



当前,大模型技术发展如火如荼,相信不少小伙伴和我一样,接到了“将智能对话功能集成到公司现有应用中”的任务。我们公司内部也提出了两种方案:一种是自行采购GPU服务器,部署开源大模型;另一种是直接接入多家大模型提供的API接口。经过详细的成本与效益分析,我们最终选择了接入大模型API的方式。
初期我们主要依赖各家大模型的Token调用服务,但在业务高峰时段,响应延迟明显增加,用户体验受到一定影响。经过多轮调研,我们发现了一个专注于AI出海场景的算力云服务——GMI Cloud。它不仅支持一键调用多家主流大模型API,还提供H200等大型GPU租赁服务,支持企业部署自有的大模型平台,是全球六大 Reference Platform NVIDIA Cloud Partner之一。
引入GMI Cloud之后,我们的服务响应效率显著提升,处理能力也更加稳定。因此,本文想和大家分享GMI Cloud在实际应用中的出色表现和强大功能。
🎈GMI Cloud Inference Engine 新用户友好,免费体验得token
GMI Cloud Inference Engine是一家全球领先的 AI Native Cloud(AI原生云)服务提供商,专注于为人工智能应用提供高性能的GPU云计算服务。它致力于通过其全球分布的算力基础设施和自研技术,帮助企业(尤其是在出海场景下的AI企业)高效、经济地部署和运行AI应用。底层搭载H100/H200芯片,集成全球近百个最前沿的大语言模型和视频生成模型,如DeepSeek V3.1, GPT OSS, Qwen3, Wan 2.2, Seedance 1.0等,为AI开发者与企业提供速度更快、质量更高的模型服务。
免费领取海量token步骤如下:
1、PC端登录https://console.gmicloud.ai
2、点击右上方 Log In

3、点击右上角余额,再点击Redeem it here,然后输入兑换码:TRYIENOW ,领取免费使用额度
🎈初试水:用API快速搞定智能对话功能
前提说明:为了防止泄露公司机密,接下来的例子中我都是使用的测试案例
为什么我选择了API调用方案
采用GMI Cloud预先配置的端点,允许用户直接将AI模型用作与OpenAI兼容的API,而无需进行大量设置。此功能简化了集成过程,提供以下好处:
- 开箱即用功能:立即访问预先配置为与OpenAI标准无缝协作的AI模型。
- 可扩展性:根据应用程序的需求自动扩展,确保高可用性和性能,无需手动干预。
