









Spark概述
定义
:spark是一种基于内存的快速、通用、可扩展的大数据分析引擎。
内置模块:
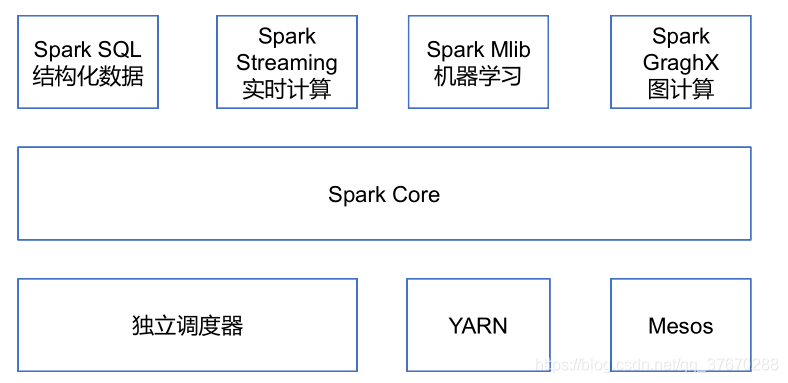
Spark Core:实现spark的基本功能,包括任务调度、内存管理、错误恢复、与存储系统交互等。还包含了对弹性分布式数据集RDD的定义
Spark SQL:是Spark用来操作结构化数据的程序包。
Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。
Spark MLlib:提供常见的机器学习功能的程序库。
Spark特点
1)快: 与MR相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。计算结果是存在内存的。
2)易用: 支持Java、Python、Scala的API,支持超过80多种高级算法。
3)通用: Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。
4)兼容性: Spark可以非常方便地与其他的开源产品进行融合。
运行模式
Local模式: 一般用于开发测试
Standalone模式: Spark自带
Yarn模式: 将Spark App提交到Yarn上执行,较常用。分为 yarn-client 和 yarn-cluster
Mesos: Apache的一个独立的资源调度,不常用
Spark Core
RDD定义
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据抽象。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD的属性
1. 一组分区Partition,即数据集的基本组成单位。
2. 一个计算每个分区的函数。
3. RDD之间的依赖关系
4. 一个PartitionerRDD分片函数。
如果数据类型为 K-V 形式,默认作用于HashPartitioner,另一种是RangePartitioner
5. 一个列表,存储每一个Partition的优先位置。
RDD特点
弹性
1. 存储的弹性:内存与磁盘的自动切换
Spark优先把数据放到内存中,如果内存放不下,就会放到磁盘。
2. 容错的弹性:数据丢失可以自动恢复
在RDD进行转换和动作的时候,会形成RDD的Lineage依赖链,当某一个RDD失效的时候,可以通过重新计算上游的RDD来重新生成丢失的RDD数据。
3. 计算的弹性:计算出错重试机制
1) Task如果失败会自动进行特定次数的重试
2) Stage如果失败会自动进行特定次数的重试
3) Checkpoint和Persist可主动或被动触发
RDD可以通过Persist持久化将RDD缓存到内存或磁盘,当再次用到该RDD时直接读取就行。
也可以将RDD进行Checkpoint,Checkpoint会将数据存储在HDFS中,该RDD的所有父RDD依赖都会被移除。
4) 数据调度弹性
Spark把这个JOB执行模型抽象为通用的有向无环图DAG,可以将多Stage的任务串联或并行执行,调度引擎自动处理Stage的失败以及Task的失败。
4. 分区的弹性:可根据需要重新分片
分区
RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个 compute 函数得到每一个分区的数据。如果 RDD 是通过已有的文件系统构建,则 compute 函数是读取指定文件系统中的数据,如果 RDD 是通过其他 RDD 转换而来,则 compute 函数是执行转换逻辑将其他 RDD 的数据进行转换。
只读
想要改变 RDD 的数据,只有在现有的 RDD 基础上创建新的 RDD。
数据抽象
RDD本身不存储数据,可以看作是一个数据引用
RDD缺陷
- 不支持细粒度的写和更新操作
- 不支持增量迭代计算
创建RDD方式
1. 并行化创建RDD(parallelize、makeRDD)
2. 读取本地或者HDFS文件创建RDD
3. RDD转换创建RDD
4. 通过外部数据源创建RDD
算子
- Transformation算子
常用:map、filter、flatMap、mapPartitions、mapPartitionsWithIndex、sample、union、intersection、distinct、groupByKey、reduceByKey、aggregateByKey、sortByKey、sortBy、join、cogroup、cartesian、pipe、coalesce、repartitionAndSortWithinPartitions、repartition - Action算子
常用:reduce、collect、count、first、take、takeSample、takeOrdered、saveAsTextFile、saveAsSequenceFile、countByKey、foreach - 特殊算子 – 触发Shuffle的算子
一系列的by或者bykey,cogroup,distinct、Repartition、countByKey等
foreach和foreachPartition的区别
foreach主要是基于输出打印使用,进行数据的显示;
foreachPartition的适用于各种的connection连接创建时候进行使用,保证每个分区内创建一个连接,提高执行效率,减少资源的消耗。
