






urllib与requests
一、urllib的学习
学习目标
了解urllib的基本使用
1、urllib介绍
除了requests模块可以发送请求之外, urllib模块也可以实现请求的发送,只是操作方法略有不同!
urllib在python中分为urllib和urllib2,在python3中为urllib
下面以python3的urllib为例进行讲解
2、urllib的基本方法介绍
2.1 urllib.Request
构造简单请求
import urllib
#构造请求
request = urllib.request.Request("http://www.baidu.com")
#发送请求获取响应
response = urllib.request.urlopen(request)
传入headers参数
import urllib
#构造headers
headers = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)"}
#构造请求
request = urllib.request.Request(url, headers = headers)
#发送请求
response = urllib.request.urlopen(request)
传入data参数 实现发送post请求(示例)
import urllib.request
import urllib.parse
import json
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.0 Safari/605.1.15',
}
data = {
'cname': '',
'pid': '',
'keyword': '北京',
'pageIndex': 1,
'pageSize': 10,
}
# 使用post方式
# 需要
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url, data=data, headers=headers)
res = urllib.request.urlopen(req)
print(res.getcode())
print(res.geturl())
data = json.loads(res.read().decode('utf-8'))
# print(data)
for i in data['Table1']:
print(i)
2.2 response.read()
获取响应的html字符串,bytes类型
#发送请求
response = urllib.request.urlopen("http://www.baidu.com")
#获取响应
response.read()
3、urllib请求百度首页的完整例子
import urllib
import json
url = 'http://www.baidu.com'
#构造headers
headers = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)"}
#构造请求
request = urllib.request.Request(url, headers = headers)
#发送请求
response = urllib.request.urlopen(request)
#获取html字符串
html_str = response.read().decode('utf-8')
print(html_str)
4、小结
-
urllib.request中实现了构造请求和发送请求的方法
-
urllib.request.Request(url,headers,data)能够构造请求
-
urllib.request.urlopen能够接受request请求或者url地址发送请求,获取响应
-
response.read()能够实现获取响应中的bytes字符串
requests模块的入门使用
一、requests模块的入门使用
学习目标:
-
了解 requests模块的介绍
-
掌握 requests的基本使用
-
掌握 response常见的属性
-
掌握 requests.text和content的区别
-
掌握 解决网页的解码问题
-
掌握 requests模块发送带headers的请求
-
掌握 requests模块发送带参数的get请求
1、为什么要重点学习requests模块,而不是urllib
-
企业中用的最多的就是requests
-
requests的底层实现就是urllib
-
requests在python2 和python3中通用,方法完全一样
-
requests简单易用
2、requests的作用与安装
作用:发送网络请求,返回响应数据
安装:pip install requests
3、requests模块发送简单的get请求、获取响应
需求:通过requests向百度首页发送请求,获取百度首页的数据
import requests
# 目标url
url = 'https://www.baidu.com'
# 向目标url发送get请求
response = requests.get(url)
# 打印响应内容
print(response.text)
response的常用属性:
-
response.text响应体 str类型 -
response.encoding从HTTP header中猜测的响应内容的编码方式 -
respones.content响应体 bytes类型 -
response.status_code响应状态码 -
response.request.headers响应对应的请求头 -
response.headers响应头 -
response.request.cookies响应对应请求的cookie -
response.cookies响应的cookie(经过了set-cookie动作) -
response.url获取访问的url -
response.json()获取json数据 得到内容为字典 (如果接口响应体的格式是json格式时) -
response.ok如果status_code小于200,response.ok返回True。
如果status_code大于200,response.ok返回False。
思考:text是response的属性还是方法呢?