- 成本效益:只需为使用付费,无需维护基础设施。
实操分享:10分钟完成千问大模型集成
因为公司产品是把智能对话千问大模型、DeepSeek大模型集成到产品中,所以采用购买GMI Cloud中Token的形式来按量付费,这种灵活性比较高,可以选用不同的大模型进行使用,能够满足用户不同的使用需求,下边采用千问大模型举个例子:
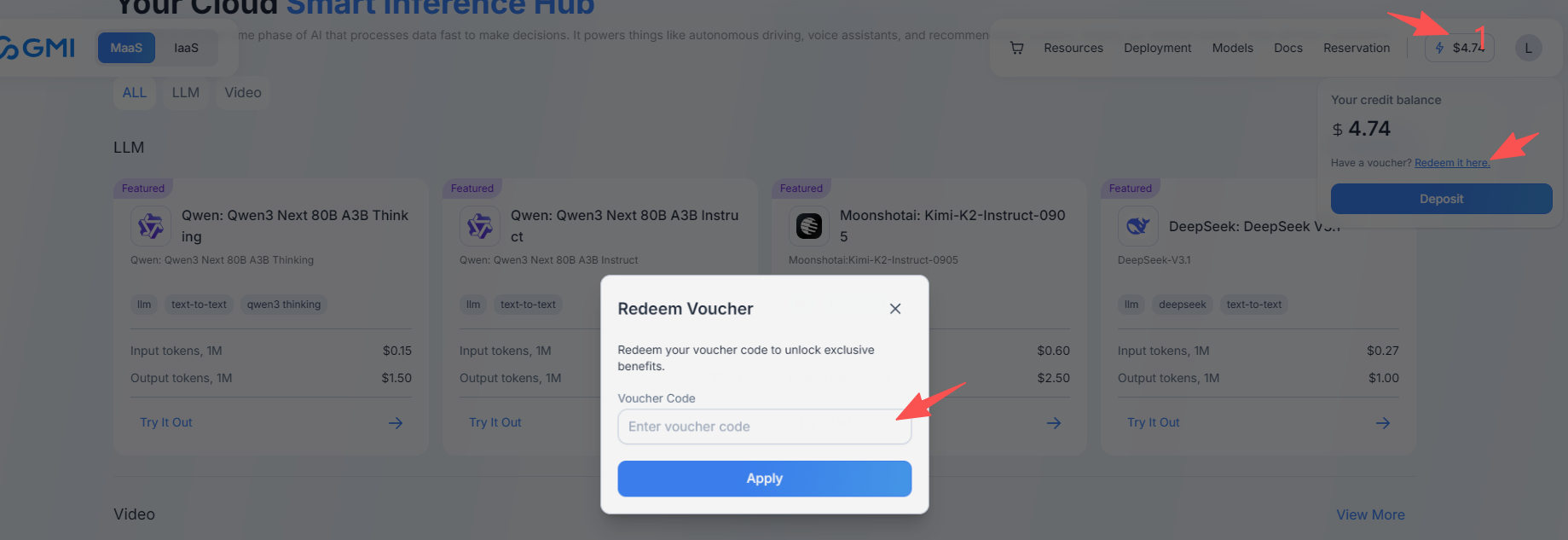
1、先申请一个APIKEY【注意申请之后复制保存,因为创建后只出现一次】
https://console.gmicloud.ai/user-setting/organization/api-key-management
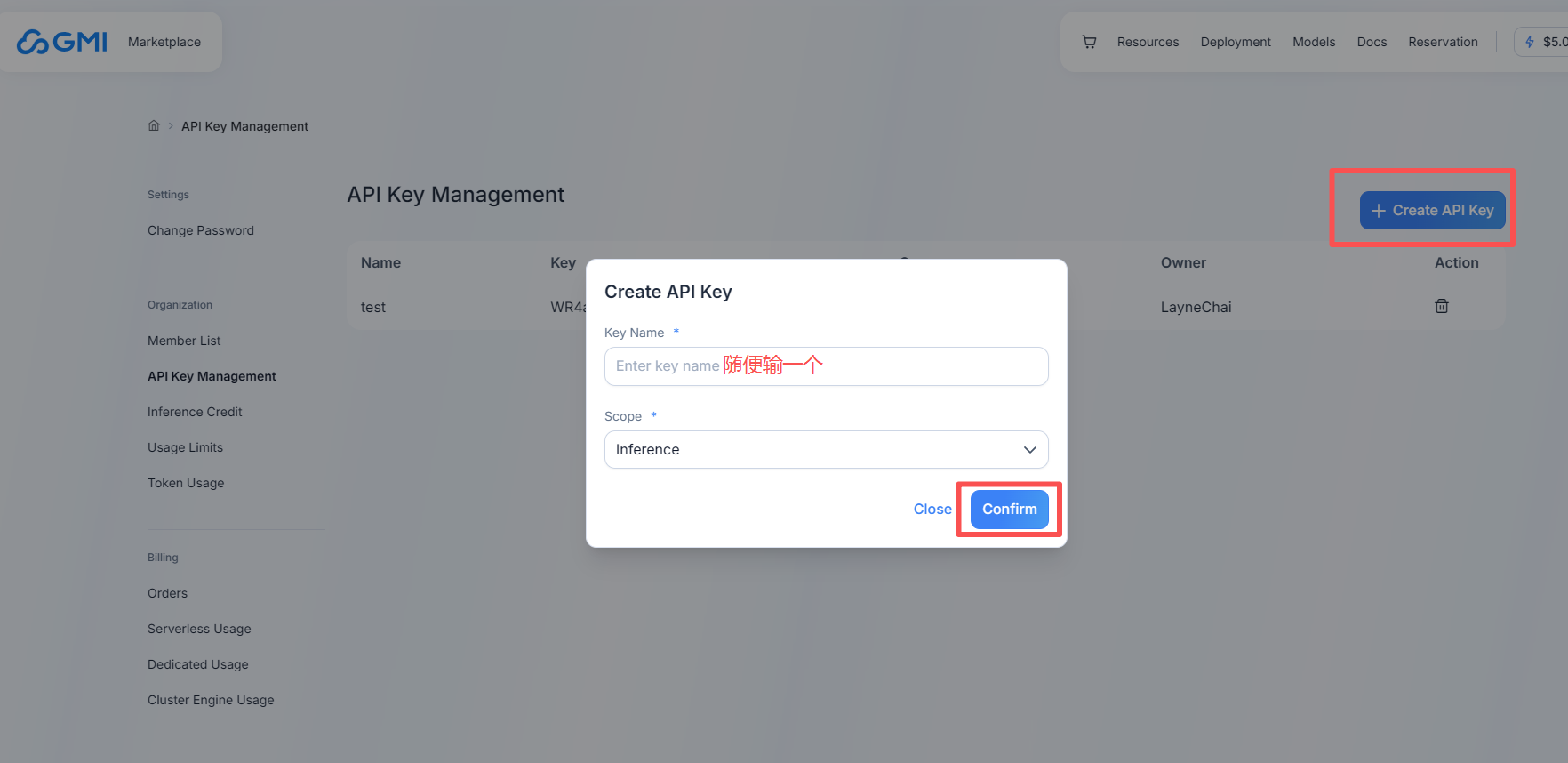
2、打开首页MaaS页面,有关于模型介绍和示例代码,
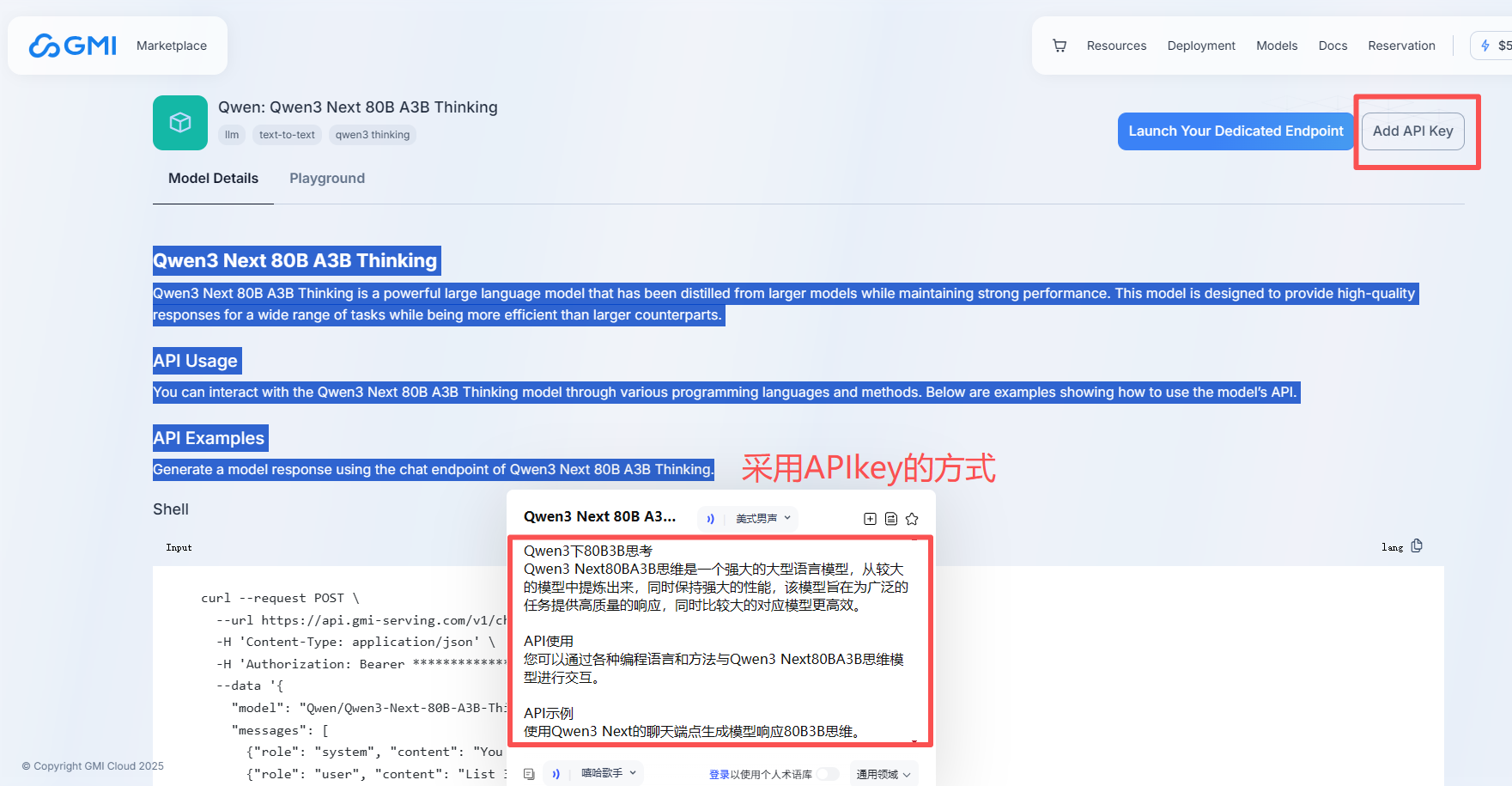
3、API引用GMI Cloud千问大模型【Python代码】
import requests
import json
url = "https://api.gmi-serving.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
