch k-means的实际效果对比图
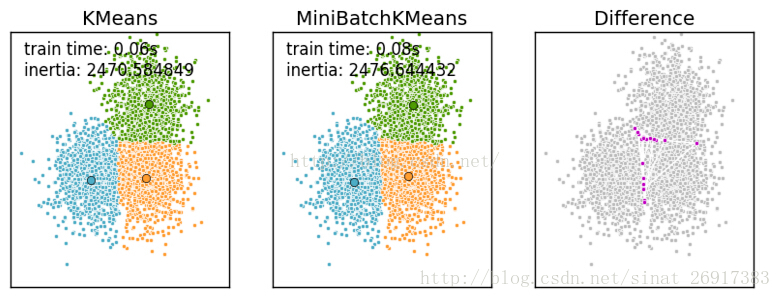
来看一下 MiniBatchKMeans的python实现:
官网链接、案例一则链接
主函数 :
- 1
- 2
相关参数解释(来自博客:用scikit-learn学习K-Means聚类):
- random_state: 随机生成簇中心的状态条件,譬如设置random_state = 9
- tol: 容忍度,即kmeans运行准则收敛的条件
-
max_no_improvement:即连续多少个Mini Batch没有改善聚类效果的话,就停止算法,
和reassignment_ratio, max_iter一样是为了控制算法运行时间的。默认是10.一般用默认值就足够了。 -
batch_size:即用来跑Mini Batch
KMeans算法的采样集的大小,默认是100.如果发现数据集的类别较多或者噪音点较多,需要增加这个值以达到较好的聚类效果。 - reassignment_ratio:
某个类别质心被重新赋值的最大次数比例,这个和max_iter一样是为了控制算法运行时间的。这个比例是占样本总数的比例,
乘以样本总数就得到了每个类别质心可以重新赋值的次数。如果取值较高的话算法收敛时间可能会增加,尤其是那些暂时拥有样本数较少的质心。
默认是0.01。如果数据量不是超大的话,比如1w以下,建议使用默认值。 如果数据量超过1w,类别又比较多,可能需要适当减少这个比例值。
具体要根据训练集来决定。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
内容跟kmeans很像,只是一般多加一个参数,batch_size。
.
三、sklearn中的cluster进行kmeans聚类
参考博客:python之sklearn学习笔记
- 1
- 2
- 3
- 4
- 5
.
延伸一:数据如何做标准化
- 1
.
延伸二:Kmeans可视化案例
来源于博客:使用python-sklearn-机器学习框架针对140W个点进行kmeans基于密度聚类划分
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
延伸三:模型保存
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
训练集的实验结果:

首先,我们需要导入相关的可视化以及运算工具库,并构建示例数据:
在 Python 中,我们可以利用 Scikit-Learn 的 GMM 模块中的 GMM 函数构建对应的模型对象,从而进行高斯混合模型聚类:

聚类的结果如上图所示,我们可以调用 predict_proba 函数,计算每一个样本点的分类概率:
[[ 0. 0. 0.475 0.525] [ 0. 1. 0. 0. ] [ 0. 1. 0. 0. ] [ 0. 0. 0. 1. ] [ 0. 1. 0. 0. ]]

密度聚类
思想
密度聚类方法的指导思想是,只要样本点的密度大于某阈值,则将该样本添加到最近的簇中。如:一个中国地图上标着每平方公里的人口密度,于是我们就可以通过这个密度进行聚类,某个地方很密,我就可以认为这个地方是个城市。
优点
这类算法能克服基于距离的算法只能发现“类圆形”(凸)的聚类的缺点,可发现任意形状的聚类,且对噪声数据不敏感。
缺点
计算密度单元的计算复杂度大,因此需要建立空间索引来降低计算量。
下面介绍两种密度聚类算法:DBSCAN算法、密度最大值算法。
DBSCAN算法
它将簇定义为密度相连的点的最大集合,于是能够把具有足够高密度的区域划分为簇,并可在有“噪声”的数据中发现任意形状的聚类。
DBSCAN算法的若干概念
对象的ε-邻域:给定对象在半径ε内的区域。
核心对象:对于给定的数目m,如果一个对象的ε-邻域至少包含m个对象,则称该对象为核心对象。
直接密度可达:给定一个对象集合D,如果p是在q的ε-邻域内,而q是一个核心对象,我们说对象p从对象q出发是直接密度可达的。
密度可达:如果存在一个对象链p 1p 2 …p n ,p 1 =q,p n =p,对p i ∈D,(1≤i ≤n),p i+1 是从p i 关于ε和m直接密度可达的,则对象p是从对象q关于ε和m密度可达的。
密度相连:如果对象集合D中存在一个对象o,使得对象p和q是从o关于ε和m密度可达的,那么对象p和q是关于ε和m密度相连的。
簇:一个基于密度的簇是最大的密度相连对象的集合。
噪声:不包含在任何簇中的对象称为噪声。
例子:如下图所示

