Gensim中的Dictionary最大的功能就是产生稀疏文档向量,gensim.corpora.dictionary.Dictionary类为每个出现在语料库中的单词分配了一个独一无二的整数编号
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#
# Copyright (C) 2010 Radim Rehurek <radimrehurek@seznam.cz>
# Licensed under the GNU LGPL v2.1 - http://www.gnu.org/licenses/lgpl.html
"""
这个模块实现了字典的概念—单词之间的映射
他们的整数id。
字典可以从一个语料库中创建,然后可以根据
文档频率(通过:func:Dictionary:删除(un)常用单词。filter_extremes”方法),
从磁盘(通过:func:字典。保存和func:字典。负载的方法),合并
与其他字典(:func:dictionary.归并)等。
"""
from __future__ import with_statement
from collections import Mapping, defaultdict
import sys
import logging
import itertools
from gensim import utils
from six import PY3, iteritems, iterkeys, itervalues, string_types
from six.moves import xrange
from six.moves import zip as izip
if sys.version_info[0] >= 3:
unicode = str
logger = logging.getLogger('gensim.corpora.dictionary')
class Dictionary(utils.SaveLoad, Mapping):
"""
Dictionary封装了规范化单词和它们的整数id之间的映射。
它的主要功能是doc2bow,它将一组单词转换为它的集合。
词汇表表示:一个(wordid,word频度)2元组的列表。
"""
def __init__(self, documents=None, prune_at=2000000):
"""
如果给出了文档,请使用它们来初始化字典(参见adddocuments())。
"""
self.token2id = {} # token -> tokenId
self.id2token = {} # reverse mapping for token2id; only formed on request, to save memory
self.dfs = {} # document frequencies: tokenId -> in how many documents this token appeared
self.num_docs = 0 # number of documents processed
self.num_pos = 0 # total number of corpus positions
self.num_nnz = 0 # total number of non-zeroes in the BOW matrix
if documents is not None:
self.add_documents(documents, prune_at=prune_at)
def __getitem__(self, tokenid):
if len(self.id2token) != len(self.token2id):
# id映射已经改变了(可能是通过adddocuments);
#验算id - >相应单词
self.id2token = dict((v, k) for k, v in iteritems(self.token2id))
return self.id2token[tokenid] # will throw for non-existent ids
def __iter__(self):
return iter(self.keys())
if PY3:
# restore Py2-style dict API
iterkeys = __iter__
def iteritems(self):
return self.items()
def itervalues(self):
return self.values()
def keys(self):
"""Return a list of all token ids."""
return list(self.token2id.values())
def __len__(self):
"""
Return the number of token->id mappings in the dictionary.
"""
return len(self.token2id)
def __str__(self):
some_keys = list(itertools.islice(iterkeys(self.token2id), 5))
return "Dictionary(%i unique tokens: %s%s)" % (len(self), some_keys, '...' if len(self) > 5 else '')
@staticmethod
def from_documents(documents):
return Dictionary(documents=documents)
def add_documents(self, documents, prune_at=2000000):
"""
从一组文档中更新字典。每个文档都是一个列表
令牌=令牌化和规范化的字符串(utf8或unicode)。
这是一个方便的包装器,用于在每个文档中调用doc2蝴蝶结
在“允许更新=True”的情况下,它还会删除不常出现的单词,保留
唯一的单词的总数。这是为了节省内存
大的输入。要禁用这个修剪,设置修剪修剪=None。
>>> print(Dictionary(["máma mele maso".split(), "ema má máma".split()]))
Dictionary(5 unique tokens)
"""
for docno, document in enumerate(documents):
# log progress & run a regular check for pruning, once every 10k docs
if docno % 10000 == 0:
if prune_at is not None and len(self) > prune_at:
self.filter_extremes(no_below=0, no_above=1.0, keep_n=prune_at)
logger.info("adding document #%i to %s", docno, self)
# update Dictionary with the document
self.doc2bow(document, allow_update=True) # ignore the result, here we only care about updating token ids
logger.info(
"built %s from %i documents (total %i corpus positions)",
self, self.num_docs, self.num_pos)
def doc2bow(self, document, allow_update=False, return_missing=False):
"""
将文档(一个单词列表)转换成词汇表格式=列表
”(token_id token_count)的集合。每个词都被假定为a
标记化和规范化的字符串(unicode或utf-8编码的)。没有进一步的预处理
是在文档中完成的;应用标记化,阻止等等
调用该方法。
如果设置了允许更新,那么也可以在过程中更新字典:创建
ids的新单词。同时,更新文档频率——
每个单词出现在这个文档中,增加它的文档频率(self。dfs)
由一个。
如果没有设置允许更新,那么这个函数是const,也就是只读。
"""
if isinstance(document, string_types):
raise TypeError("doc2bow expects an array of unicode tokens on input, not a single string")
