






覆盖索引
一种查询的特殊场景,二级索引本身能覆盖所有的查询列,不需要回表查询。
聚集索引
InnoDB是索引本身就包含了完整的数据记录,而且按照索引的顺序排好序存储。索引和数据在一起存储的结构。
InnoDB建议要有主键,并且推荐使用整型的自增主键?①如果没有主键,会从所有的列中选择一个所有列都不想等的列。如果都没选到呢,会建一个隐藏列,这个隐藏列组织整张表的数据。Mysql的资源非常宝贵,我们能自己做,就不用Mysql做了,提高相应性能。
因为索引定位的过程中需要频繁的比较大小,uuid需要逐位进行对比,整型的速度要比uuid快,而且整型相比uuid要求的存储空间要小,索引都是存储在磁盘(SSD)上。
②hash索引能够直接定位到数据的位置,但是不能支持IN和范围的查询。数据在磁盘上的存储是按照顺序存储的,如果插入一个比较小的值,它就需要在中间插入,可能会引起节点的分裂,以及树的平衡。而直接插入一个大的节点它会新增节点或新建一个节点,这样相对插入小的值,更快。
单纯从索引的角度来看,聚集索引要比非聚集索引更快,因为非聚集索引还要回表查询。但是也不绝对。
二级索引
是一个稀疏索引。
二级索引的叶子节点,只存储主键,不存储数据。节约存储空间。
不建议建太多的单值索引,而是建立一个联合索引。
联合索引
索引按照联合索引的字段从左向右排序存储。
联合主键索引
多个字段是一个索引,索引节点存储多个字段的顺序,叶子节点存储所有的值。叶子节点的起始的数据编号会提取到父级的节点中。
非聚集索引
MyISam 数据是按照索引单独存储,数据单独索引。
索引下推
虽然b,c字段不排序了可能用不上索引,但为了能过滤更多的数据,还用到了b,c。相当于时间换空间,

SQL trace
set session optimizer_trace="enabled=on",end_markers_in_json=on; ‐‐ 开启trace
select * from employees where name > 'a' order by position;
SELECT * FROM information_schema.OPTIMIZER_TRACE;
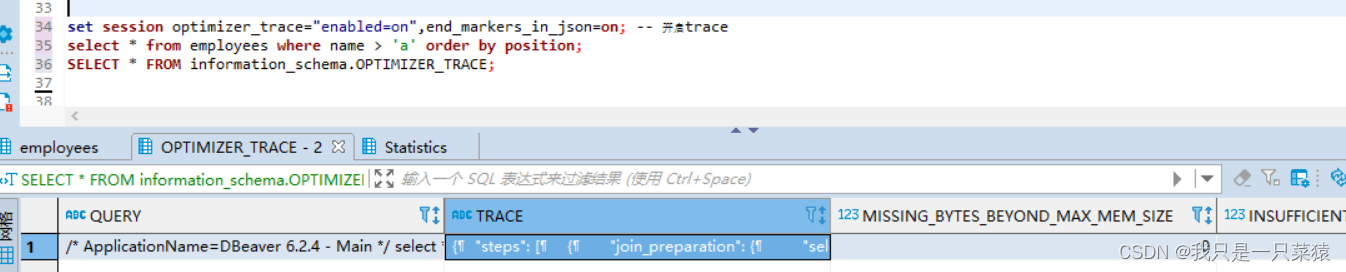
join_preparation:准备阶段(格式化SQL)
join_optimization:优化阶段(SQL优化阶段),会把SQL中无效的1=1去掉,联合索引的顺序调整。