map与mapPartitions的区别
map是处理每一条数据,也就是说,执行效率稍低,而mapPartition是处理一个分区的数据,返回值是一个集合,也就是说,在效率方面后者效率更高,前者稍低,但是在执行安全性方面考虑,map更适合处理大数据量的数据,而mappartition适用于中小型数据量,如果数据量过大那么会导致程序的崩溃,或oom。
RDD依赖关系
Lineage: RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
窄依赖: 每一个父RDD的Partition最多被子RDD的一个Partition使用
宽依赖: 多个子RDD的Partition会依赖同一个父RDD的Partition。宽依赖会发生shuffle过程
DAG
DAG(Directed Acyclic Graph)叫做有向无环图,原始的 RDD 通过一系列的转换就就形成了 DAG,根据 RDD 之间的依赖关系的不同将 DAG 划分成不同的 Stage,对于窄依赖,partition 的转换处理在 Stage 中完成计算。对于宽依赖,由于有 Shuffle 的存在,只能在 parent RDD 处理完成后,才能开始接下来的计算,因此宽依赖是划分 Stage 的依据。
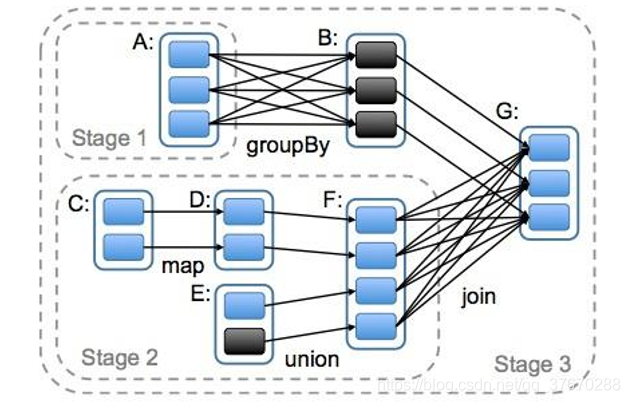
任务划分
1)Application:初始化一个 SparkContext 即生成一个 Application
2)Job:一个 Action 算子就会生成一个 Job
3)Stage:根据 RDD 之间的依赖关系的不同将 Job 划分成不同的 Stage,遇到一个宽依赖则划分一个 Stage。
4)Task:Stage 是一个 TaskSet,将 Stage 划分的结果发送到不同的 Executor 执行即为一个Task。
注意:Application->Job->Stage->Task 每一层都是 1 对 n 的关系。
持久化
spark通过cache和persist方法对结果进行一个持久化,persist方法共有5个参数,对应12个缓存级别,这12个级别分别从磁盘存储、内存存储、堆外内存存储、是否反序列化和备份数五个角度设定。其中catch使用的是Memory_Only,只在内存持久化。
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于 RDD 的一系列转换,丢失的数据会被重新计算,由于 RDD 的各个 Partition 是相对独立的,因此只需要计算丢失的部分即可。
使用场景:
某个步骤计算非常耗时
计算链条非常长,重新恢复要算很多步骤
发生shuffle之后
CheakPoint
本质就是通过将 RDD 写入 Disk 做检查点。通过 Lineage 做容错为辅助,如果 Lineage 过长会造成容错成本过高,如果在中间阶段做检查点容错,可以减少开销。
spark通过checkPoint方法将RDD状态保存在高可用存储中,与持久化不同的是,它是对RDD状态的一个复制持久化,执行checkPoint后不再保存依赖链。此外,持久化存储的缓存当程序运行结束后就会被自动删除,检查点保存的RDD状态只能手动清理。
广播变量(Broadcast)
正常情况下spark为每个Task都复制了一份它需要的数据,如果有大量Task都需要用到一份相同的数据,这种做法就会导致一个节点Excutor(内含多个Task)从driver端拉取大量重复数据,占用网络IO和内存资源。使用广播变量后,Task会惰性加载数据,加载时,先在本地Excutor的BlockManager中寻找,如果找不到再到最近节点的BlockManager中查找,直到找到数据后将数据传输到本地存储起来,同一节点的多个Task就可以复用这份数据,大幅减少内存占用和IO时间。
使用场景:比如在本地有字典文件,需要读取,并且不是太大,那么此时可以使用广播变量将其广播到executor内存中,供给每个Task进行使用,减少数据冗余性,提高效率
释放广播变量 unpersist
累加器(Accumulator)
spark提供了一个累加器用于在整个流程中额外执行一个MR任务,它可以在driver端被初始化发送给各个Task,然后在每个Task中为它添加数据,最终经过reduce将结果聚合后返回driver端。
使用步骤:1.创建累加器 2.注册累加器 3.使用累加器
AccumulatorV2 new -> sc.register -> .add来添加数据 ->.value获取值
自定义累加器:
可以任意累加不同类型的值,同时也可以在内部进行计算,或者逻辑编写,如果继承自定义累加器 AccumulatorV2,那么需要实现内部的抽象方法,然后在每个抽象方法内部去累加变量值即可,主要是在全局性累加起到决定性作用。
package com.atguigu.spark
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.JavaConversions._
class LogAccumulator extends org.apache.spark.util.AccumulatorV2[String, java.util.Set[String]] {
private val _logArray: java.util.Set[String] = new java.util.HashSet[String]()
