







1)jdk安装略。。。
2)scala
https://www.scala-lang.org/download/all.html
下载zip解压,配置环境变量
3)spark
http://archive.apache.org/dist/spark/
下载解压
cmd中输入spark-shell
报错 Failed to locate the winutils binary in the hadoop binary path
需要安装hadoop
4)windows下hadoop安装
软件http://archive.apache.org/dist/hadoop/
下载解压即可
需要一些操作
1) https://github.com/steveloughran/winutils
下载winutils。这个是别人编译好的hadoop的windows版本二进制文件,不需要我们自己进行编译。下载!覆盖!即可。
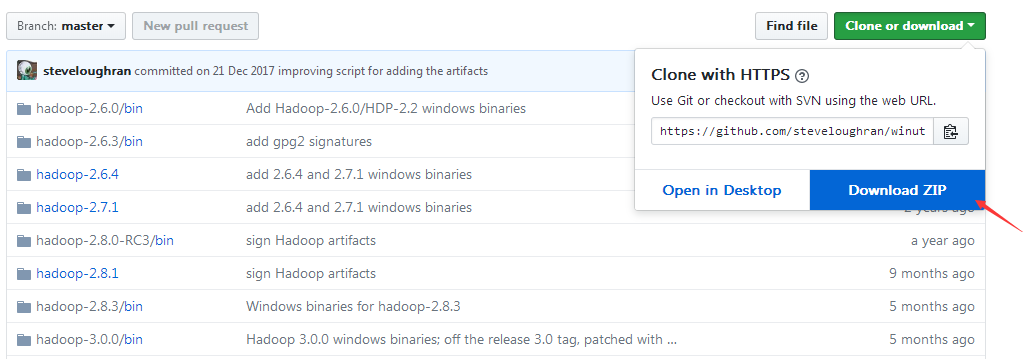
复制hadoop.dll文件到指定目录
将根目录下的bin文件夹中的hadoop.dll文件复制到C:\Windows\System32文件夹下
2)修改配置文件etc\hadoop\hadoop-env.cmd
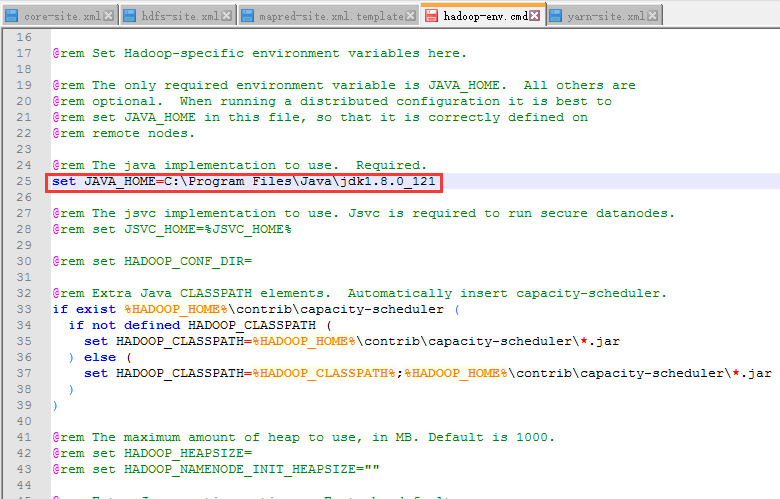
如果路径中含有Program Files需要用PROGRA~1替换

3)打开根目录下的etc/hadoop/hdfs-site.xml文件
修改dfs.namenode.name.dir和dfs.datanode.name.dir两个属性的值,改为刚刚创建的