最左匹配原则
因为索引是按照从左到右存储的,因为只有基于第一个字段的排序才是正确的。这个最左匹配原则和查询时,where后的条件是没有关系的。
面试题
B树:https://www.cs.usfca.edu/~galles/visualization/BTree.html
B+树:https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
B树和B+树的区别
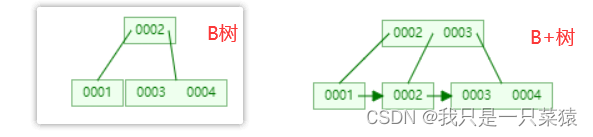
Innodb中的B+树有什么特点
遵循操作系统的局部性原理
show GLOBAL status like 'Innodb_page_size';
什么是Innodb中的page
每次查询取出一页数据(16KB),能取出来多少条数据呢。
int 类型占四个字节,varchar类型看字符集(UTF-8mb4,4个字节)所以一行大概最多20个字节。
所以只进行了一次磁盘IO就取出来了所有数据。即通过页提高了查询效率
页中存储哪些数据呢:页数据及一些属性
create table `t1`(
`a` int primary key,
`b` int,
`c` int,
`d` int,
`e` varchar(20)
) ENGINE = InnoDB;
DROP TABLE T1;
SELECT * FROM T1;
SELECT * FROM T1 where a = 7;
SHOW INDEX FROM T1;
INSERT INTO t1 values(4,3,1,1,'d');
INSERT INTO t1 values(1,1,1,1,'a');
INSERT INTO t1 values(8,8,8,8,'h');
INSERT INTO t1 values(2,2,2,2,'b');
INSERT INTO t1 values(5,2,3,5,'e');
INSERT INTO t1 values(3,3,2,2,'c');
INSERT INTO t1 values(7,4,5,5,'g');
INSERT INTO t1 values(6,6,4,4,'f');
当插入数据时,放到也数据中,当page中达到16KB时,就不写了,然后写到磁盘中。取的时候直接取Page页对象。
页结构
class Page{
// 页头
//页目录