}
payload = {
"model": "Qwen/Qwen3-Next-80B-A3B-Thinking",
"messages": [
{"role": "system", "content": "你是一个AI助手"},
{"role": "user", "content": "帮我列出中国云南省值得游玩的城市和景点"}
],
"temperature": 0,
"max_tokens": 500
}
response = requests.post(url, headers=headers, json=payload)
print(json.dumps(response.json(), indent=2, ensure_ascii=False))
响应情况:根据用户提出的需求响应相应的内容,特别低代码嵌入到公司的应用中
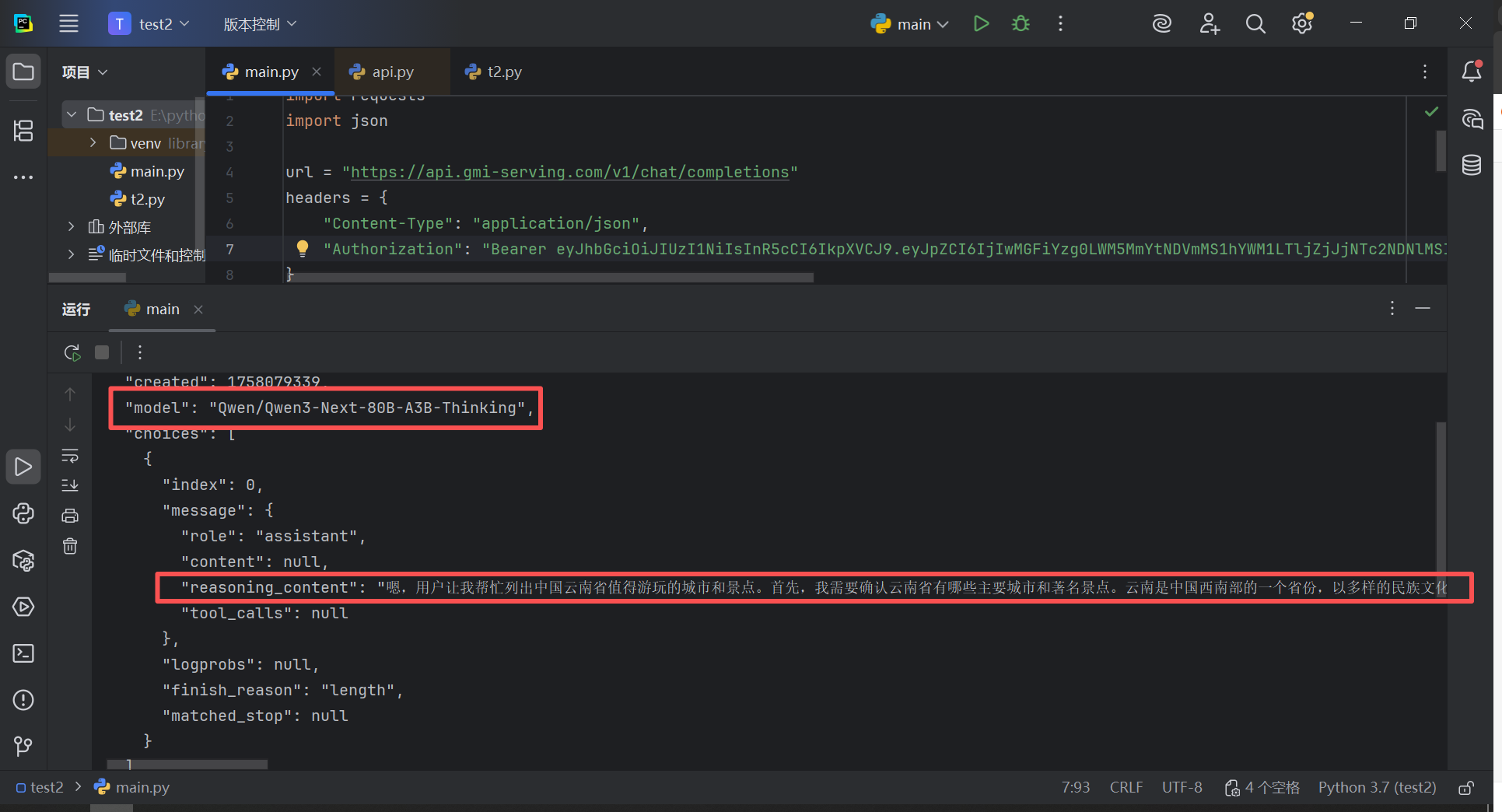
如果你们公司的需求比较高,使用人数比较多,并且并发量比较大的话,GMI Cloud相比于其他官方平台更具优势的一点就是提供单独租用H200这种大型GPU服务器,部署专用的算力服务器,来满足高并发的需求,接下来探索一下GMI Cloud专用算力服务器部署方案。