override def isZero: Boolean = {
_logArray.isEmpty
}
override def reset(): Unit = {
_logArray.clear()
}
override def add(v: String): Unit = {
_logArray.add(v)
}
override def merge(other: org.apache.spark.util.AccumulatorV2[String, java.util.Set[String]]): Unit = {
other match {
case o: LogAccumulator => _logArray.addAll(o.value)
}
}
override def value: java.util.Set[String] = {
java.util.Collections.unmodifiableSet(_logArray)
}
override def copy():org.apache.spark.util.AccumulatorV2[String, java.util.Set[String]] = {
val newAcc = new LogAccumulator()
_logArray.synchronized{
newAcc._logArray.addAll(_logArray)
}
newAcc
}
}
// 过滤掉带字母的
object LogAccumulator {
def main(args: Array[String]) {
conf=new SparkConf().setAppName("LogAccumulator")
val sc=new SparkContext(conf)
val accum = new LogAccumulator
sc.register(accum, "logAccum")
val sum = sc.parallelize(Array("1", "2a", "3", "4b", "5", "6", "7cd", "8", "9"), 2).filter(line => {
val pattern = """^-?(\d+)"""
val flag = line.matches(pattern)
if (!flag) {
accum.add(line)
}
flag
}).map(_.toInt).reduce(_ + _)
println("sum: " + sum)
for (v <- accum.value) print(v + "")
println()
sc.stop()
}
}
自定义排序
- ordered 未序列化
- ordering 已序列化
分区
1. 概念
分区是RDD内部并行计算的一个计算单元,是RDD数据集的逻辑分片,分区的格式决定并行计算的粒度,分区的个数决定任务的个数。
分区器直接决定 RDD 中分区的个数、RDD 中每条数据经过 Shuffle 过程属于哪个分区和 Reduce 的个数。
注意:
(1)只有 Key-Value 类型的 RDD 才有分区的,非 Key-Value 类型的 RDD 分区的值是 None
(2)每个 RDD 的分区 ID 范围:0~numPartitions-1,决定这个值是属于哪个分区的。
2. 作用
通过将相同的key放在相同的节点,避免不同节点聚合key时进行shuffle操作产生的网络IO;此外,事先分区好的数据在join时就可以只由另一张表shuffle,自身不shuffle,这常常用在大表join小表上。
3. 默认分区器
HashPartitioner:将key的哈希值 / 分区数量取余,如果余数小于 0,则用余数+分区的个数(否则加 0),最后返回的值就是这个 key 所属的分区 ID。HashPartitioner 分区弊端:可能导致每个分区中数据量的不均匀,极端情况下会导致某些分区拥有 RDD 的全部数据。
可选分区器RangePartitioner:范围分区器,按照字典顺序或数字大小排序后 / 分区数量来分区(水塘抽样)。将一定范围内的数据映射到某个分区,尽量保证每个分区中数据量的均匀,而且分区与分区之间有序,也就是说一个分区中的元素肯定都比另一个分区内的元素小或大,但分区内的元素不能保证顺序。
分区规则
如果是读取读取hdfs,引用MR的方法partitons=blocks=split
4. 自定义分区器
通过实现get分区总数方法和get分区数方法,指定自定义规则的key分区方式;
使用自定义分区器创建的RDD进行复杂的聚合或join操作效率更高。
继承org.apache.spark.Partitioner 类并实现一下三个方法
1) numPartitions:Int 返回创建出来的分区数
2) getPartition(key:Int):Int 返回给定键的分区编号(0到numPartitions -1)
3) equals():Java判断相等性的标准方法。Spark需要用这个方法来检查分区器对象是否和其他分区器实例相同,以此判断两个RDD的分区方式是否相同。
自定义分区也是传给 partitionBy( ) 方法即可使用














 2598
2598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









