







排序
常用排序算法
9种常用排序算法及其关系如图所示:

下面以从小到大排序为例详解9种排序。
冒泡排序&选择排序
从未排序的元素中选出最小的放在已排序元素的末尾,逐步确定第n小元素,如图:
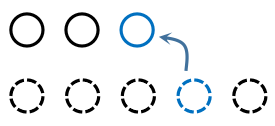
冒泡排序
思路:逐个交换
为了选取未排序元素中的最大元素(已排序元素向前插入,故需寻找最大元素),我们遍历未排序元素,如果发现下一个元素更小,则将二者交换,被换至已排序元素末尾的一定是未排序元素中的最大元素,如图:

优点:具有稳定性
略证:设两相同元素为 a , a ′ a,a' a,a′,有两种情况:
1. a , a ′ a,a' a,a′不是最大元素:设此时最大元素为 b b b,则有三种情况:
① b , a , a ′ b,a,a' b,a,a′:交换后 a a a被换至 a a a前一个位置, a ′ a' a′被换至 a ′ a' a′前一个位置,相对位置不变;
② a , b ′ , a ′ a,b',a' a,b′,a′: a a a位置不变或换至 a a a前一个位置, a ′ a' a′被换至 a ′ a' a′前一个位置,相对位置不变;
③ a , a ′ , b a,a',b a,a′,b: a , a ′ a,a' a,a′位置不变或被换至各自的前一个位置,相对位置不变;
2. a , a ′ a,a' a,a′是最大元素:交换后 a a a位置不变, a ′ a' a′放入已排序元素中;下一次排序时 a a a放入已排序元素中,此时已排序元素左端为 a , a ′ a,a' a,a′,相对位置不变。
即证冒泡排序具有稳定性。
连续性交换保留稳定性,跳跃性交换破化稳定性
缺点:交换次数过多
实现:
for (int i = 0; i < n - 1; i++) // 冒完n-1次后,a[0]即最小元素
for (int j = 0; j < n - i - 1; j++) // 后i个元素已经排好序
if (a[j + 1] < a[j]) swap(a[j + 1], a[j]);
选择排序
思路:空间换时间
为了减少交换次数,先找到未排序元素中最小元素的下标位置,然后直接与已排序元素的末尾交换,如图:

缺点:不具有稳定性
反例:如12 5 1 5_1 51 5 2 5_2 52 3,此时 5 1 5_1 51与3发生交换,顺序变为… 5 2 5_2 52 5 1 5_1 51
实现:
for (int i = 0; i < n - 1; i++) { // 选完n-1次后,a[n-1]即最大元素
min = i;
for (int j = i + 1; j < n; j++) // 前i个元素已经排好序
if (a[j] < a[min]) min = j;
swap(a[i], a[min]);
}
插入排序
思路:先放后调
将未排序元素逐个放入已排序元素末尾,放入后再将放入的元素交换至相应位置,如图:

由于前i个元素已经排好顺序,所以一旦换到对应位置后即可停止交换;交换过程中两个已排序元素间不会发生交换。
优点:具有稳定性
略证:相同元素按照原始顺序被放入已排序元素中,后进入的元素仍位于先进入的元素后方
实现:
for (int i = 1; i < n; i++) { // 初始时a[0]为有序元素
cur = a[i], j = i; // 已排序元素不进行交换,故只需考虑新插入元素
while (j && a[j - 1] > cur) a[j] = a[j - 1], j--; // 此处不能简写为a[--j],影响赋值操作
a[j] = cur;
}
快速排序&归并排序
在递归进行过程中完成对数据的排序,利用跳跃式交换减少交换次数。
快速排序
思路:分治(递)
选定基准值,将当前序列分为三段,即 小于基准值|基准值|大于基准值,接着对小于基准值和大于基准值的两段继续分段,直至待分段序列长度为1时达到边界。
返回的子序列已经为有序序列,而小于基准值的有序序列和大于基准值的有序序列正好组成更大的有序序列,仍保证当前处理的序列有序,故直接返回即可。
因此,快速排序在递的过程中已经完成了排序,如图:

①边界: l = = r l==r l==r时序列长度为1,已经有序
②递:将序列分为三段
下面就划分序列的两种方法给出不同的实现。
思路1:两头移动 ( H o a r e ) (Hoare) (Hoare)

实现: 3-while
void qsort(int l, int r) {
if (l >= r) return; // 1.
int key = a[l], i = l, j = r;
while (i < j) {
while (a[j] >= key && i < j) j--; // 2.
while (a[i] <= key && i < j) i++;
if (i < j) swap(a[i], a[j]); // 3.
}
swap(a[l], a[i]);
qsort(l, i - 1);
qsort(i + 1, r);
}
细节:
1.需判断 l > r l>r l>r的情况:当基准值为序列最小或最大值时,子序列变为[0,-1]或[r+1,r]
2.基准值在 l l l处选择,故应先移动 j j j,否则当基准值为序列最小值时, i i i会先发生偏移,而后 i , j i,j i,j会合,交换后最小基准值并不位于序列前端,如图:
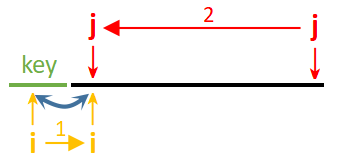
更一般的,最后一次当 i i i先抵达时, a [ i ] > k e y a[i]>key a[i]>key,位于大于基准值区域,无法与 a [ l ] a[l] a[l]交换
3.当 i = = j i==j i==j时,无需再次调换,直接将key换入即可
思路2.一头移动 ( L o m u t o ) (Lomuto) (Lomuto)

实现:for
void qsort(int l, int r) {
if (l >= r) return;
int key = a[l], j = l + 1; // 1.