两个文件夹datanode和namenode的绝对路径(注意不能直接把在Windows下的路径复制粘贴,路径URL用的是斜杠不是反斜杠,而且前面还要加一个斜杠)然后保存退出
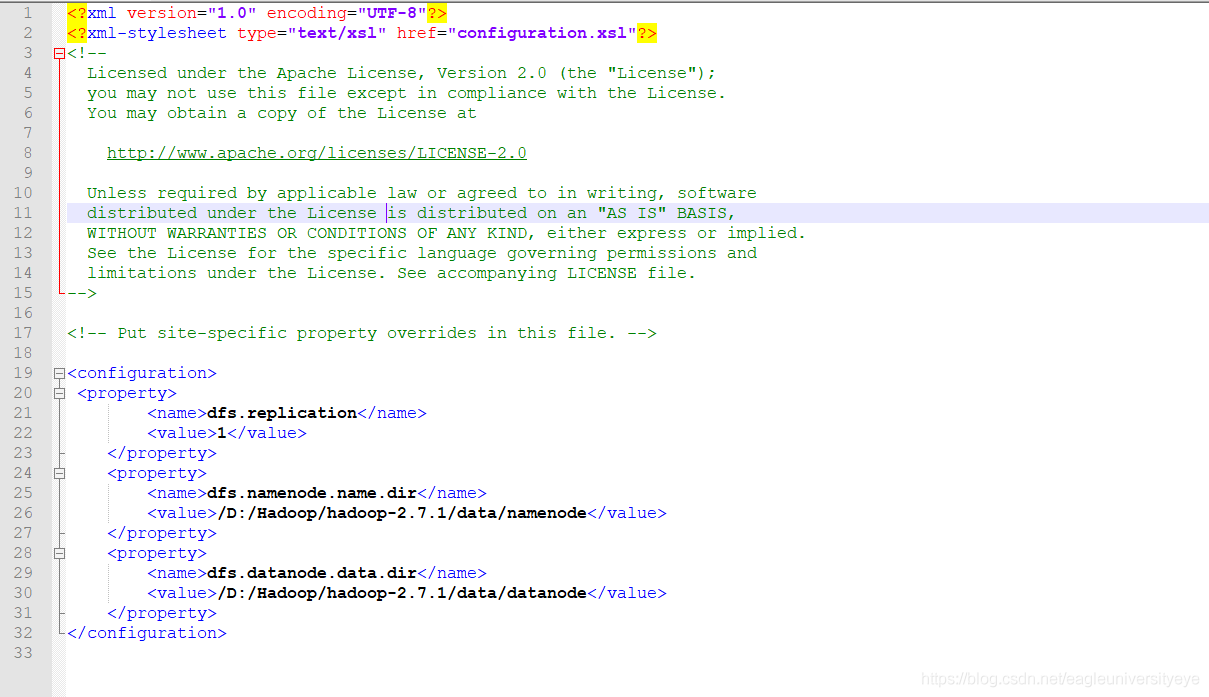
执行hdfs namenode -format
sbin目录,启动start-all.cmd
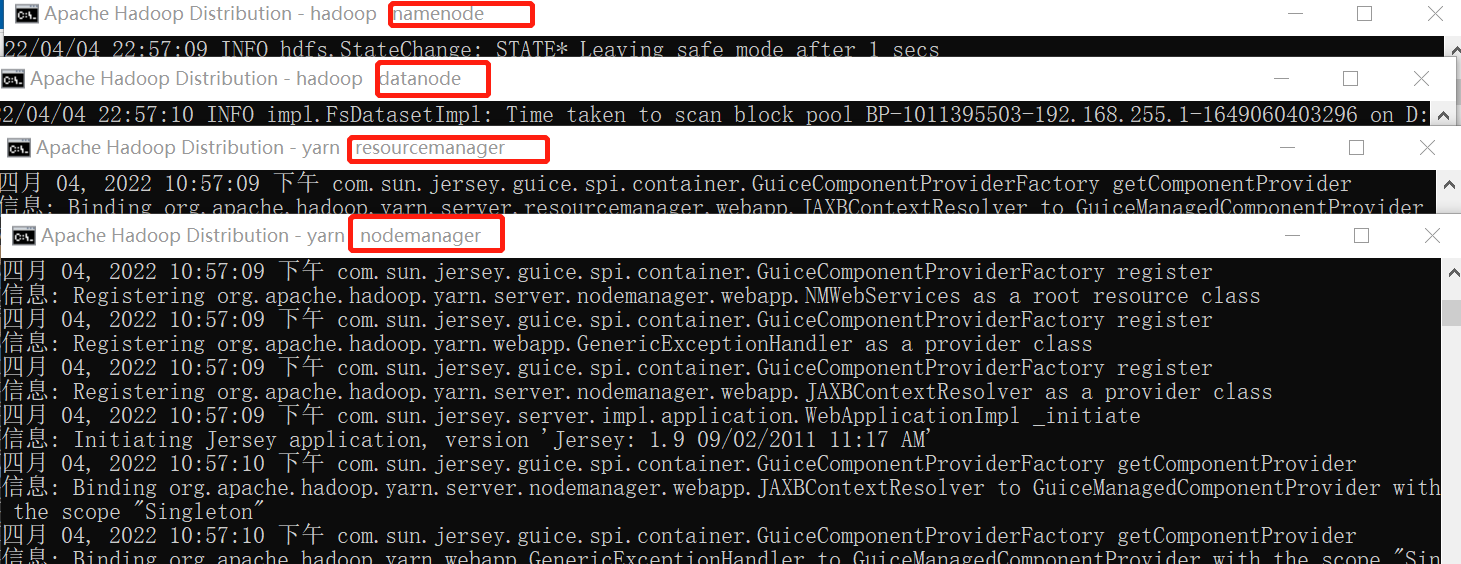
namenode、datanode、resourcemanager、nodemanager
https://gitcode.net/mirrors/sardetushar/hadooponwindows?utm_source=csdn_github_accelerator
此时执行cmd中输入spark-shell
