






前言
上一节实现了题目的整理,没整理答案是不完整的,所以这一节加上答案的爬取。
上一节地址:Python网络爬虫与信息提取(16)—— 题库爬取与整理
效果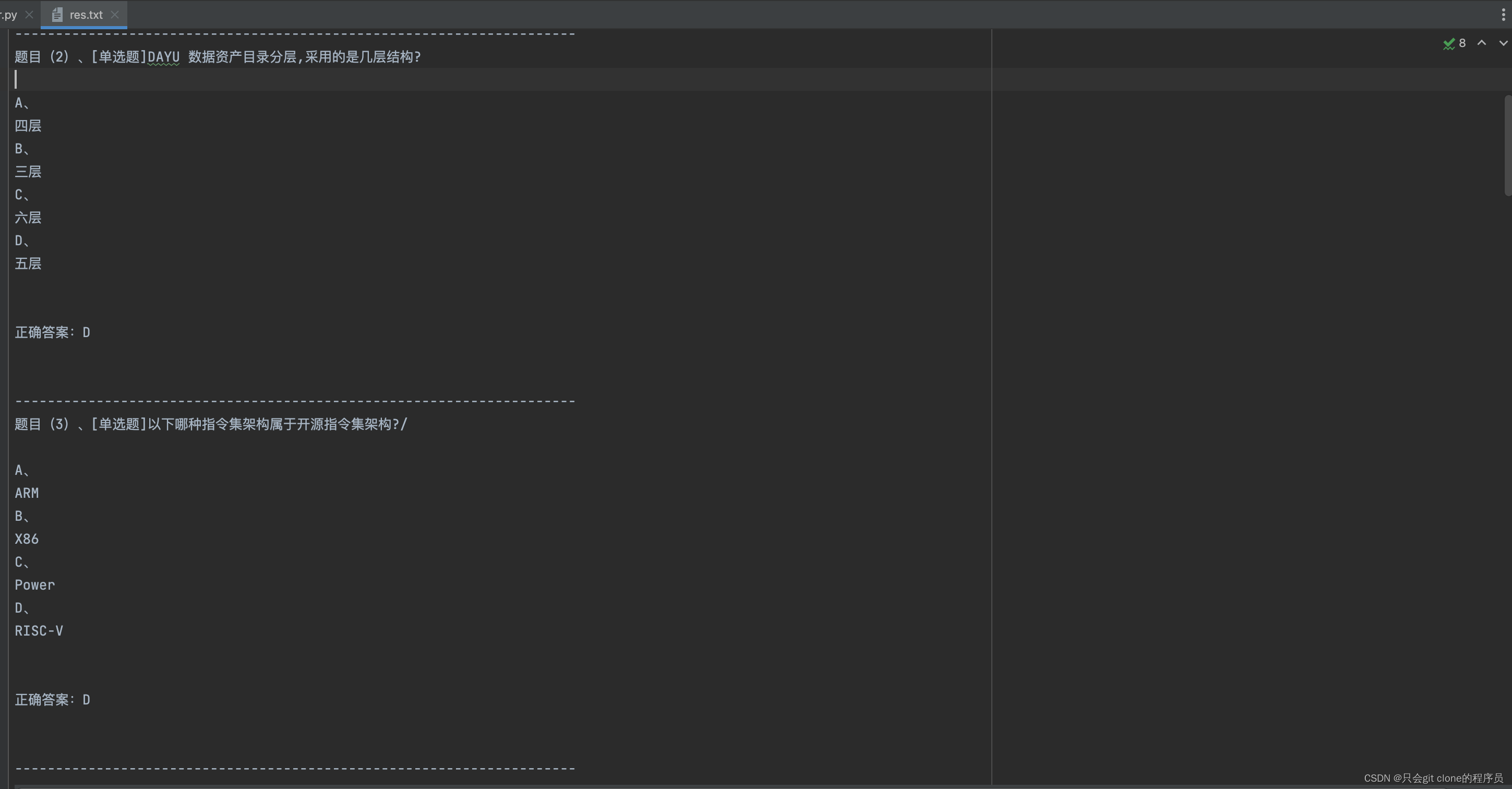
思路
爬答案有点难搞,像这种题库的答案都是要么要会员,要么要登陆账号才能看答案,这种就比较费劲了,解决方案有两种:
- 用控制台看点击查看答案会请求哪些接口,然后看看发送请求的格式以及返回response的格式来模拟查看答案。这个方法比较麻烦,因为你不是网站的开发人员,你需要猜他是个什么情况,而且有些会对数据加密,更看不出来了…
- 第二种比较万精油,控制浏览器自动化的处理然后检索数据就好了。
难点
- 答案的存储格式不唯一,因为题型有单选、多选、简答和填空,整理答案比较麻烦
- 网站有反扒,访问快了网页会404,再快了会封IP
- 网站的答案要登录才能看到,selenium每次控制浏览器会新起一个这样需要重新登陆,可以控制指定端口的谷歌浏览器来解决这个问题。
解决
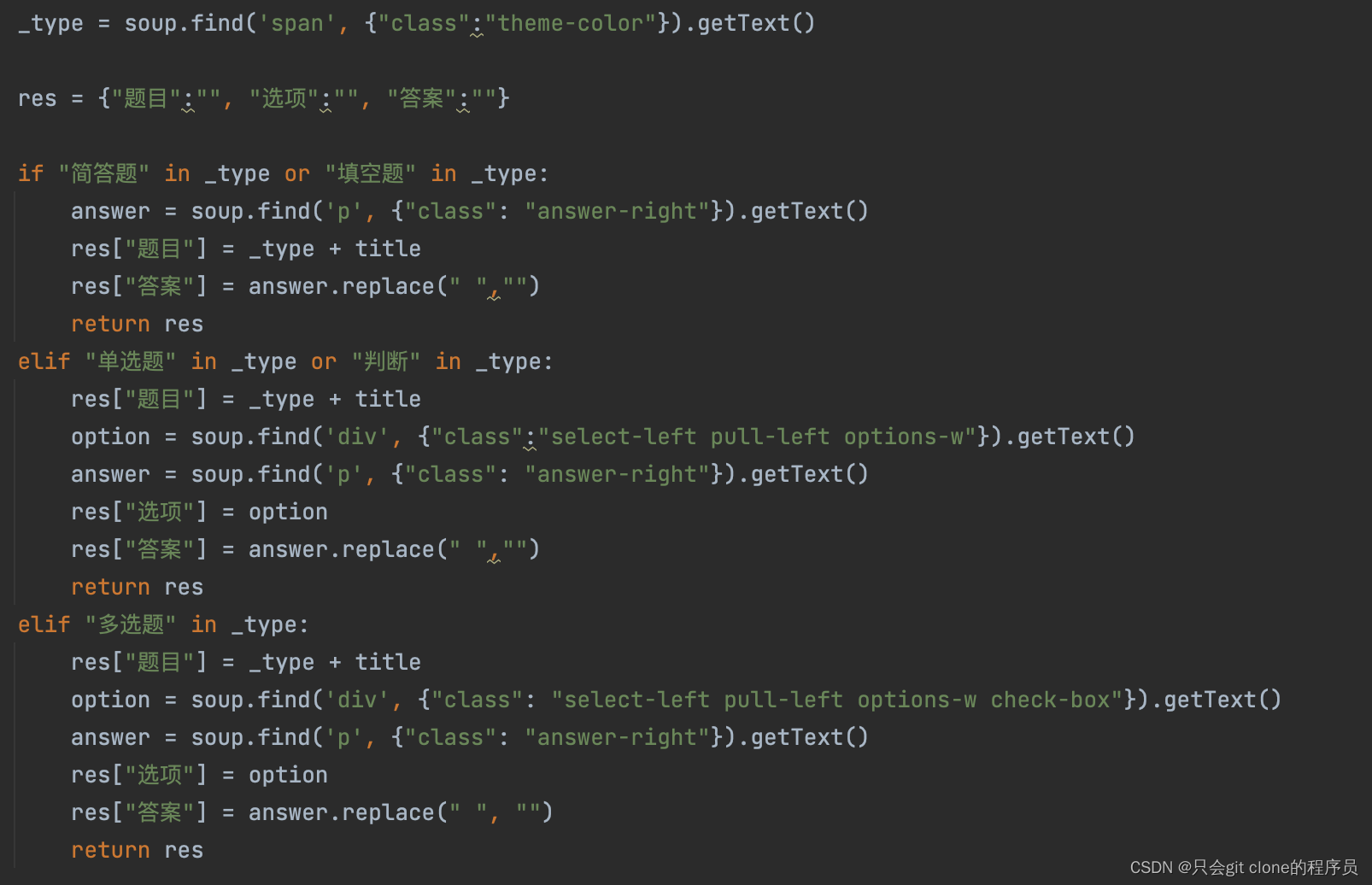
针对问题1: 先爬题目的类型标签,然后根据类型特殊处理
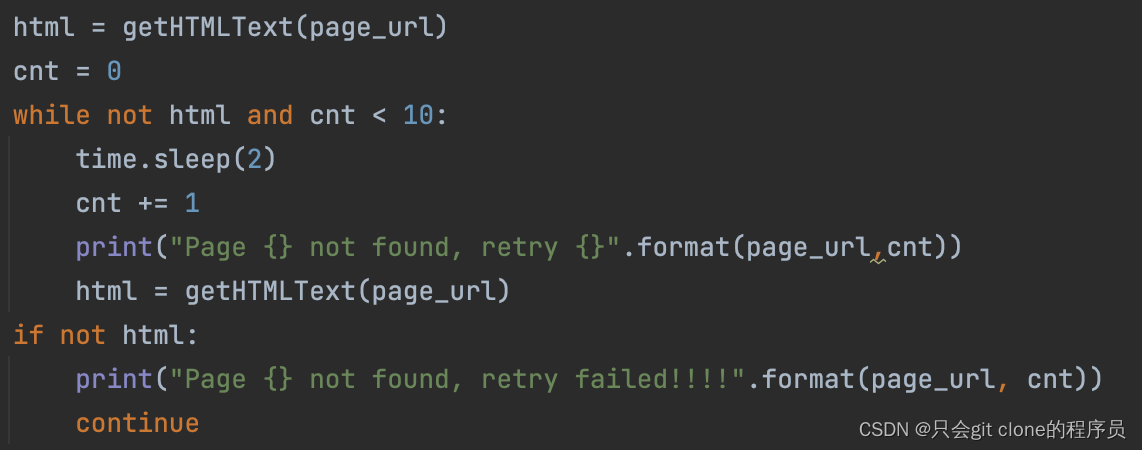
针对问题2,可以判断爬取的html是否为空,自己写retry机制,重试n次不成功才算失败:
针对问题3,可以用谷歌浏览器的debug模式,在本地指定的端口打开浏览器,mac的命令如下:
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --remote-debugging-port=9222 --user-data-dir="~/ChromeProfile"
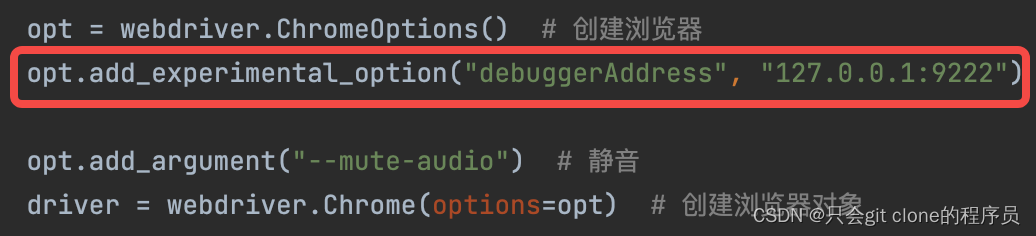
这样会在9222端口打开一个谷歌浏览器,然后在selenium的opt配置中加上一行即可:
然后就可以控制指定的9222端口的谷歌浏览器了,可以操作网页进行扫码登陆账号。
代码
import os
import requests as req
from bs4 import BeautifulSoup
from tqdm import tqdm
from selenium import webdriver
import ssl
import time
ssl._create_default_https_context = ssl._create_unverified_context
def getHTMLText(url):
try:
r = req.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def driver_get_answer(title, link, driver):