for (int i = j; i <= r; i++)
if (a[i] < key) swap(a[i], a[j++]); // 先交换,后移动
swap(a[l], a[--j]); // 先移动,后交换
qsort(l, j - 1);
qsort(j + 1, r);
}
细节:
1.选定 a [ l ] a[l] a[l]为key时, a [ l ] ⩽ k e y a[l]\leqslant key a[l]⩽key可直接划入 ⩽ k e y \leqslant key ⩽key区域,故 i , j i,j i,j初值为 l + 1 l+1 l+1
优化:随机化
划分的时间花费为 O ( n ) O(n) O(n),为了保证复杂度为 O ( n l o g n ) O(nlogn) O(nlogn),我们希望每次分割时都能使区间长度缩小至原来的一半。
区间分割取决于基准值的选择,我们可以随机选择基准值 a [ p ] ( l ⩽ p ⩽ r ) a[p](l\leqslant p\leqslant r) a[p](l⩽p⩽r),并将其与 a [ l ] a[l] a[l]交换,利用随机化避免极端数据。
思路3.STL sort
sort(a, a+n);
sort(a, a+n, greater<int>()); // 降序
sort(a, a+n, less<int>()); // 升序
bool cmp(T a, T b) { return a < b; }
sort(a, a+n, cmp); // 升序
注:快速排序不具有稳定性
归并排序
思路:分治(归)
直接将当前序列等分成两段,直到序列长度为1时停止;在归的过程中,将两个有序序列合并成更大的有序序列,类似理牌,先从牌首取小牌放入,当某堆牌放完后,再将剩余的牌全部放入,如图:
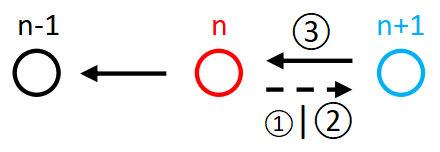
①边界: l = = r l==r l==r时序列长度为1,无需再分
②递:将序列等分为两段
③归:将有序序列合并
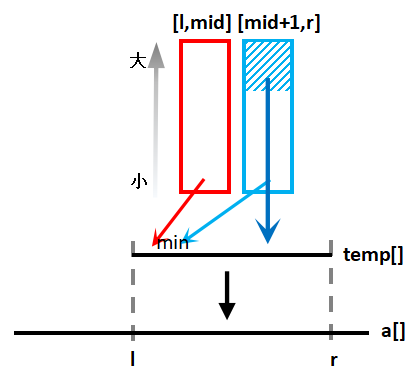
实现1:3-while
int temp[N];
void mergesort(int l, int r) {
if (l == r) return;
int mid = (l + r) >> 1;
mergesort(l, mid); // 1.
mergesort(mid + 1, r);
int i = l, j = mid + 1, pos = l; // 2.
while (i <= mid && j <= r)
if (a[i] < a[j]) temp[pos++] = a[i++];
else temp[pos++] = a[j++];
while (i <= mid) temp[pos++] = a[i++]; // 3.
while (j <= r) temp[pos++] = a[j++];
for (int k = l; k < pos; k++) a[k] = temp[k];
}
细节:
1.当 m i d = ⌊ l + r 2 ⌋ mid=\lfloor\dfrac{l+r}{2}\rfloor mid=⌊2l+r⌋时,划分区间为 [ l , m i d ] , [ m i d + 1 , r ] [l,mid],[mid+1,r] [l,mid],[mid+1,r],则由 l + r 2 − 1 < ⌊ l + r 2 ⌋ ⩽ l + r 2 \dfrac{l+r}{2}-1<\lfloor\dfrac{l+r}{2}\rfloor\leqslant\dfrac{l+r}{2} 2l+r−1<⌊2l+r⌋⩽2l+r知 { m i d > l + r 2 − 1 > l + l 2 − 1 = l − 1 ⇒ m i d ⩾ l m i d + 1 ⩽ l + r 2 + 1 < r + r 2 + 1 = r + 1 ⇒ m i d + 1 ⩽ r \left\{\begin{array}{ll}mid>\dfrac{l+r}{2}-1>\dfrac{l+l}{2}-1=l-1\Rightarrow mid\geqslant l\\\\mid+1\leqslant\dfrac{l+r}{2}+1<\dfrac{r+r}{2}+1=r+1\Rightarrow mid+1\leqslant r\end{array}\right. ⎩ ⎨ ⎧mid>2l+r−1>2l+l−1=l−1⇒mid⩾lmid+1⩽2l+r+1<2r+r+1=r+1⇒mid+1⩽r
使子区间 [ l , r ] [l,r] [l,r]仍能保证 l ⩽ r l\leqslant r l⩽r
2.将归并结果暂存于temp[]的对应位置中,方便挪入a[]中
3.将剩余元素全部放入
实现2:for
int temp[N];
void mergesort(int l, int r) {
if (l == r) return;
int mid = (l + r) >> 1;
mergesort(l, mid);
mergesort(mid + 1, r);
int i = l, j = mid + 1;
for (int pos = l; pos <= r; pos++) { // 将每个元素都放完为止
if (j > r || (i <= mid && a[i] < a[j])) temp[pos] = a[i++]; // 1.