🎈进阶篇:业务爆发后我的专用部署选择
专用部署带来的惊喜变化
专用端点是可定制的用户配置资源,旨在为AI模型提供服务,并完全控制基础设施和配置。此功能非常适合需要更多控制其AI解决方案的用户。主要优势包括:
- 完全定制:部署您自己的模型并配置设置以满足特定的应用程序需求。
- 增强的性能:优化资源以获得针对您的用例量身定制的更好性能。
- 隔离和安全性:受益于隔离工作负载的专用环境,增强安全性和合规性。
专用服务器部署全记录
- 点击大模型左上角的 Launch Your Dedicated Endpoint
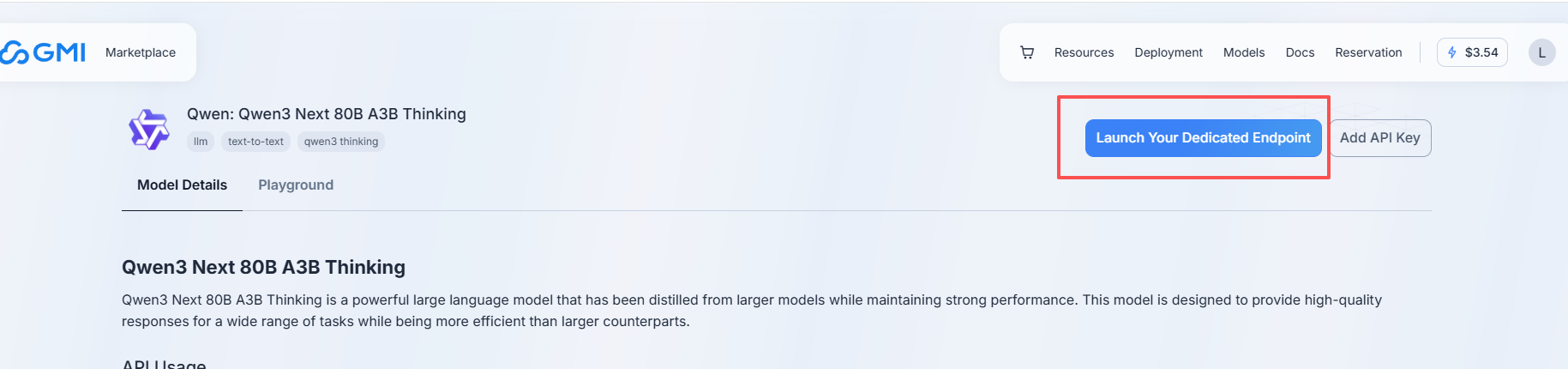
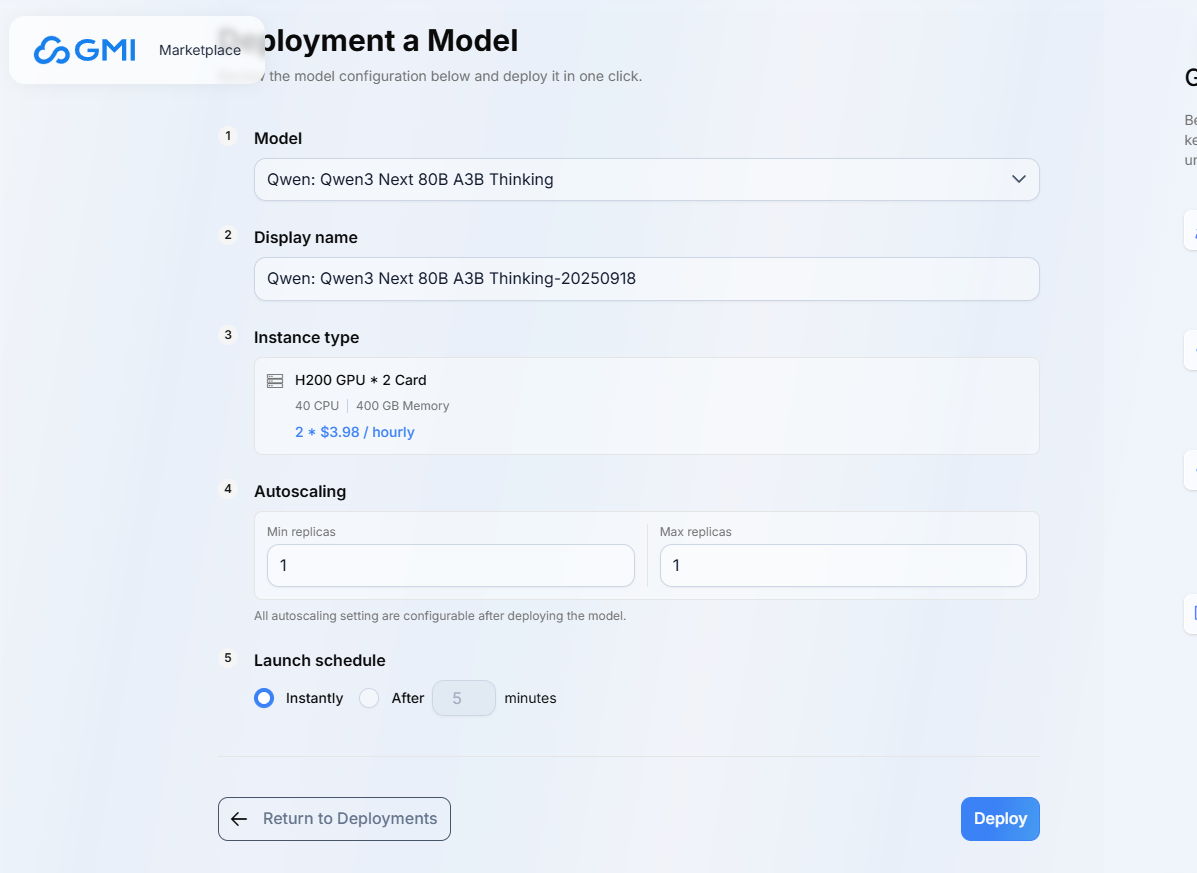
- 设置部署参数
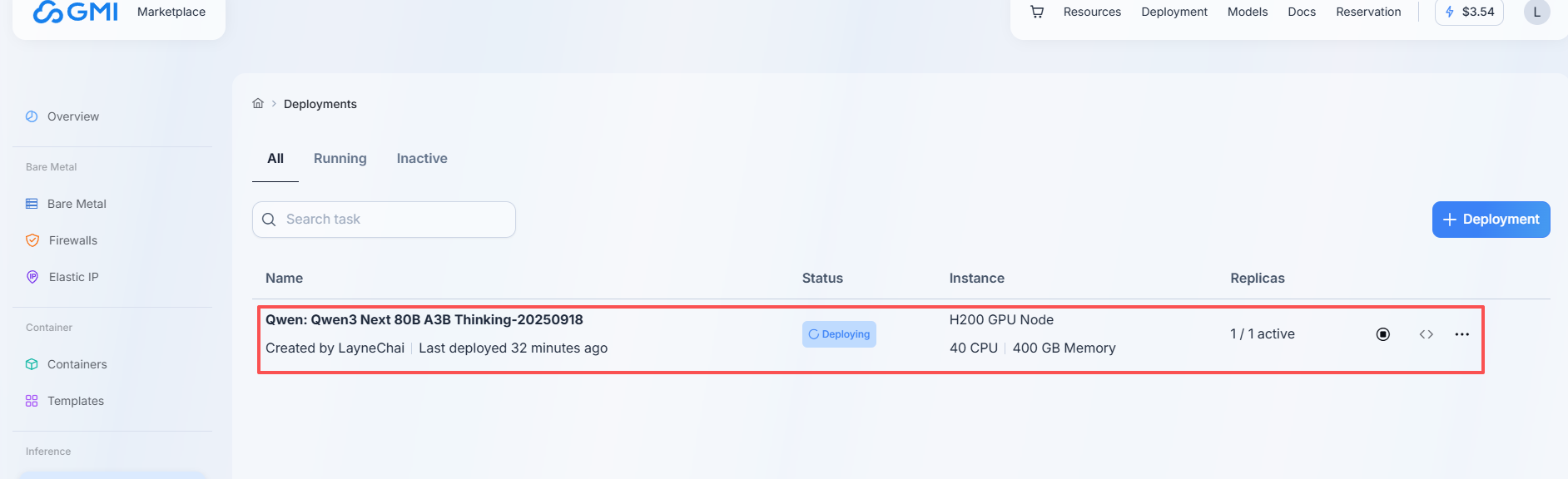
- 查看部署状态
- 点击endpoint URL即可获取调用API URL以及示例
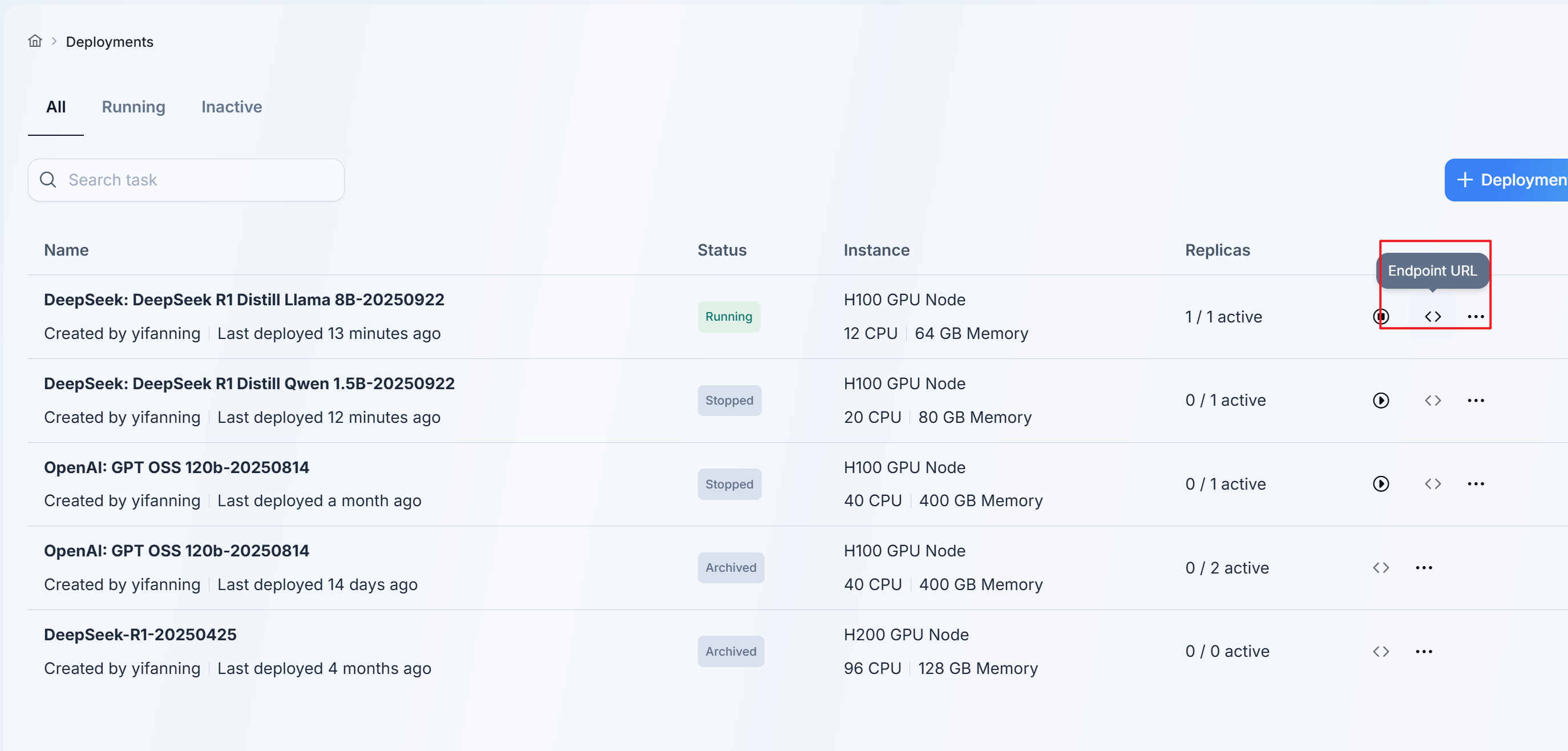
- 根据示例代码替换API Key后调用即可