driver.get(link)
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
_type = soup.find('span', {"class":"theme-color"}).getText()
res = {"题目":"", "选项":"", "答案":""}
if "简答题" in _type or "填空题" in _type:
answer = soup.find('p', {"class": "answer-right"}).getText()
res["题目"] = _type + title
res["答案"] = answer.replace(" ","")
return res
elif "单选题" in _type or "判断" in _type:
res["题目"] = _type + title
option = soup.find('div', {"class":"select-left pull-left options-w"}).getText()
answer = soup.find('p', {"class": "answer-right"}).getText()
res["选项"] = option
res["答案"] = answer.replace(" ","")
return res
elif "多选题" in _type:
res["题目"] = _type + title
option = soup.find('div', {"class": "select-left pull-left options-w check-box"}).getText()
answer = soup.find('p', {"class": "answer-right"}).getText()
res["选项"] = option
res["答案"] = answer.replace(" ", "")
return res
else:
raise Exception("unexcepted type", _type)
def parse_html(html, base_href, driver):
soup = BeautifulSoup(html, "html.parser")
all_a = soup.find_all('a')
results = []
for a in all_a:
href = a.get("href")
title = a.get("title")
if href is not None and title is not None:
if "detail" in href:
time.sleep(0.2)
res = driver_get_answer(title, base_href + href, driver)