else temp[pos] = a[j++];
}
for (int k = l; k < pos; k++) a[k] = temp[k];
}
细节:
1.放前半段的条件:
(1)后半段已经放完,而此时所有元素仍未全部归位,则一定是前半段未放完
(2)后半段没放完,而进行两者首位比较的条件是两者均未放完,所以此时只有前半段没放完的时候,才能进行比较并放置最小的牌
注:归并排序具有稳定性
堆排序
维护一个小根堆,利用小根堆的性质直接从堆首取出最小值。
小根堆
定义:父节点小于等于左右子节点的完全二叉树(反之则为大根堆)
性质:
1.父节点小于等于左右子节点
2.根节点为最小值
3.从根节点到叶节点的每条路径上的值单调递增
存储:
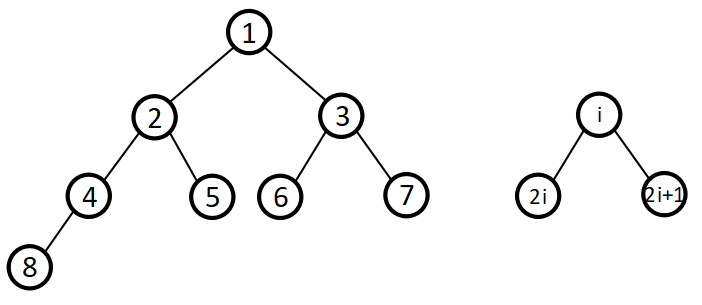
根节点为 a 1 a_1 a1; ∀ a i , \forall a_i, ∀ai,左子节点为 a 2 i , a_{2i}, a2i,右子节点为 a 2 i + 1 a_{2i+1} a2i+1,如图:
操作:
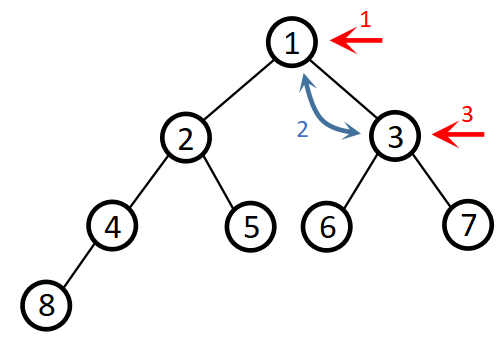
1.维护小根堆性质 m i n i h e a p ( i ) miniheap(i) miniheap(i):
使得以 i i i为根的子树满足最小堆的性质:当节点 i i i不满足最小堆的性质,即节点 i i i不比子节点小时,找到节点 i i i最小的子节点 m i n min min与节点 i i i互换,并递归调用 m i n i h e a p ( m i n ) miniheap(min) miniheap(min),继续调整以 m i n min min为根的子树(互换操作对该子树产生影响);当节点 i i i满足性质,即节点 i i i小于等于子节点或者节点 i i i为叶子节点时,达到边界,如图:
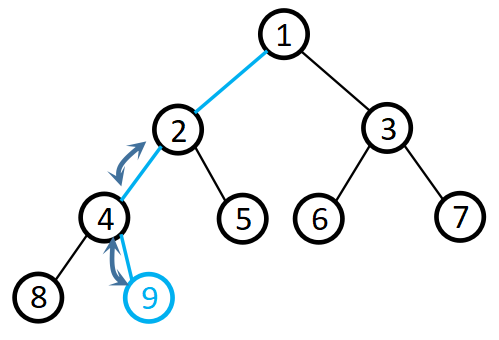
2.向堆尾插入元素 i n s e r t ( n ) insert(n) insert(n):
将插入的元素与父节点进行比较,若比父节点小,则与父节点互换;当比父节点大或位于根节点时停止,如图:
可以视作在该节点到根的路径上调整顺序,由于每次交换都涉及待排序节点,原节点间未互相交换,故不会改变原节点的先后顺序。
3.删除堆首元素 d e l ( ) del() del():
取出堆首的最小元素,并将堆尾元素提至堆首,再对根节点维护小根堆性质。
实现:
int heapsize = 0;
inline void miniheap(int i) {
int l = i << 1, r = i << 1 | 1, min = i;
if (l <= heapsize && a[l] < a[min]) min = l; // 判断是否存在左右儿子
if (r <= heapsize && a[r] < a[min]) min = r;
if (min != i) { swap(a[i], a[min]); miniheap(min); }
}
inline void insert(int n) {
a[++heapsize] = n; // 堆从1开始存(避免0=0*2)
int i = heapsize;
while (i > 1 && a[i >> 1] > a[i]) { swap(a[i], a[i >> 1]); i >>= 1;} // 此处为大于,阻止a[1]与a[0]互换
}
inline void del() {
a[1] = a[heapsize--];
miniheap(1);
}
堆排序
思路:先建堆,即将所有元素逐个插入堆中;再从堆首一个一个取出最小元素,即完成堆排序。
实现:
inline int del() {
int ret = a[1];
a[1] = a[heapsize--];
miniheap(1);
return ret; // 删除同时返回堆首
}
void heapsort(int n) {
for (int i = 0; i < n; i++) insert(b[i]);
for (int i = 0; i < n; i++) b[i] = del();
}
注:堆排序不具有稳定性
计数排序
思路:将数据本身作为下标进行存储,再按照数据大小顺序将其取出
实现:
cnt = 0;
for (int i = 0; i < n; i++) temp[a[i]]++;
for (int i = 0; i <= k; i++)
while (temp[i]) a[cnt++] = i, temp[i]--;
注:计数排序具有稳定性
桶排序
思路:将数据分组(即放入各个桶)后,对每个桶内的数据进行排序,再将这些桶进行合并;分组越均匀,性能越好
基数排序
思路:开十个桶,分别对应数字 0 ∼ 9 0\sim9 0∼9,按如下方式进行:
1.按个位入桶
2.按编号递增顺序取出,再按十位入桶
3.按编号递增顺序取出,再按百位入桶
4.重复上述步骤,直至所有位数排序完毕
证明:数学归纳法
当按照个位排序时,取出后个位有序
假设现在已按前 n n n位排序,即前 n n n位都有序
那么按 n + 1 n+1 n+1位入桶排序后,对 ∀ \forall ∀ 第 n + 1 n+1 n+1位 i , j ( i < j ) , i x n ‾ , j x n ‾ i,j(i<j),\overline{ix_n},\overline{jx_n} i,j(i<j),ixn,jxn内部有序,且 max i x n ‾ < max j 0 … 0 ‾ ⩽ min j x n ‾ \max\overline{ix_n}<\max\overline{j0\dots0}\leqslant\min\overline{jx_n} maxixn<maxj0…0⩽minjxn,即取出的序列对n+1位也有序
由归纳原理知,按 n n n位入桶后,取出的序列对前 n n n位都有序
所以按每一位进行操作后,即得到有序序列
实际操作如图:

实现:
int M = -1, digit = 0, radix = 1;
for (int i = 0; i < n; i++) M = max(a[i], M);
for (; M; M /= 10) digit++; // 找最大数确定位数作为排序轮数
for (int i = 0; i < digit; i++) {
memset(cnt, 0, sizeof(cnt));