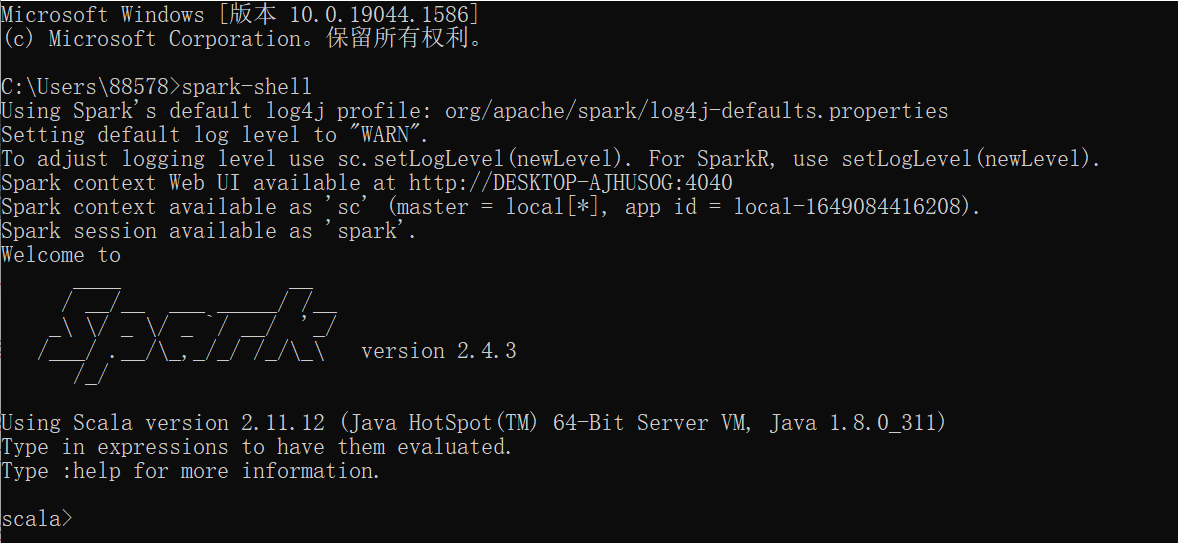
IDEA写一个Scala的demo并使用Spark-submit运行
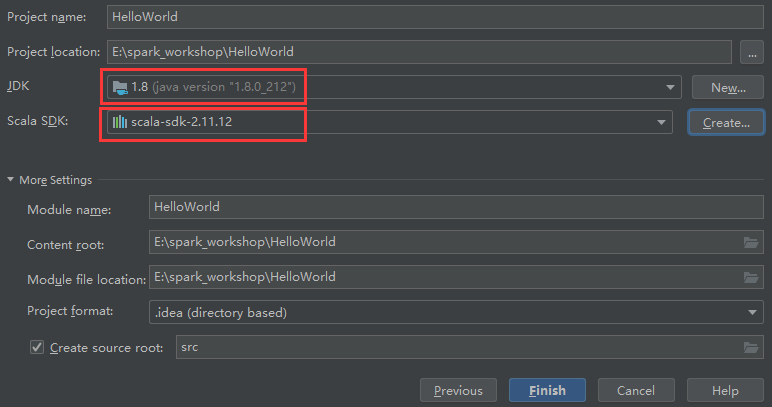
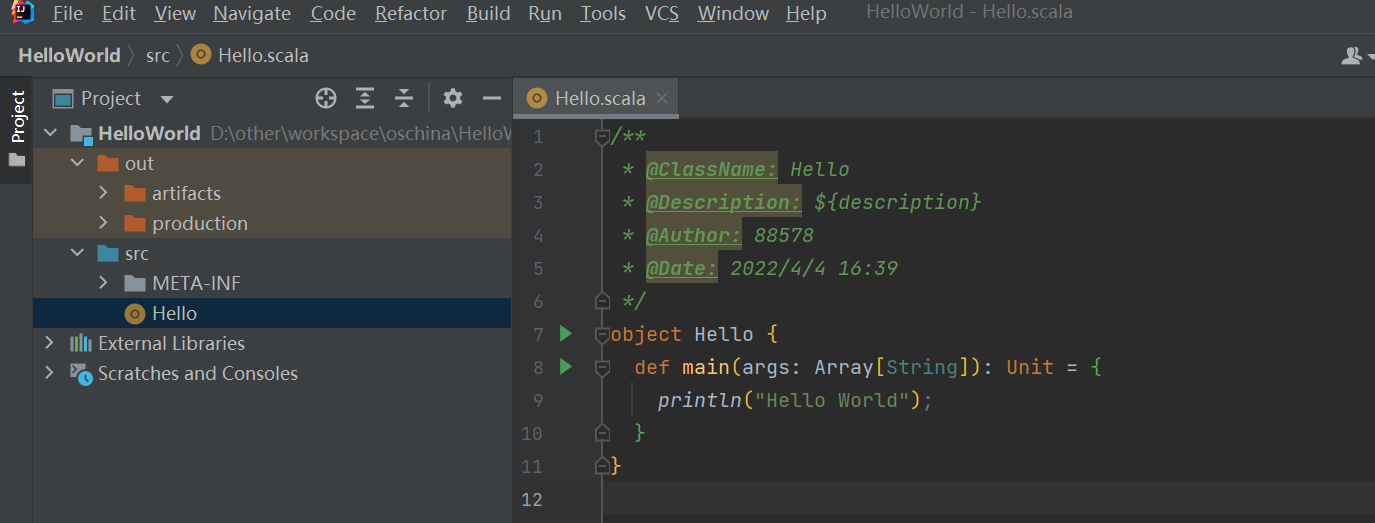
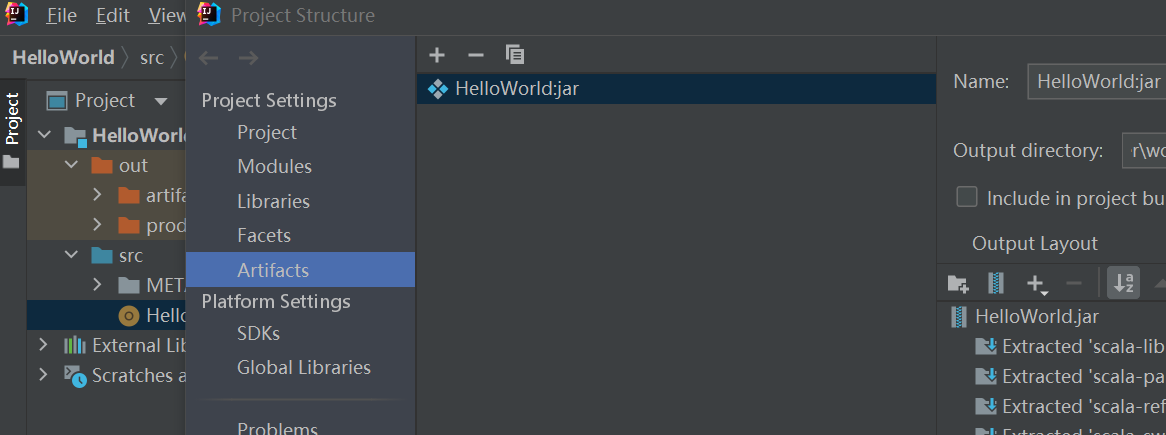
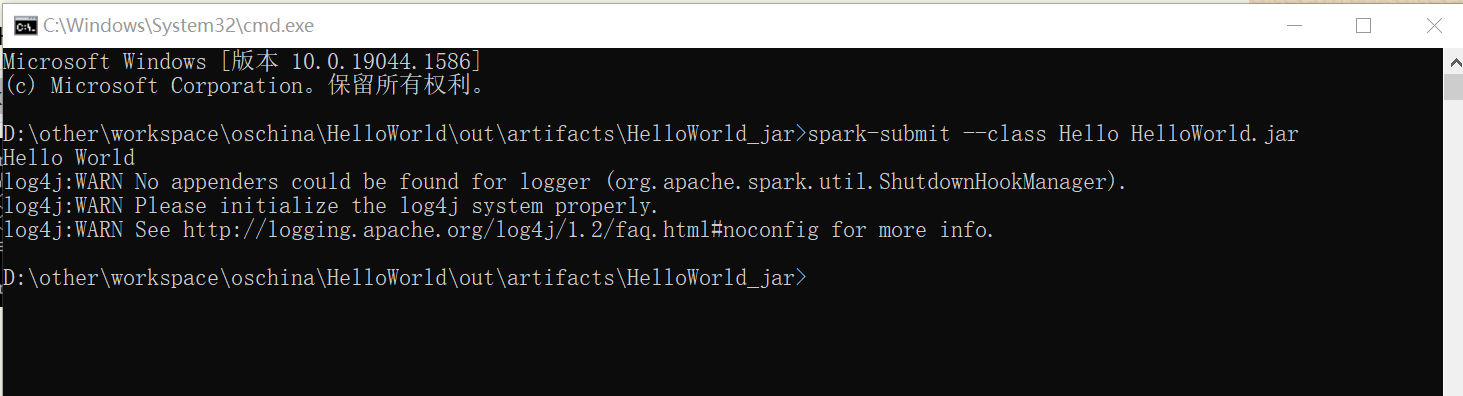
spark-submit --class Hello HelloWorld.jar















 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