results.append(res)
return results
if __name__ == '__main__':
if not os.path.exists("./answer"):
os.mkdir("./answer")
base_url = "https://so.kaoshibao.com/paper/7629471.html?page={}"
base_href = "https://so.kaoshibao.com/"
n_page = 69
opt = webdriver.ChromeOptions() # 创建浏览器
opt.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
opt.add_argument("--mute-audio") # 静音
driver = webdriver.Chrome(options=opt) # 创建浏览器对象
results = []
for i in tqdm(range(1, n_page + 1)):
page_url = base_url.format(i)
html = getHTMLText(page_url)
cnt = 0
while not html and cnt < 10:
time.sleep(2)
cnt += 1
print("Page {} not found, retry {}".format(page_url,cnt))
html = getHTMLText(page_url)
if not html:
print("Page {} not found, retry failed!!!!".format(page_url, cnt))
continue
results += parse_html(html, base_href, driver)
print("total length: {}".format(len(results)))
with open("res.txt", "w") as w:
for idx, r in enumerate(results):
if len(r["选项"]) != 0:
w.write("题目({})、{}\n{}\n{}\n\n".format(idx, r["题目"],r["选项"],r["答案"]))
else:
w.write("题目({})、{}\n{}\n\n".format(idx, r["题目"], r["答案"]))
w.write("---------------------------------------------------------------------\n")


















 2738
2738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