for (int j = 0; j < n; j++) cnt[(a[j] / radix) % 10]++;
for (int j = 1; j < 10; j++) cnt[j] += cnt[j - 1];
for (int j = n - 1; j >= 0; j--) temp[--cnt[(a[j] / radix) % 10]] = a[j]; // 先减后放:考虑cnt[0]=1时放入temp[0]位置
for (int j = 0; j < n; j++) a[j] = temp[j];
radix *= 10;
}
注:基数排序具有稳定性
离散化
定义:将无穷大集合中的若干元素映射为有限集合以便于统计的方法
思路:将 a 1 , a 2 , … , a n ∈ Z ( ∣ { a n } ∣ = m , m ⩽ n ) a_1,a_2,\dots,a_n\in \Z(|\{a_n\}|=m,m\leqslant n) a1,a2,…,an∈Z(∣{an}∣=m,m⩽n)与 1 , 2 , … , m 1,2,\dots,m 1,2,…,m建立映射关系,从而将复杂度降至 O ( m ) O(m) O(m)
操作:
1.离散化 d i s c r e t e ( ) discrete() discrete():将 a n a_n an排序并去重,按顺序存入离散化数组 d m d_m dm中, d i = a j d_i=a_j di=aj即 i ↦ a j i\mapsto a_j i↦aj
2.查询 q u e r y ( x ) query(x) query(x):逆映射,查询 a j a_j aj对应离散化后的数字 i i i,即 a j ↦ i a_j\mapsto i aj↦i:二分查找 a j a_j aj在 d [ ] d[] d[]中的位置
性质: ∀ a i ↦ i , a j ↦ j , s . t . a i ⩽ a j ⇔ i ⩽ j \forall a_i\mapsto i,a_j\mapsto j,s.t.a_i\leqslant a_j\Leftrightarrow i\leqslant j ∀ai↦i,aj↦j,s.t.ai⩽aj⇔i⩽j(保持相对大小不变)
适用范围:问题的求解与数值的绝对大小无关
实现:
void discrete() {
sort(d, d + n); // 1.
s = unique(d, d + n) - d; // 2.
}
int query(int x) { return lower_bound(d, d + s, x) - d; } // 3.
细节:
1.将数据存放在离散化数组中以保留原数据
2.调用unique后, d [ 0.. s − 1 ] d[0..s-1] d[0..s−1]完成去重,但是 d [ s ] d[s] d[s]及之后的元素并不为0,需记录新的数组大小
3.由于unique并不会把重复元素真正删去,所以需要使用lower_bound从左向右进行查找
例1 Cinema
思路:离散化
为了能将语言标识直接作为数组下标方便计数,需要对语言进行离散化
实现:
void discrete() {
sort(d, d + n);
s = unique(d, d + n) - d;
}
int query(int x) {
int l = lower_bound(d, d + s, x) - d;
return d[l] == x ? l : n; // 1.
}
int main() {
int maxb = -1, maxc = -1, ans = 0;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> a[i];
d[i] = a[i];
}
discrete();
for (int i = 0; i < n; i++)
cnt[query(a[i])]++;
cin >> m;
for (int i = 1; i <= m; i++)
cin >> b[i];
for (int i = 1; i <= m; i++)
cin >> c[i];
for (int i = 1; i <= m; i++) {
b[i] = query(b[i]), c[i] = query(c[i]);
if (cnt[b[i]] > maxb)
maxb = cnt[b[i]], maxc = cnt[c[i]], ans = i;
else if (cnt[b[i]] == maxb && cnt[c[i]] > maxc)
maxc = cnt[c[i]], ans = i;
}
cout << ans << endl;
return 0;
}
细节:
1.此处为便于实现,仅对科学家所说的语言进行离散化,当对电影进行 q u e r y ( x ) query(x) query(x)操作时,需判断电影不存在的情况,即判断lower_bound返回结果是否为待查元素,如果不是便返回一个空位即可
中位数
例2货仓选址
思路1:增量法
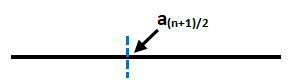
先将 A n A_n An进行排序,设选址点 x x x左侧有 P P P家商店,右侧有 Q Q Q家商店,若 P < Q P<Q P<Q,则将 x x x向右移动 d x dx dx时总距离将会减少 d y = ( Q − P ) d x dy=(Q-P)dx dy=(Q−P)dx;若 P > Q P>Q P>Q,则将 x x x向左移动 d x dx dx时总距离将会减少 d y = ( P − Q ) d x dy=(P-Q)dx dy=(P−Q)dx,即移动导致的增量 d y = ∣ P − Q ∣ d x dy=|P-Q|dx dy=∣P−Q∣dx,则当 d y d x = 0 \dfrac{dy}{dx}=0 dxdy=0时, ∣ P − Q ∣ = 0 ⇒ P = Q |P-Q|=0\Rightarrow P=Q ∣P−Q∣=0⇒P=Q,即选址点左右侧商店数量相等。
显然, A n A_n An中位数 A ( n + 1 ) / 2 A_{(n+1)/2} A(n+1)/2即是符合条件的 x x x之一。更一般的,当 n n n为奇数时选取 A ( n + 1 ) / 2 A_{(n+1)/2} A(n+1)/2;当 n n n为偶数时,选取 A n / 2 ∼ A n / 2 + 1 A_{n/2}\sim A_{n/2+1} An/2∼An/2+1间的任一点都满足条件。
思路2:配对法