# Construct (word, frequency) mapping.
counter = defaultdict(int)
for w in document:
counter[w if isinstance(w, unicode) else unicode(w, 'utf-8')] += 1
token2id = self.token2id
if allow_update or return_missing:
missing = dict((w, freq) for w, freq in iteritems(counter) if w not in token2id)
if allow_update:
for w in missing:
# new id = number of ids made so far;
# NOTE this assumes there are no gaps in the id sequence!
token2id[w] = len(token2id)
result = dict((token2id[w], freq) for w, freq in iteritems(counter) if w in token2id)
if allow_update:
self.num_docs += 1
self.num_pos += sum(itervalues(counter))
self.num_nnz += len(result)
# increase document count for each unique token that appeared in the document
dfs = self.dfs
for tokenid in iterkeys(result):
dfs[tokenid] = dfs.get(tokenid, 0) + 1
# return tokenids, in ascending id order
result = sorted(iteritems(result))
if return_missing:
return result, missing
else:
return result
def filter_extremes(self, no_below=5, no_above=0.5, keep_n=100000, keep_tokens=None):
"""
过滤掉出现在
1。少于以下的文件(绝对数量)
2。多于以上的文档(总数的一小部分,不是
绝对数量)。
3。如果在keeptoken(字符串列表)中给定了令牌,它们将保持不受任何限制
no下图和no上方设置
4。在(1)之后(2)和(3),只保留第一个最常出现的令牌(或
把所有如果“没有”)。
修剪之后,缩小单词id的差距。
注意:由于差距缩小,同一个词可能有不同的意思。
在调用这个函数之前和之后的单词id!
"""
no_above_abs = int(no_above * self.num_docs) # 将分数阈值转换为绝对阈值
#确定要保留哪些标记
if keep_tokens:
keep_ids = [self.token2id[v] for v in keep_tokens if v in self.token2id]
good_ids = (
v for v in itervalues(self.token2id)
if no_below <= self.dfs.get(v, 0) <= no_above_abs or v in keep_ids
)
else:
good_ids = (
v for v in itervalues(self.token2id)
if no_below <= self.dfs.get(v, 0) <= no_above_abs)
good_ids = sorted(good_ids, key=self.dfs.get, reverse=True)
if keep_n is not None:
good_ids = good_ids[:keep_n]
bad_words = [(self[id], self.dfs.get(id, 0)) for id in set(self).difference(good_ids)]