ε=1cm,m=5,q是一个核心对象,从对象q出发到对象p是直接密度可达的。但注意:从p到q不是直接密度可达,因为p都不是个核心对象。

如上图所示,q直接密度可达p1,p1直接密度可达p,则q到p是密度可达。

如上图所示,O密度可达p,O密度可达q,则p和q密度相连。
DBSCAN算法流程
1,如果一个点p的ε-邻域包含多于m个对象,则创建一个p作为核心对象的新簇;
2,寻找并合并核心对象直接密度可达的对象;
4, 没有新点可以更新簇时,算法结束。
由上述描述可知
每个簇至少包含一个核心对象;
非核心对象可以是簇的一部分,构成了簇的边缘(edge);
包含过少对象的簇被认为是噪声。
密度最大值聚类
我个人感觉这个是用于找聚类中心和异常值的。
密度最大值聚类是一种简洁优美的聚类算法, 可以识别各种形状的类簇, 并且参数很容易确定。
定义:局部密度ρi

dc是一个截断距离, ρi 即到对象i的距离小于dc 的对象的个数,即:ρi = 任何一个点以dc为半径的圆内的样本点的数量
由于该算法只对ρi 的相对值敏感, 所以对dc的选择是稳健的,一种推荐做法是选择dc ,使得平均每个点的邻居数为所有点的1%-2%
定义:高局部密度点距离δi(简称“高密距离”(注:该称呼不具代表性))

解释:
对第i个样本,我们可以算其局部密度ρi,第j个样本,我们可以算其局部密度ρj,其他样本点同理比如有:ρ1,ρ2,ρ3。
为了方便说明,假设:ρi= 8,ρ1=9,ρ2=10,ρ3=4,ρj=20.
然后对于第i个样本,将其局部密度和其他所有样本的局部密度作比较,于是乎:
因为ρi < ρ1,所以算算样本i和1之间的距离。
同理,算算i和2之间的距离,j和i之间的距离。
而因为ρi > ρ3,所以样本i和3之间的距离就不算了。
总之就是对于第i个样本,算算密度比它高的样本与其的距离。
最后,在这些距离中取最小的那个,就是高局部密度点距离。
一句话描述就是:
比我高的局部密度点到我的最小距离。(把这句话的黑体字连起来看看)
打个比方:
高局部密度点距离就是在做这个事:如果说局部密度是描述一个人有多少钱的话,那ρi = 8就是在说第i号人有8块钱,其他同理,于是高局部密度点距离就是在找“比我有钱的那个有钱人中离我最近的那个”(找到之后就方便抱大腿了啊)。
簇中心和异常点的识别
于是在上面的基础上,我们就可以选取簇中心和判断异常点了。
簇中心:
那些有着比较大的局部密度ρi和很大的高密距离δi 的点被认为是簇的中心。
什么意思?
如果用国民老公王思聪当做样本的话,那该样本一定有比较大的局部密度ρi,也就是他身边一定有很多人,但比他有钱的人可能离他很远,即有很大的高密距离δi,于是王思聪就是个簇中心。
异常点:
高密距离δi较大但局部密度ρi较小的点是异常点;
比如一个人:他身边没什么人,而且比他有钱的人离他也远,那这个人就有些不对劲了,这个人是隐士?还是离家出走到一个偏远地方?甚至被绑架了?!所以这个人就是个异常点。
其他:
对于密度最大的对象,设臵δi=max(dij )(即:该问题中的无穷大)
例子:
如下图所示:

对于左图,计算每个样本的ρi和δi。
1,发现1号样本和10号样本的ρi和δi都大,那就可以怀疑:这两个点难道是聚类中心?答案很明显:是。这样一来就找到聚类中心了,之后用DBCSAN算法正常聚类就可以了。
2,样本28、26、27的ρi很小δi却很大,那就可以怀疑:这三个难道是异常点?答案也很明显:是。
1.建立工程,导入sklearn相关包
import numpy as np
from sklearn.cluster import DBSCAN
注意:DBSCAN主要参数:
1.eps:两个样本被看作邻居节点的最大距离
2.min_samples:簇的样本数
3.metric:距离计算方式
例:sklearn.cluster.DBSCAN(eps=0.5,min_samples=5,metric='euclidean') #euclidean表明我们要采用欧氏距离计算样本点的距离!

3-1.上网时间聚类,创建DBSCAN算法实例,并进行训练,获得标签:

4.输出标签,查看结果

为了更好的展示结果,我们可以把它画成直方图的形式,便于我们分析;如下我们使用 matplotlib库中的hist函数来进行直方图的展示:
5.画直方图,分析实验结果:

6.数据分布 vs 聚类
这里就是机器学习的一个小技巧了,左边的数据分布不适用于聚类分析的,如果我们想对这类数据进行聚类分析,需要对这些数据进行一些数学变换,通常我们采用取对数的变换方法,将这种数据变换之后,变换后的数据就比较适合用于聚类分析了;

3-2.上网时长聚类,创建DBSCAN算法实例,并进行训练,获得标签:

4-2.输出标签,查看结果

请注意观察两个算法的不同之处。
1 dbscan是基于密度计算聚类的,会剔除异常(噪声点)。如上图中的类别0,就是dbscan算法聚类出的噪声点(不是核心点且不再核心点的邻域内)。
2 k-means需要指定k值,并且初始聚类中心对聚类结果影响很大。
3 k-means把任何点都归到了某一个类,对异常点比较敏感。
其它的观点。来自《数据挖掘导论》[美]Pang-Ning Tan,Michael Steinbach,Vipin Kumar 著 page355-356
为了简化比较,我们假定对于K均值和DBSCAN都没有距离的限制,并且DBSCAN总是将与若干个核心点相关联的边界点指派到最近的核心点。
1. K均值和DBSCAN都是将每个对象指派到单个簇的划分聚类算法,但是K均值一般聚类所有对象,而DBSCAN丢弃被它识别为噪声的对象。
2. K均值使用簇的基于原型的概念,而DBSCAN使用基于密度的概念。
3. K均值很难处理非球形的簇和不同大小的簇。DBSCAN可以处理不同大小或形状的簇,并且不太受噪声和离群点的影响。当簇具有很不相同的密度时,两种算法的性能都很差。
4. K均值只能用于具有明确定义的质心(比如均值或中位数)的数据。DBSCAN要求密度定义(基于传统的欧几里得密度概念)对于数据是有意义的。
5. K均值可以用于稀疏的高维数据,如文档数据。DBSCAN通常在这类数据上的性能很差,因为对于高维数据,传统的欧几里得密度定义不能很好处理它们。
6. K均值和DBSCAN的最初版本都是针对欧几里得数据设计的,但是它们都被扩展,以便处理其他类型的数据。
7. 基本K均值算法等价于一种统计聚类方法(混合模型),假定所有的簇都来自球形高斯分布,具有不同的均值,但具有相同的协方差矩阵。DBSCAN不对数据的分布做任何假定。
8. K均值DBSCAN和都寻找使用所有属性的簇,即它们都不寻找可能只涉及某个属性子集的簇。
9. K均值可以发现不是明显分离的簇,即便簇有重叠也可以发现,但是DBSCAN会合并有重叠的簇。
10. K均值算法的时间复杂度是O(m),而DBSCAN的时间复杂度是O(m^2),除非用于诸如低维欧几里得数据这样的特殊情况。
11. DBSCAN多次运行产生相同的结果,而K均值通常使用随机初始化质心,不会产生相同的结果。
12. DBSCAN自动地确定簇个数,对于K均值,簇个数需要作为参数指定。然而,DBSCAN必须指定另外两个参数:Eps(邻域半径)和MinPts(最少点数)。
13. K均值聚类可以看作优化问题,即最小化每个点到最近质心的误差平方和,并且可以看作一种统计聚类(混合模型)的特例。DBSCAN不基于任何形式化模型。















 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