为了更好的体现几何意义,我们将 A n A_n An放在数轴上,相当于对 A n A_n An进行排序,那么当 n n n为偶数时,
d i s = ∑ i = 1 n ∣ A i − x ∣ = ∑ i = 1 n 2 ( ∣ A i − x ∣ + ∣ A n + 1 − i − x ∣ ) ⩾ ∑ i = 1 n 2 ∣ ( A i − x ) − ( A n + 1 − i − x ) ∣ ⩾ ∑ i = 1 n 2 ( A n + 1 − i − A i ) dis=\sum\limits_{i=1}^n|A_i-x|=\sum\limits_{i=1}^{\frac{n}{2}}(|A_{i}-x|+|A_{n+1-i}-x|)\\\geqslant\sum\limits_{i=1}^{\frac{n}{2}}|(A_{i}-x)-(A_{n+1-i}-x)|\geqslant\sum\limits_{i=1}^{\frac{n}{2}}(A_{n+1-i}-A_{i}) dis=i=1∑n∣Ai−x∣=i=1∑2n(∣Ai−x∣+∣An+1−i−x∣)⩾i=1∑2n∣(Ai−x)−(An+1−i−x)∣⩾i=1∑2n(An+1−i−Ai)
即将 A n A_n An首尾配对,取等条件为 ∀ 1 ⩽ i ⩽ n 2 , A i ⩽ x ⩽ A n + 1 − i \forall 1\leqslant i\leqslant\dfrac{n}{2},A_i\leqslant x\leqslant A_{n+1-i} ∀1⩽i⩽2n,Ai⩽x⩽An+1−i,由 A n A_n An有序性知,解集为 A n / 2 ⩽ x ⩽ A n / 2 + 1 A_{n/2}\leqslant x\leqslant A_{n/2+1} An/2⩽x⩽An/2+1
当 n n n为奇数时, d i s ⩾ ∑ i = 1 n − 1 2 ( A n + 1 − i − A i ) + ∣ A ( n + 1 ) / 2 − x ∣ ⩾ ∑ i = 1 n − 1 2 ( A n + 1 − i − A i ) dis\geqslant\sum\limits_{i=1}^{\frac{n-1}{2}}(A_{n+1-i}-A_{i})+|A_{(n+1)/2}-x|\geqslant\sum\limits_{i=1}^{\frac{n-1}{2}}(A_{n+1-i}-A_{i}) dis⩾i=1∑2n−1(An+1−i−Ai)+∣A(n+1)/2−x∣⩾i=1∑2n−1(An+1−i−Ai)
取等条件为 x = A ( n + 1 ) / 2 x=A_{(n+1)/2} x=A(n+1)/2
实现:
sort(a, a + n);
pos = a[n >> 1]; // 数组下标从0开始,化为(n+0)/2
for (int i = 0; i < n; i++) dis += abs(pos - a[i]);
例3七夕祭
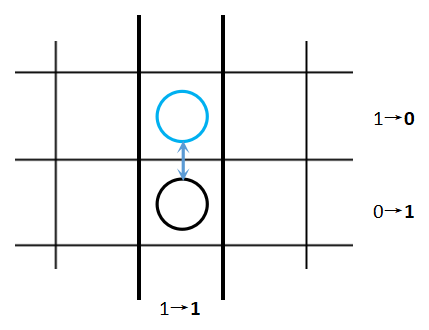
思路:
易知进行行间交换时,不会对列造成影响,因为交换的两个元素仍然位于原来的列之中,如图:
同理,进行列间交换时,不会对行造成影响。利用行和列的独立性,我们可以将问题拆分为行和列上的两个子问题。
我们发现,当 n ∣ t n|t n∣t(或 m ∣ t m|t m∣t)时,将每行(或每列)元素调整至 a v g = t n avg=\dfrac{t}{n} avg=nt(或 t m \dfrac{t}{m} mt)时即可达成目标,问题转化为求将 n n n堆纸牌进行相邻交换后使得各堆纸牌元素个数相等的最小交换次数。
与均分纸牌问题不同的是,这里的牌堆首尾相连。我们先考虑原始的交换纸牌问题,即不考虑首位元素的交换,如图:
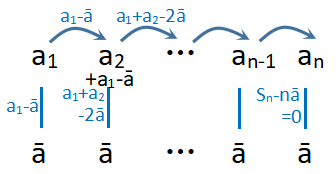
由于 a 1 a_1 a1只能通过和 a 2 a_2 a2交换来进行调整,所以调整 a 1 a_1 a1需进行 ∣ a 1 − a v g ∣ |a_1-avg| ∣a1−avg∣次交换。
同理,在 a 1 a_1 a1交换完成后, a 2 a_2 a2化为 a 2 + ( a 1 − a v g ) a_2+(a_1-avg) a2+(a1−avg)(多退少补),由于此时 a 1 a_1 a1已调整到位, a 2 a_2 a2只能与 a 3 a_3 a3进行交换,调整与 a 1 a_1 a1交换后的 a 2 a_2 a2需要进行 ∣ a 2 + ( a 1 − a v g ) − a v g ∣ = ∣ a 1 + a 2 − 2 a v g ∣ |a_2+(a_1-avg)-avg|=|a_1+a_2-2avg| ∣a2+(a1−avg)−avg∣=∣a1+a2−2avg∣次交换。
以此类推,调整与 a k − 1 a_{k-1} ak−1交换后的 a k a_k ak需要进行 ∣ ∑ i = 1 k a i − k ⋅ a v g ∣ |\sum\limits_{i=1}^ka_i-k\cdot avg| ∣i=1∑kai−k⋅avg∣次交换,下用数归证明:
在 a k a_k ak交换完成后, a k + 1 a_{k+1} ak+1化为 a k + 1 + ( ∑ i = 1 k a i − k ⋅ a v g ) a_{k+1}+(\sum\limits_{i=1}^ka_i-k\cdot avg) ak+1+(i=1∑kai−k⋅avg),调整与 a k a_k ak交换后的 a k + 1 a_{k+1} ak+1需要进行 ∣ a k + 1 + ( ∑ i = 1 k a i − k ⋅ a v g ) − a v g ∣ = ∣ ∑ i = 1 k + 1 a i − ( k + 1 ) ⋅ a v g ∣ |a_{k+1}+(\sum\limits_{i=1}^ka_i-k\cdot avg)-avg|=|\sum\limits_{i=1}^{k+1}a_i-(k+1)\cdot avg| ∣ak+1+(i=1∑kai−k⋅avg)−avg∣=∣i=1∑k+1ai−(k+1)⋅avg∣次交换,即证。
由于最后一个数据无需进行交换,所以总交换次数为 ∑ i = 1 n − 1 ∣ ∑ j = 1 i a j − i ⋅ a v g ∣ ( ∗ ) \sum\limits_{i=1}^{n-1}|\sum\limits_{j=1}^ia_j-i\cdot avg|(*) i=1∑n−1∣j=1∑iaj−i⋅avg∣(∗).