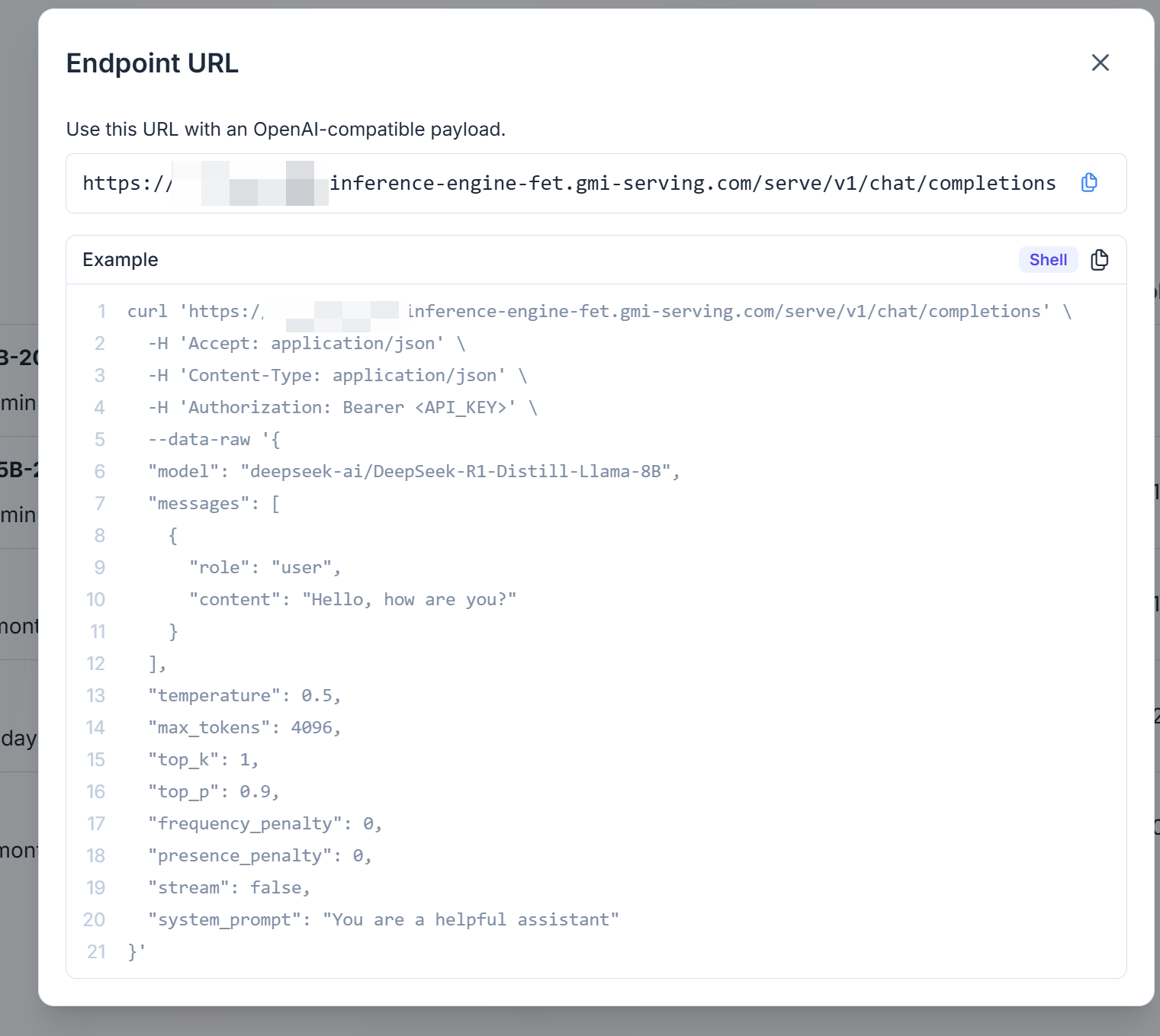
🎈惊喜彩弹:顺手玩了玩AI视频生成
除了公司业务需要集成的对话大模型,GMI Cloud还提供了其他的如在线AI视频生成和API调用生成的大模型,浅浅使用了一下,确实有点意思,生成的速度杠杠的,来看下怎么玩
1、打开首页,点击下边的视频生成板块的Try it Out
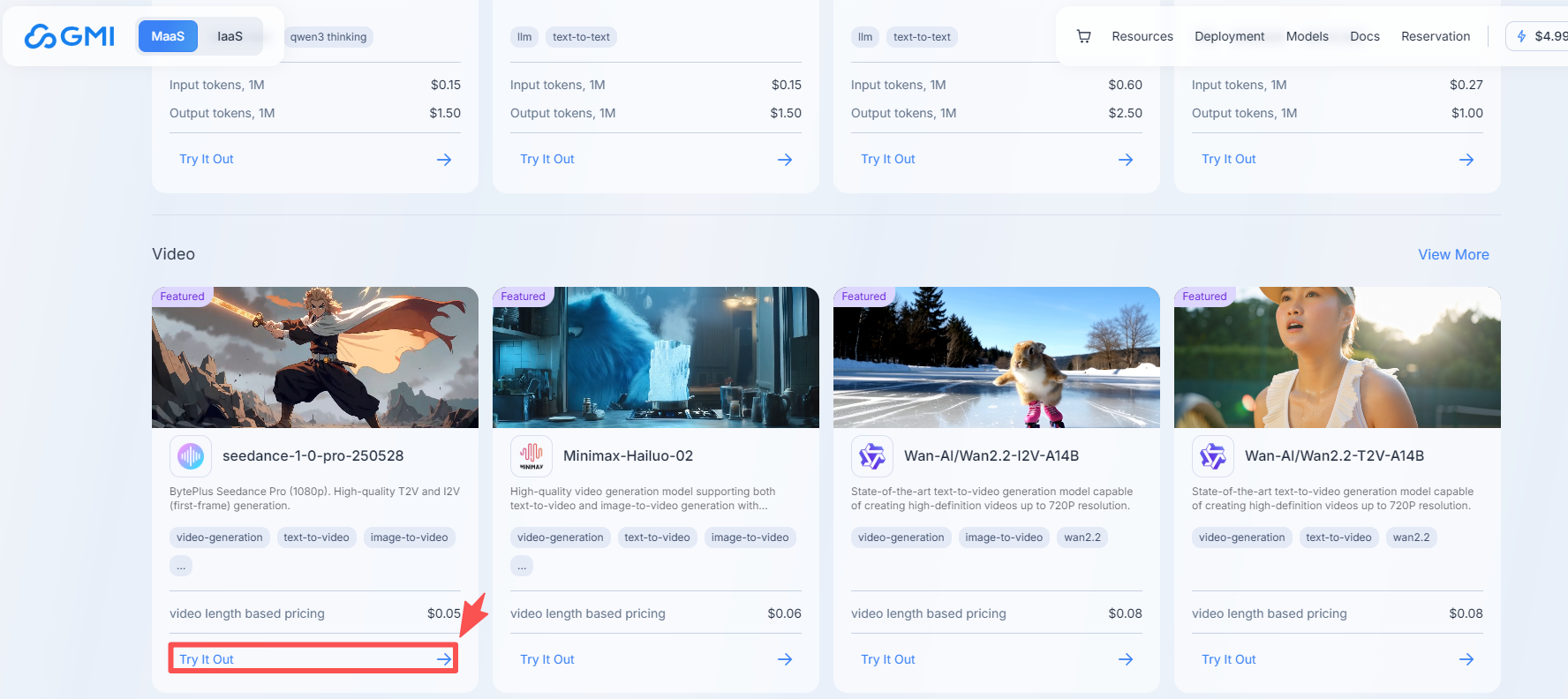
2、在线调用大模型生成视频(左边输入参数,点击生成,生成一段视频)
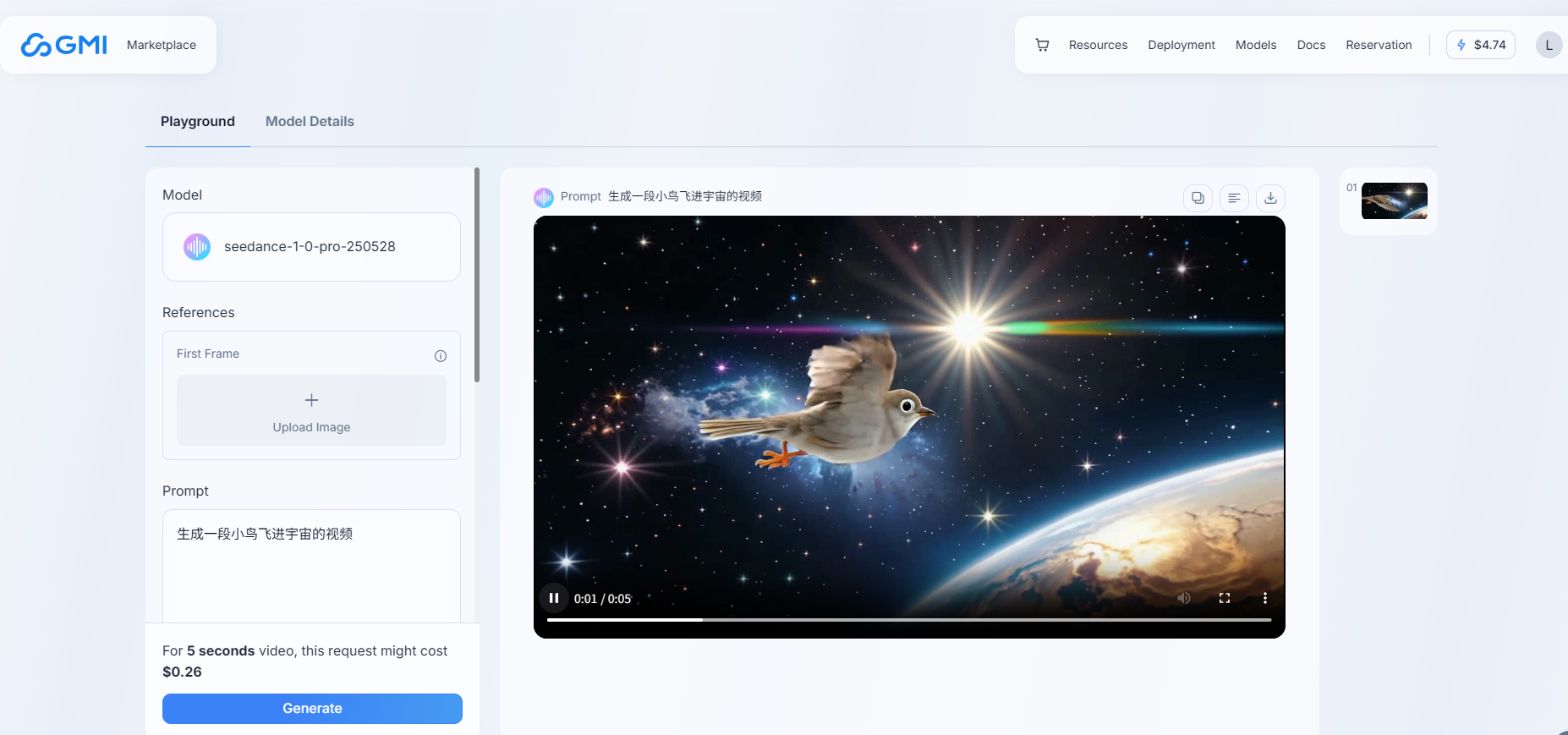
3、使用API调用视频大模型生成视频,可以点击Model Details,里边有相关的操作方法
举个Demo例子,使用命令行发送视频生成请求
curl -X POST "https://console.gmicloud.ai/api/v1/ie/requestqueue/apikey/requests" \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "seedance-1-0-pro-250528",
"payload": {