logger.info("discarding %i tokens: %s...", len(self) - len(good_ids), bad_words[:10])
logger.info(
"keeping %i tokens which were in no less than %i and no more than %i (=%.1f%%) documents",
len(good_ids), no_below, no_above_abs, 100.0 * no_above)
# 执行实际的筛选,然后重新构建字典,以消除ids中的空白。
self.filter_tokens(good_ids=good_ids)
logger.info("resulting dictionary: %s", self)
def filter_n_most_frequent(self, remove_n):
"""
过滤掉出现在文档中的“removen”最频繁的标记。
修剪之后,缩小单词id的差距。
注意:由于差距缩小,同一个词可能有不同的意思。
在调用这个函数之前和之后的单词id!
"""
# determine which tokens to keep
most_frequent_ids = (v for v in itervalues(self.token2id))
most_frequent_ids = sorted(most_frequent_ids, key=self.dfs.get, reverse=True)
most_frequent_ids = most_frequent_ids[:remove_n]
# 执行实际的筛选,然后重新构建字典,以消除ids中的空白。
most_frequent_words = [(self[id], self.dfs.get(id, 0)) for id in most_frequent_ids]
logger.info("discarding %i tokens: %s...", len(most_frequent_ids), most_frequent_words[:10])
self.filter_tokens(bad_ids=most_frequent_ids)
logger.info("resulting dictionary: %s" % self)
def filter_tokens(self, bad_ids=None, good_ids=None):
"""
从所有字典映射中删除选定的badids令牌,或者,保持
在映射中选择好的id并删除其余的。
badids和goodids是要删除的word id集合。
"""
if bad_ids is not None:
bad_ids = set(bad_ids)
self.token2id = dict((token, tokenid)
for token, tokenid in iteritems(self.token2id)
if tokenid not in bad_ids)
self.dfs = dict((tokenid, freq)
for tokenid, freq in iteritems(self.dfs)
if tokenid not in bad_ids)
if good_ids is not None:
good_ids = set(good_ids)
self.token2id = dict((token, tokenid)
for token, tokenid in iteritems(self.token2id)
if tokenid in good_ids)
self.dfs = dict((tokenid, freq)
for tokenid, freq in iteritems(self.dfs)
if tokenid in good_ids)
self.compactify()
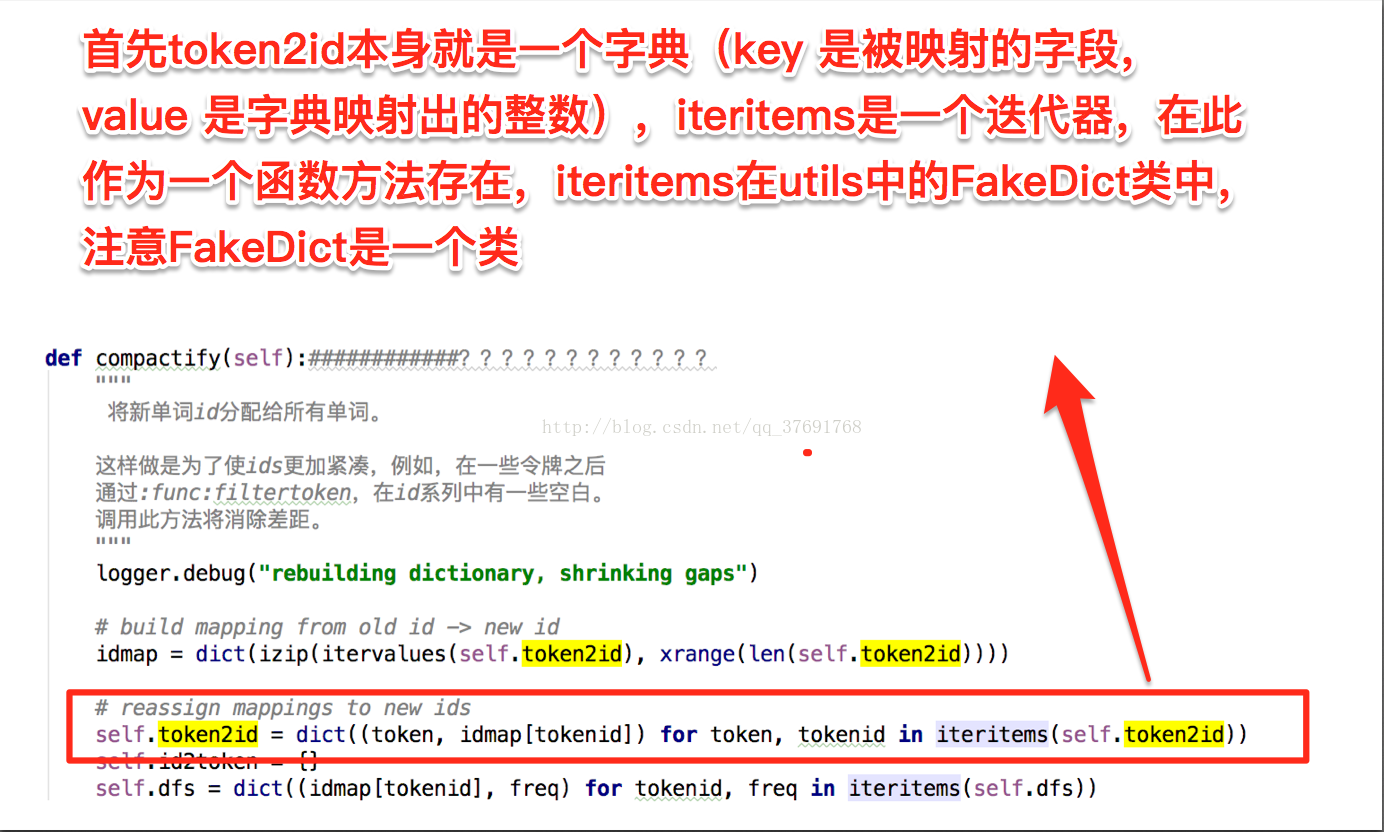
def compactify(self):############????????????