下面对 ( ∗ ) (*) (∗)进行化简: ( ∗ ) = ∑ i = 1 n − 1 ∣ ∑ j = 1 i ( a j − a v g ) ∣ (*)=\sum\limits_{i=1}^{n-1}|\sum\limits_{j=1}^i(a_j-avg)| (∗)=i=1∑n−1∣j=1∑i(aj−avg)∣,这样 ( a j − a v g ) (a_j-avg) (aj−avg)便成为了一个整体。为了便于 ∑ j = 1 i ( a j − a v g ) \sum\limits_{j=1}^i(a_j-avg) j=1∑i(aj−avg)的处理,我们借助前缀和,即令 S i ≜ ∑ j = 1 i ( a j − a v g ) S_i\triangleq \sum\limits_{j=1}^i(a_j-avg) Si≜j=1∑i(aj−avg),原式化为 ∑ i = 1 n − 1 ∣ S i ∣ \sum\limits_{i=1}^{n-1}|S_i| i=1∑n−1∣Si∣.
现在我们考虑首尾可以交换的情形。首位交换的实质是使得各个元素连成了一个环,实际交换时,我们从环上选择一点作为我们的区间起点,即 a 1 a_1 a1,然后环退化为单链。
我们发现,位于尾部的元素与位于其它地方的元素地位并不等价, a n a_n an对和式没有贡献;所以首尾交换的实质便是确定尾部元素 a k a_k ak,使得 a k a_k ak不参与最终答案计算时,答案最小。
当尾部元素由 a n a_n an换至 a k a_k ak时,由于前缀和是以 a 1 − a v g a_1-avg a1−avg为起点进行计算的,所以各处的前缀和同步发生变化。
假设元素初始下标为 i i i,则当 k + 1 ⩽ i ⩽ n k+1\leqslant i\leqslant n k+1⩽i⩽n时, S i ′ = ∑ j = k + 1 i ( a j − a v g ) = S i − S k S_i'=\sum\limits_{j=k+1}^i(a_j-avg)=S_i-S_k Si′=j=k+1∑i(aj−avg)=Si−Sk;
当 1 ⩽ i ⩽ k − 1 1\leqslant i\leqslant k-1 1⩽i⩽k−1时, S i ′ = ∑ j = k + 1 n ( a j − a v g ) + ∑ j = 1 i ( a j − a v g ) = S n − S k + S i = S i − S k S_i'=\sum\limits_{j=k+1}^n(a_j-avg)+\sum\limits_{j=1}^i(a_j-avg)=S_n-S_k+S_i=S_i-S_k Si′=j=k+1∑n(aj−avg)+j=1∑i(aj−avg)=Sn−Sk+Si=Si−Sk
其中 S n = ∑ j = 1 n ( a j − a v g ) = ∑ j = 1 n a j − ∑ j = 1 n ( 1 n ∑ k = 1 n a k ) = 0 S_n=\sum\limits_{j=1}^n(a_j-avg)=\sum\limits_{j=1}^na_j-\sum\limits_{j=1}^n(\dfrac{1}{n}{\sum\limits_{k=1}^na_k})=0 Sn=j=1∑n(aj−avg)=j=1∑naj−j=1∑n(n1k=1∑nak)=0
所以 S i ′ = S i − S k ( 1 ⩽ i ⩽ n , i ≠ k ) S_i'=S_i-S_k(1\leqslant i\leqslant n,i\neq k) Si′=Si−Sk(1⩽i⩽n,i=k), ( ∗ ) = ∑ 1 ⩽ i ⩽ n , i ≠ k ∣ S i ′ ∣ = ∑ i = 1 n ∣ S i − S k ∣ ( i = k 时 S k ′ = 0 = S k − S k ) (*)=\sum\limits_{1\leqslant i\leqslant n,i\neq k}|S_i{'}|=\sum\limits_{i=1}^{n}|S_i-S_k|(i=k时S_k'=0=S_k-S_k) (∗)=1⩽i⩽n,i=k∑∣Si′∣=i=1∑n∣Si−Sk∣(i=k时Sk′=0=Sk−Sk)
将 S i S_i Si看作距离,问题转化为货仓选址。因此,我们只需要找出 S n S_n Sn的中位数作为 S k S_k Sk的取值,即可最小化 ∑ i = 1 n ∣ S i − S k ∣ \sum\limits_{i=1}^{n}|S_i-S_k| i=1∑n∣Si−Sk∣.