//页数据
List<UserRecord> recordList
}
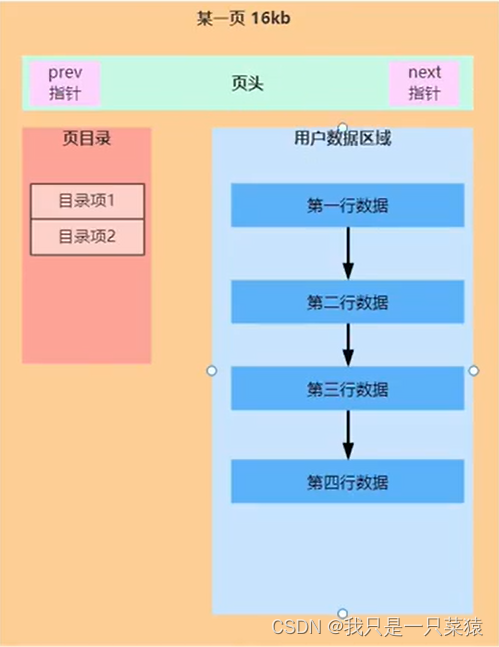
插入时,按照主键的顺序排序。如果是按照key为int,插入比较快,而uuid则插入比较慢。
SELECT * FROM T1 where a = 3;查询时把页从磁盘拿出来,比较主键是否相等,如果中间一个数据小于3,直接就放弃了当前页的数据,说明没查找到。
SELECT * FROM T1 where a = 30000;如果用随机比较,那时间复杂度为n2,通过页目录可以提高查询速度。页目录就是记录每一项的起始的序号。这样通过页目录可以立刻确定是在哪一组(空间换时间的算法)。
如果当前页已满了,就要重新再开一个页。而且还要确定插入数据的位置,如果采用uuid还需要修改原来数据的位置,就会严重影响性能。而如果采用自增,则直接在最后插入,不需移动数据位置。而且uuid数据长。
两页数据的存储
实际查询一个数据的时候不知道在哪一页(链表,还存在在磁盘),最笨的方法是从第一页开始查找,再根据页指针,查到到下一页,直到第N页。
于是,引出了页索引。索引中记录了每一页的起始位置(4字节)及指针(6字节),于是一页能存放(16 * 1024/10=1638页),于是两层的索引存储的数据量为1638 * 每一页存储的数据 = 1638 * (16KB/1KB) = 26208 (假设每条数据1KB),三层的B+树存储的数据量为 1638 * 1638 * (16KB/1KB) = 42928704。
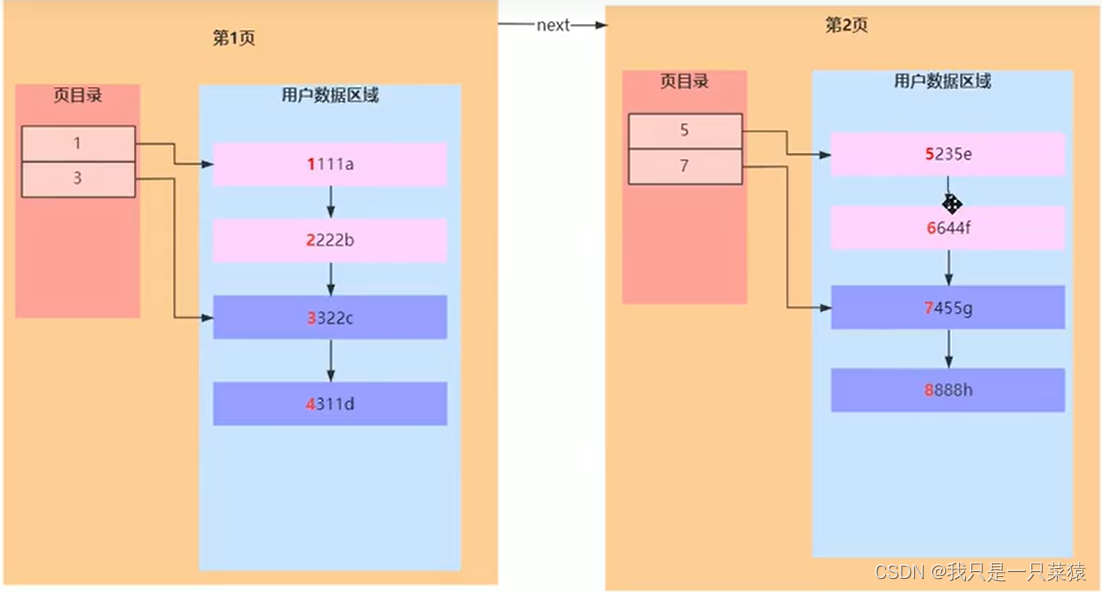
什么是聚簇索引
索引是一种数据结构,利用数据结构实现的快速查询。
索引树:红色的为索引树。橙色的为数据。
主键索引:索引和数据放在一块,就是聚簇索引。
select * from t1 where b = ‘6’。如果只有a的主键索引。所以这个sql就是全表扫描。
select * from where a > 6; 先找到a = 6.然后把 a后面的全部根据索引返回,因为索引是排序的。这里使用了后向指针。
select * from where a < 6;先找到a = 6.然后把 a后面的前部根据索引返回,因为索引是排序的。这里使用了前向指针。
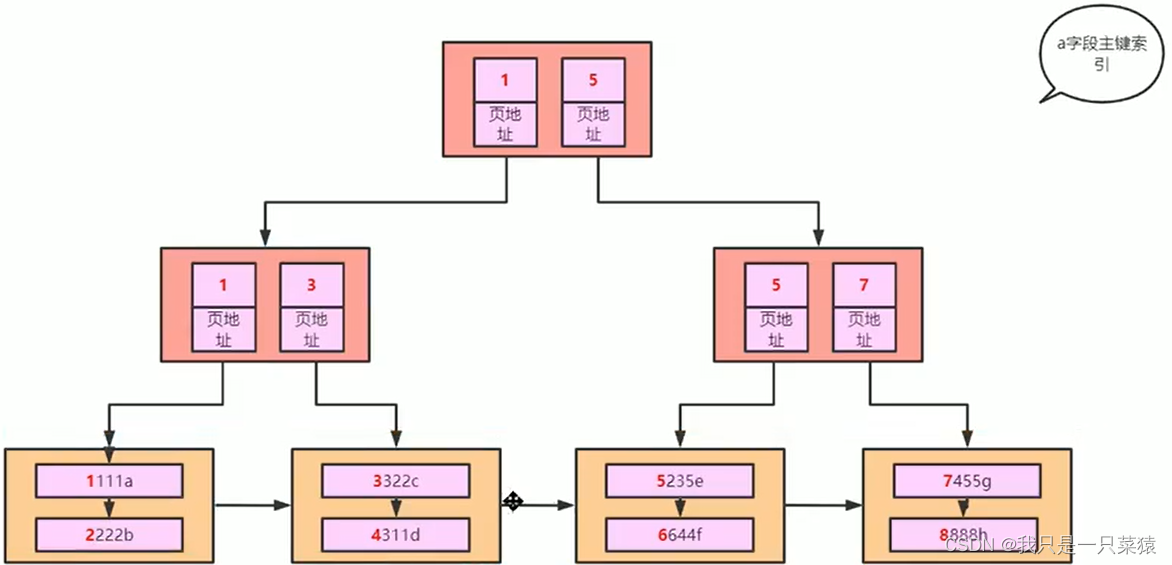
复合索引