"""
将新单词id分配给所有单词。
这样做是为了使ids更加紧凑,例如,在一些令牌之后
通过:func:filtertoken,在id系列中有一些空白。
调用此方法将消除差距。
"""
logger.debug("rebuilding dictionary, shrinking gaps")
# build mapping from old id -> new id
idmap = dict(izip(itervalues(self.token2id), xrange(len(self.token2id))))
# reassign mappings to new ids
self.token2id = dict((token, idmap[tokenid]) for token, tokenid in iteritems(self.token2id))
self.id2token = {}
self.dfs = dict((idmap[tokenid], freq) for tokenid, freq in iteritems(self.dfs))
def save_as_text(self, fname, sort_by_word=True):
"""
将该字典保存到文本文件中,格式为:
“num_docs”
“id[TAB]word_utf8[TAB]文档频率(换行符)”。按词,
或者通过减少单词频率。
注意:文本格式应该用于语料检查。使用“保存”/“负载”
存储二进制格式(pickle)以提高性能。
"""
logger.info("saving dictionary mapping to %s", fname)
with utils.smart_open(fname, 'wb') as fout:
numdocs_line = "%d\n" % self.num_docs
fout.write(utils.to_utf8(numdocs_line))
if sort_by_word:
for token, tokenid in sorted(iteritems(self.token2id)):
line = "%i\t%s\t%i\n" % (tokenid, token, self.dfs.get(tokenid, 0))
fout.write(utils.to_utf8(line))
else:
for tokenid, freq in sorted(iteritems(self.dfs), key=lambda item: -item[1]):
line = "%i\t%s\t%i\n" % (tokenid, self[tokenid], freq)
fout.write(utils.to_utf8(line))
def merge_with(self, other):
"""
将另一个字典合并到这个字典中,将相同的标记映射到
相同的id和新的id到新的id。其目的是合并两家公司
用两种不同的字典创建,一种是自我,另一种是另一种。
其他可以是任何id=单词映射(一个字典,一个字典对象,…)。
返回一个转换对象,当被访问为其他文集的结果文档时,
将从使用另一个字典构建的语料库中转换文档
合并成一个文档使用新的字典(见:类:“gensim.interfaces.TransformationABC”)。
Example:
>>> dict1 = Dictionary(some_documents)
>>> dict2 = Dictionary(other_documents) # ids not compatible with dict1!
>>> dict2_to_dict1 = dict1.merge_with(dict2)
>>> # now we can merge corpora from the two incompatible dictionaries into one
>>> merged_corpus = itertools.chain(some_corpus_from_dict1, dict2_to_dict1[some_corpus_from_dict2])
"""
old2new = {}
for other_id, other_token in iteritems(other):
if other_token in self.token2id:
new_id = self.token2id[other_token]
else:
new_id = len(self.token2id)
self.token2id[other_token] = new_id
self.dfs[new_id] = 0
old2new[other_id] = new_id
try:
self.dfs[new_id] += other.dfs[other_id]
except:
# `other` isn't a Dictionary (probably just a dict) => ignore dfs, keep going
pass
try:
self.num_docs += other.num_docs
self.num_nnz += other.num_nnz
self.num_pos += other.num_pos
except:
pass
import gensim.models
return gensim.models.VocabTransform(old2new)
@staticmethod
def load_from_text(fname):
"""
从一个文本文件加载一个先前存储的字典。
镜像功能“save_as_text”。
"""
result = Dictionary()
with utils.smart_open(fname) as f:
for lineno, line in enumerate(f):
line = utils.to_unicode(line)
if lineno == 0:
if line.strip().isdigit():
# Older versions of save_as_text may not write num_docs on first line.
result.num_docs = int(line.strip())
continue
else:
logging.warning("Text does not contain num_docs on the first line.")
try:
wordid, word, docfreq = line[:-1].split('\t')
except Exception:
raise ValueError("invalid line in dictionary file %s: %s"
% (fname, line.strip()))
wordid = int(wordid)
if word in result.token2id:
raise KeyError('token %s is defined as ID %d and as ID %d' % (word, wordid, result.token2id[word]))
result.token2id[word] = wordid
result.dfs[wordid] = int(docfreq)
return result
@staticmethod
def from_corpus(corpus, id2word=None):
"""
从已有的语料库创建字典。如果你只做这个,这是很有用的
有一个term-document弓矩阵(用文集表示),但不是
原始文本语料库。
这将扫描所有单词id的term-文档计数矩阵
出现在它中,然后构造和返回字典,映射每一个
“word_id - > id2word[word_id]”。
id2word是一个可选的字典,它将wordid映射到一个令牌。在
案例id2word没有指定映射id2word wordid=str(wordid)
就会被使用。
"""
result = Dictionary()
max_id = -1
for docno, document in enumerate(corpus):
if docno % 10000 == 0:
logger.info("adding document #%i to %s", docno, result)
result.num_docs += 1
result.num_nnz += len(document)
for wordid, word_freq in document:
max_id = max(wordid, max_id)
result.num_pos += word_freq
result.dfs[wordid] = result.dfs.get(wordid, 0) + 1
if id2word is None:
# make sure length(result) == get_max_id(corpus) + 1
result.token2id = dict((unicode(i), i) for i in xrange(max_id + 1))
else:
# id=>word mapping given: simply copy it
result.token2id = dict((utils.to_unicode(token), id) for id, token in iteritems(id2word))
for id in itervalues(result.token2id):
# 确保所有令牌id都有一个有效的dfs条目
result.dfs[id] = result.dfs.get(id, 0)
logger.info(
"built %s from %i documents (total %i corpus positions)",
result, result.num_docs, result.num_pos)
return result

























 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