上述交换过程中可能出现牌堆数量为负数的情况,此时可以调整交换顺序使得交换正常进行,而不改变交换次数。
实现:
long long solve(int a[], int n) {
int avg = t / n, pos;
long long res = 0; // 数据较大
for (int i = 1; i <= n; i++)
a[i] -= avg;
for (int i = 2; i <= n; i++)
a[i] += a[i - 1];
sort(a + 1, a + 1 + n); // 下标从1开始
pos = a[(n + 1) >> 1];
for (int i = 1; i <= n; i++)
res += abs(pos - a[i]);
return res;
}
int main() {
int n, m, x, y, flag_r = 1, flag_c = 1;
cin >> n >> m >> t;
if (t % n && t % m) {
cout << "impossible" << endl;
return 0;
}
if (t % n) {
cout << "column ";
flag_r = 0;
} else if (t % m) {
cout << "row ";
flag_c = 0;
} else
cout << "both ";
for (int i = 0; i < t; i++) {
cin >> x >> y;
row[x]++, col[y]++;
}
if (!flag_r)
cout << solve(col, m) << endl;
else if (!flag_c)
cout << solve(row, n) << endl;
else
cout << solve(col, m) + solve(row, n) << endl;
return 0;
}
应该时刻把各种模型之间的简化、扩展和联系作为算法学习与设计的脉络,以点成线,触类旁通,才能产生数量到质量的飞跃。
例4 Running Median
思路:对顶堆
为了动态维护中位数,我们将原序列拆成两个有序的子序列,并规定当 n n n为奇数时,中位数为后一个序列的起始元素,如图:
同时,为了动态调整两个序列的分点,我们需要维护左序列的最大值和右序列的最小值。因此,我们需要一个大根堆和一个小根堆分别维护这两个序列的最大最小值。
先考虑插入过程,当插入的数比中位数大时,排在中位数的后面,需将其插入小根堆中;反之,将其插入大根堆。
接着考虑调整过程。根据定义,当 n n n为奇数时, ∣ m a x i h e a p ∣ = n − 1 2 , ∣ m i n i h e a p ∣ = n + 1 2 |maxiheap|=\dfrac{n-1}{2},|miniheap| =\dfrac{n+1}{2} ∣maxiheap∣=2n−1,∣miniheap∣=2n+1;而当 n n n为偶数时,我们不妨令 ∣ m a x i h e a p ∣ = ∣ m i n i h e a p ∣ = n 2 |maxiheap|=|miniheap|=\dfrac{n}{2} ∣maxiheap∣=∣miniheap∣=2n.这样,当 n n n为奇数时,我们需要调整至 ∣ m a x i h e a p ∣ < ∣ m i n i h e a p ∣ |maxiheap|<|miniheap| ∣maxiheap∣<∣miniheap∣,由于上一次 n − 1 n-1 n−1为偶数,已经调整至二者相等,所以最多调整2次;同理,当 n n n为奇数时,由于上次 n − 1 n-1 n−1为奇数,如果插入在小根堆中,一次调整即可,如果插在大根堆中,则不需要调整。
奇数次插入后,中位数即为小根堆堆顶。
实现:
/* 两用堆:传入大根堆标志,利用xor切换条件 */
inline void insert(int a[], int x, bool is_maxi, int *heapsize) {
a[++(*heapsize)] = x;
int i = *heapsize;
while (i > 1 && is_maxi ^ (a[i] < a[i >> 1])) {
swap(a[i], a[i >> 1]);
i >>= 1;
}
}
inline void heapify(int a[], int i, bool is_maxi, int heapsize) {
int l = i << 1, r = i << 1 | 1, min = i;
if (l <= heapsize && is_maxi ^ (a[l] < a[min]))
min = l;
if (r <= heapsize && is_maxi ^ (a[r] < a[min]))
min = r;
if (min != i) {
swap(a[min], a[i]);
heapify(a, min, is_maxi, heapsize);
}
}
inline int del(int a[], bool is_maxi, int *heapsize) {
int ret = a[1];
a[1] = a[(*heapsize)--]; // 注意解引用和自增自减的优先级
heapify(a, 1, is_maxi, *heapsize);
return ret;
}
int main() {
int p, index, m, x;
cin >> p;
while (p--) {
miniheapsize = maxiheapsize = 0; // 全局变量清零
cin >> index >> m;
cout << index << ' ' << ((m + 1) >> 1) << endl;
for (int i = 1; i <= m; i++) {
if (i != 1 && i % 20 == 1)
cout << endl;
cin >> x;
if (x >= mini[1])
insert(mini, x, 0, &miniheapsize);
else
insert(maxi, x, 1, &maxiheapsize);
/* 大小调整 */
if (!(i % 2) && maxiheapsize < miniheapsize)
insert(maxi, del(mini, 0, &miniheapsize), 1, &maxiheapsize);
if (i % 2)
while (maxiheapsize >= miniheapsize)
insert(mini, del(maxi, 1, &maxiheapsize), 0, &miniheapsize);
if (i % 2)
cout << mini[1] << ' ';
}
cout << endl;
}
return 0;
}
第 k k k大数
思路:对快速排序进行变形,即可在 O ( n ) O(n) O(n)求得第 k k k大数:
每次区间划分后,设基准值位于 p o s pos pos处,那么当 k = p o s k=pos k=pos时,基准值即为第 k k k大数;当 k < p o s k<pos k<pos时,第 k k k大数位于小于基准值区间;当 k > p o s k>pos k>pos时,第 k k k大数位于大于基准值区间。
这样,我们每次待划分区间的大小将缩小至原来的一半,复杂度为 ∑ n 2 k = O ( n ) \sum\dfrac{n}{2^k}=O(n) ∑2kn=O(n)
实现:
int qsort(int l, int r) {
// 一定能找到第k大数,无需判断边界
int key = a[l], i = l, j = r;
while (i < j) {
while (a[j] >= key && i < j) j--;
while (a[i] <= key && i < j) i++;
if (i < j) swap(a[i], a[j]);
}
swap(a[l], a[i]);
if (i == k) return i;
return k < i ? qsort(l, i - 1) : qsort(i + 1, r);
}
注:按从小到大排序时求得的是第 k k k小数。
逆序对
定义: a [ i ] a[i] a[i]与 a [ j ] a[j] a[j]构成逆序对 ⇔ i < j 且 a [ i ] > a [ j ] \Leftrightarrow i<j且a[i]>a[j] ⇔i<j且a[i]>a[j]
思路:对归并排序进行变形,用 O ( n l o g n ) O(nlogn) O(nlogn)求逆序对数。
先考察一次合并过程,如图:
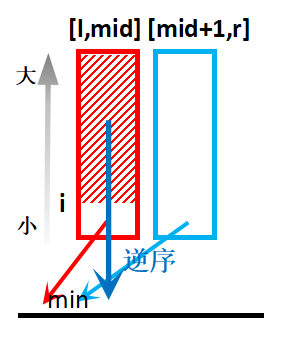
每当放置后半段数据时,由于两段序列内部有序,所以 a i > a j ⇒ ∀ k ∈ [ i , m i d ] , a k > a j a_i>a_j\Rightarrow\forall k\in[i,mid],a_k>aj ai>aj⇒∀k∈[i,mid],ak>aj,而此时 k ⩽ m i d < j k\leqslant mid<j k⩽mid<j,所以 a i . . m i d a_{i..mid} ai..mid与 a j a_j aj都构成逆序对,共 m i d − i + 1 mid-i+1 mid−i+1个。
因为两段序列内部有序,所以每一次合并过程求得的是两段序列间互作产生的逆序对数。
下用数归证明归并排序能求出序列的逆序对,即合并 n n n次后能求出对应区间的全部逆序对。
对 n + 1 n+1 n+1次合并,此时对应区间的逆序对数=前半段区间内部的逆序对数+后半段区间的逆序对数+前后区间互作产生的逆序对数( C n 2 = 2 C n 2 2 + ( n 2 ) 2 C_n^2=2C_{\frac{n}{2}}^2+(\dfrac{n}{2})^2 Cn2=2C2n2+(2n)2).