"prompt": "The head gradually rises, revealing the climber`s back.",
"first_frame": "https://storage.googleapis.com/gmi-video-assests-prod/public-assets/person-walking-winter-snow-boots-1193959625-770x533-1_jpg.jpeg",
"duration": 8,
"resolution": "720p",
"ratio": "16:9",
"camerafixed": false,
"seed": 42,
"watermark": false
}
}'
生成视频请求之后,检查视频生成状态【是否生成完成】
curl -X GET "https://console.gmicloud.ai/api/v1/ie/requestqueue/apikey/requests/550e8400-e29b-41d4-a716-446655440000" \
-H "Authorization: Bearer YOUR_API_KEY"
🍚🍚值得推荐的几个理由
通过一段时间的使用,GMI Cloud云平台的在公司应用的集成平稳运行,之所以选用GMI Cloud平台集成到公司的应用中,主要考虑到以下GMI Cloud产品的优势:
- 技术优势:作为NVIDIA顶级合作伙伴,优先获取最新GPU资源,确保硬件领先性。
- 稳定性:通过自主研发的集群管理系统和与数据中心的紧密协作,承诺99%的服务等级协议(SLA),减少AI训练和推理中的非预期中断。
- 成本效益:典型场景评估显示,使用GMI Cloud方案可使海外IT成本降低40%以上,回本周期缩短至行业平均水平的1/3。
- 全球化布局:数据中心覆盖全球多个国家和地区,为出海企业提供本地化算力支持。
后续公司采用GMI Cloud平台的H200进行了专用部署,速度嘎嘎快,如果在成本承受范围内,还得是租用自己专用H200算力比较充足。
体验GMI Cloud的强大功能:可访问GMI Cloud其官方网站https://docs.gmicloud.ai/了解更多信息,或尝试其创新的"AI应用构建成本计算器"来规划你的下一个AI项目。
摊牌了,免费领取H200跑大模型


















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