例如索引为bcd字段。此时,如果。索引的key为bcd的值排序,key为页地址。然而这种结构有缺陷,数据复制,重复。更新的时候都需要重复更新。所以不能存全部数据,那么存储bcd值呢。再根据bcd无法找到其他字段,只能存储主键数据。
反面例子。
select * from t1 where b = 1 and c = 1 and d = 1;
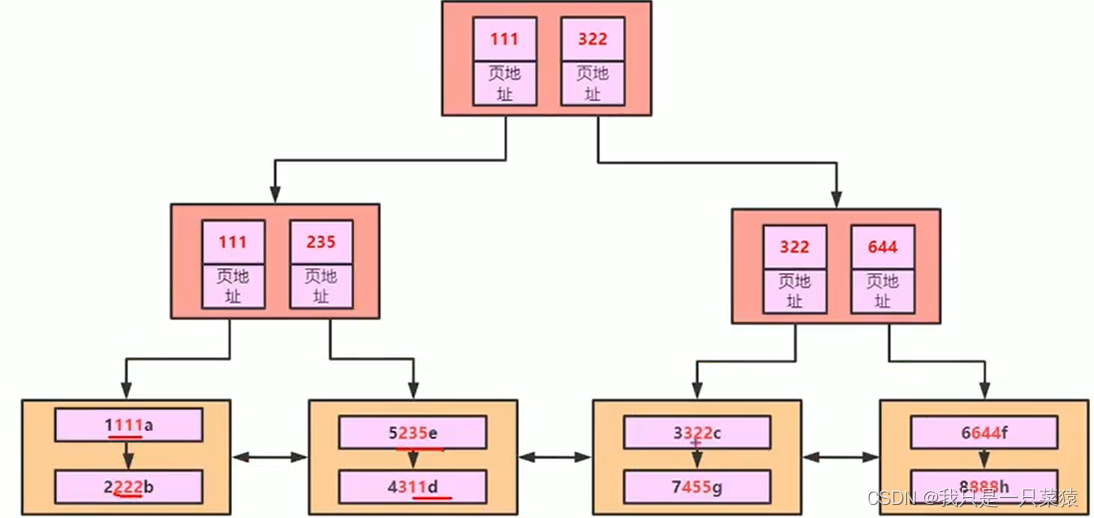
找到bcd索引页中的主键后,再回表查询所有数据。
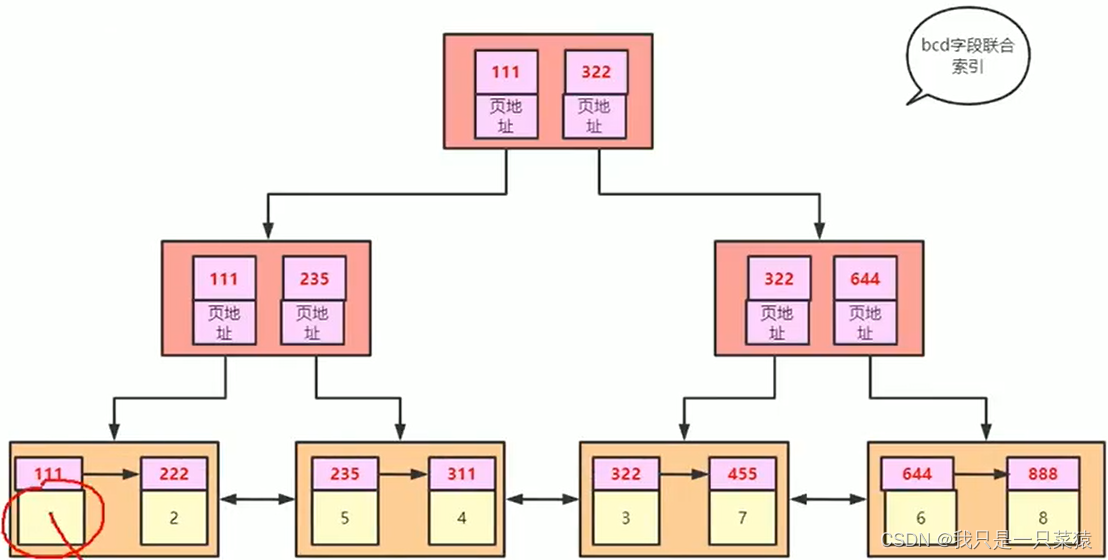
最左匹配原则
看给的条件(λ)中是否有索引(A)最左边的字段。如果有,就能使用。如果不包含就不能使用。
select * from t1 where c = 1 and d = 1 and b = 1; 也可以使用bcd索引。 – Using index condition
最左匹配原则。
select * from t1 where c = 1 and b = 1; 也可以使用bcd索引。因为包含b开头的索引。
(Using index condition)下面这个sql,先去遍历索引。找到索引页中的索引Key,去表中回表查找数据(回回标两次次)。Using index condition就是索引条件,即遍历时,已根据条件使用索引进行了遍历了。

select * from t1 where b > 1;-- 全表扫描。因为是全部字段。这种如果使用索引反而慢,因为都需要回表查询所有数据。而如果直接全表扫描则能省去索引中的消耗的时间。
select b from t1 where b > 1; – 覆盖索引。因为索引中包含要 查找的数据。
select b,c,d,a from t1 where b > 1;-- 覆盖索引。因为索引中包含要 查找的数据。

索引结构中不包含e,无法直接使用索引,只能使用索引过滤。

索引中包含b,可以直接使用索引。索引文件比较小。type = index (全索引扫描)相当于利用了索引文件中的b。因为没有where条件效率是不高的,因为这种是遍历二级索引。
下面这句sql:select c from t1;这里虽然没有c开头的索引,但是因为有的索引中全部包含当前查询字段,所以不需要全表扫描,而是直接在索引中把数据全部取数来,速度更快,需要加载的页更少。


order by