由归纳假设知,此时前后半段区间的逆序对数均已求出,由此时前后半段区间的有序性知,此时前后半段区间内部不存在逆序对。又一次合并操作能够求出前后半段区间互作产生的逆序对数,所以第 n + 1 n+1 n+1次合并后全部逆序对均已求出,即证。
实现:
int temp[N];
void mergesort(int l, int r) {
if (l == r) return;
int mid = (l + r) >> 1;
mergesort(l, mid);
mergesort(mid + 1, r);
int i = l, j = mid + 1;
for (int pos = l; pos <= r; pos++) {
if (j > r || (i <= mid && a[i] < a[j])) temp[pos] = a[i++];
else temp[pos] = a[j++], cnt += mid - i + 1;
}
for (int k = l; k < pos; k++) a[k] = temp[k];
}
例5 Ultra-QuickSort
思路:交换相邻逆序元素能使逆序对减少一对,而对其它未参与交换的元素无影响。
简证:将某序列分为两个子序列后,原序列的逆序对数=两个子序列内部的逆序对数+两个子序列间的逆序对数。
a 1 a 2 … a k a k + 1 … a n a_1\space a_2\dots a_k\space a_{k+1}\dots a_n a1 a2…ak ak+1…an交换 a k , a k + 1 a_k,a_{k+1} ak,ak+1后, a 1.. k − 1 , a k + 2.. n a_{1..k-1},a_{k+2..n} a1..k−1,ak+2..n与 a k , a k + 1 a_k,a_{k+1} ak,ak+1形成的逆序对数不变(即 a k , a k + 1 a_k,a_{k+1} ak,ak+1与 a 1.. k − 1 , a k + 2.. n a_{1..k-1},a_{k+2..n} a1..k−1,ak+2..n形成的逆序对数不变),而 a 1.. k − 1 , a k + 2.. n a_{1..k-1},a_{k+2..n} a1..k−1,ak+2..n相对顺序并未改变,从而内部的逆序对数不变,只改变了 a k , a k + 1 a_k,a_{k+1} ak,ak+1间的逆序对数。
再证序列存在逆序对 ⇒ \Rightarrow ⇒序列存在相邻逆序对。设序列为 a 1 a 2 … a k − 1 a k a k + 1 … a l − 1 a l a l + 1 … a n ( a k > a l ) a_1\space a_2\dots a_{k-1}\space a_k\space a_{k+1}\dots a_{l-1}\space a_l\space a_{l+1}\dots a_n(a_k>a_l) a1 a2…ak−1 ak ak+1…al−1 al al+1…an(ak>al),若原序列不存在相邻逆序对,即 a k − 1 < a k < a k + 1 < ⋯ < a l − 1 < a l < a l + 1 < ⋯ ⇒ a k < a l a_{k-1}<a_k<a_{k+1}<\dots<a_{l-1}<a_l<a_{l+1}<\dots\Rightarrow a_k<a_l ak−1<ak<ak+1<⋯<al−1<al<al+1<⋯⇒ak<al矛盾!所以结论得证。
所以若原序列存在逆序对,则一定可以通过消除相邻逆序对实现逆序对的减少,所以最少相邻交换次数即原序列的逆序对数。
实现同上。
例6奇数码问题
思路:将棋盘化为序列,并去掉0,有结论:两个局面可达 ⇔ \Leftrightarrow ⇔两个局面逆序对数奇偶性相同
该结论的充分性证明较为复杂,我们将不在此大篇幅讨论这样一个数学问题。——李煜东
可是评论区可有大篇幅,欢迎大家在评论区给出充分性证明。
下证必要性。当0横向移动时,对序列无影响;当0纵向移动时,相当于被交换数移动了 n − 1 n-1 n−1位(n-1为偶数)。
序列元素每移动一位,都可以看作发生一次相邻交换,而每次相邻交换都会使逆序数 + 1 +1 +1或者 − 1 -1 −1.又 1 ∗ p + ( − 1 ) ∗ ( 2 k − p ) = 2 ( p − k ) 1*p+(-1)*(2k-p)=2(p-k) 1∗p+(−1)∗(2k−p)=2(p−k)为偶数,所以偶数次相邻交换后逆序数改变量为偶数,因此可达的两个局面逆序数相差偶数个,即奇偶性相同。
所以问题化为判断两个转化后序列奇偶性是否相同。
实现:
void mergesort(int l, int r, int a[], int *cnt) {
if (l == r)
return;
int mid = (l + r) >> 1;
mergesort(l, mid, a, cnt);
mergesort(mid + 1, r, a, cnt);
int i = l, j = mid + 1;
for (int pos = l; pos <= r; pos++) {
if (j > r || (i <= mid && a[i] < a[j]))
temp[pos] = a[i++];
else
temp[pos] = a[j++], *cnt += mid - i + 1;
}
for (int k = l; k <= r; k++)
a[k] = temp[k];
}
int main() {
int n, x;
while (cin >> n) { // 不能使用while (1), 会被判TLE
cnt1 = cnt2 = 0;
if (n == 1) { // 特判n = 1,否则序列变为[0,-1]
cout << "TAK" << endl;
continue;
}
for (int i = 0; i < n * n; i++) {
cin >> x;
if (!x)
continue;
a[cnt1++] = x;
}
cnt1 = 0;
for (int i = 0; i < n * n; i++) {
cin >> x;
if (!x)
continue;
b[cnt1++] = x;
}
cnt1 = 0;
mergesort(0, n * n - 2, a, &cnt1);
mergesort(0, n * n - 2, b, &cnt2);
if ((cnt1 - cnt2) % 2)
cout << "NIE" << endl;
else
cout << "TAK" << endl;
}
return 0;
}















 228
228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