全表扫描:全表扫描+内存排序 + 不用回表。
走bcd索引:叶子节点的所有数据全表扫描,不需要排序,回表全部扫描数据。
下面这种情况数据量比较小,可以直接在内存中排序,因此采用全表扫描。而bcd索引需要回表好几次,速度是很慢的。

类型转换
where字段与条件不匹配
explain select * from t1 where a = ‘1’; – a为int,1为查找到时候字符转为数字1查找
explain select * from t1 where e = 1; – e为varchar类型,先把所有的e字段转换为int类型,再进行比较。只能全部加载,再进行转换。所以为全表扫描。
mysql转换的时候不是按照ascll码转换,而是把字符转换为数字0;
MVCC(多版本并发控制)
事务隔离级别怎么实现的。
读取的时候通过类似快照的方式,将数据保存下来,这样就将读锁和写锁就不冲突了,不同的事务session会看到自己特定版本的数据,版本链。
MVCC在RC级别下和RR级别下工作。其他两个级别不够和MVCC不兼容。因为RU总是读取最新的,不存在版本。SERIALIZABLE会读取时加锁。
聚簇索引记录有两个必要的隐藏列:trx_id:用来存储每次对某条聚簇索引有修改的时候的事务id。
roll_pointer:每次对哪条索引记录有修改的时候,都会把老版本的写入undo日志中。这个roll_pointer就是一个指针,它指向这条聚簇索引记录的上一个版本的位置,通过它来获得上一个版本的记录信息。
开启一个事务的时候创建ReadView,用来维护当前活动的事务id,即当前未提交的事务id,用来生成一个排序数组。访问数据,访问获取数据中的事务id,对比ReadView:
如果在ReadView的左边,可以访问(意味着该事务已经提交)。
如果在ReadView的右边,或者在ReadView中,就不可以访问。获取roll_pointer,取上一版本重新对比。(意味着该事务在readview生成之后创建,在ReadView中意味着该事务还未提交。)
RC:每次查询都会生成一个ReadView。(不可重复读)
RR:第一次读取的时候生成ReadView,之后都用之前的ReadView。可重复读的性能更高一些,因此也是默认的隔离级别的原因。















 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