-
一般来说名词,往往都是对象的属性,对应的动词是对象的方法
3.1 response.text 和response.content的区别
-
response.text-
类型:str
-
解码类型: requests模块自动根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码
-
如何修改编码方式:
response.encoding="gbk/UTF-8"
-
-
response.content-
类型:bytes
-
解码类型: 没有指定
-
如何修改编码方式:
response.content.deocde("utf8")
-
获取网页源码的通用方式:
-
response.content.decode() -
response.content.decode("UTF-8") -
response.text
以上三种方法从前往后尝试,能够100%的解决所有网页解码的问题
所以:更推荐使用response.content.deocde()的方式获取响应的html页面
3.2 练习:把网络上的图片保存到本地
我们来把
www.baidu.com的图片保存到本地
思考:
-
以什么方式打开文件
-
保存什么格式的内容
分析:
-
利用requests模块发送请求获取响应
-
以2进制写入的方式打开文件,并将response响应的二进制内容写入
import requests
# 图片的url
url = 'https://www.baidu.com/img/bd_logo1.png'
# 响应本身就是一个图片,并且是二进制类型
response = requests.get(url)
# print(response.content)
# 以二进制+写入的方式打开文件
with open('baidu.png', 'wb') as f:
# 写入response.content bytes二进制类型
f.write(response.content)
4、发送带header的请求
我们先写一个获取百度首页的代码
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
print(response.content)
# 打印响应对应请求的请求头信息
print(response.request.headers)4.1 思考
对比浏览器上百度首页的网页源码和代码中的百度首页的源码,有什么不同?
代码中的百度首页的源码非常少,为什么?
4.2 为什么请求需要带上header?
模拟浏览器,欺骗服务器,获取和浏览器一致的内容
4.3 header的形式:字典
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
4.4 用法
requests.get(url, headers=headers)
4.5 完整的代码
import requests
url = 'https://www.baidu.com'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 在请求头中带上User-Agent,模拟浏览器发送请求
response = requests.get(url, headers=headers)# print(response.content)
# 打印请求头信息
print(response.request.headers)5、发送带参数的请求
我们在使用百度搜索的时候经常发现url地址中会有一个
?,那么该问号后边的就是请求参数,又叫做查询字符串5.1 什么叫做请求参数:
例1: gzip和deflate的几点区别 - 服务器技术_卡卡网
例2:百度安全验证
例1中没有请求参数!例2中?后边的就是请求参数
5.2 请求参数的形式:字典
kw = {'wd':'长城'}
5.3 请求参数的用法
requests.get(url,params=kw)
5.4 关于参数的注意点
在url地址中, 很多参数是没有用的,比如百度搜索的url地址,其中参数只有一个字段有用,其他的都可以删除 如何确定那些请求参数有用或者没用:挨个尝试! 对应的,在后续的爬虫中,越到很多参数的url地址,都可以尝试删除参数
5.5 两种方式:发送带参数的请求
对
https://www.baidu.com/s?wd=python发起请求可以使用requests.get(url, params=kw)的方式# 方式一:利用params参数发送带参数的请求
import requestsheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 这是目标url
# url = 'https://www.baidu.com/s?wd=python'# 最后有没有问号结果都一样
url = 'https://www.baidu.com/s?'# 请求参数是一个字典 即wd=python
kw = {'wd': 'python'}# 带上请求参数发起请求,获取响应
response = requests.get(url, headers=headers, params=kw)# 当有多个请求参数时,requests接收的params参数为多个键值对的字典,比如 '?wd=python&a=c'-->{'wd': 'python', 'a': 'c'}
print(response.content)
也可以直接对
https://www.baidu.com/s?wd=python完整的url直接发送请求,不使用params参数# 方式二:直接发送带参数的url的请求
import requestsheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
url = 'https://www.baidu.com/s?wd=python'
# kw = {'wd': 'python'}
# url中包含了请求参数,所以此时无需params
response = requests.get(url, headers=headers)二、requests模块的深入使用
学习目标:
能够应用requests发送post请求的方法
能够应用requests模块使用代理的方法
了解代理ip的分类
1、使用requests发送POST请求
思考:哪些地方我们会用到POST请求?
登录注册( POST 比 GET 更安全)
需要传输大文本内容的时候( POST 请求对数据长度没有要求)
所以同样的,我们的爬虫也需要在这两个地方回去模拟浏览器发送post请求
1.1 requests发送post请求语法:
用法:
response = requests.post("http://www.baidu.com/", data = data, headers=headers)data 的形式:字典
1.2 POST请求练习
下面面我们通过金山翻译的例子看看post请求如何使用:
地址:在线翻译_翻译在线__英语翻译_英文翻译_日语翻译__fanyi_爱词霸
1.3 小结
在模拟登陆等场景,经常需要发送post请求,直接使用
requests.post(url,data)即可2、使用代理
2.1 为什么要使用代理
让服务器以为不是同一个客户端在请求
防止我们的真实地址被泄露,防止被追究
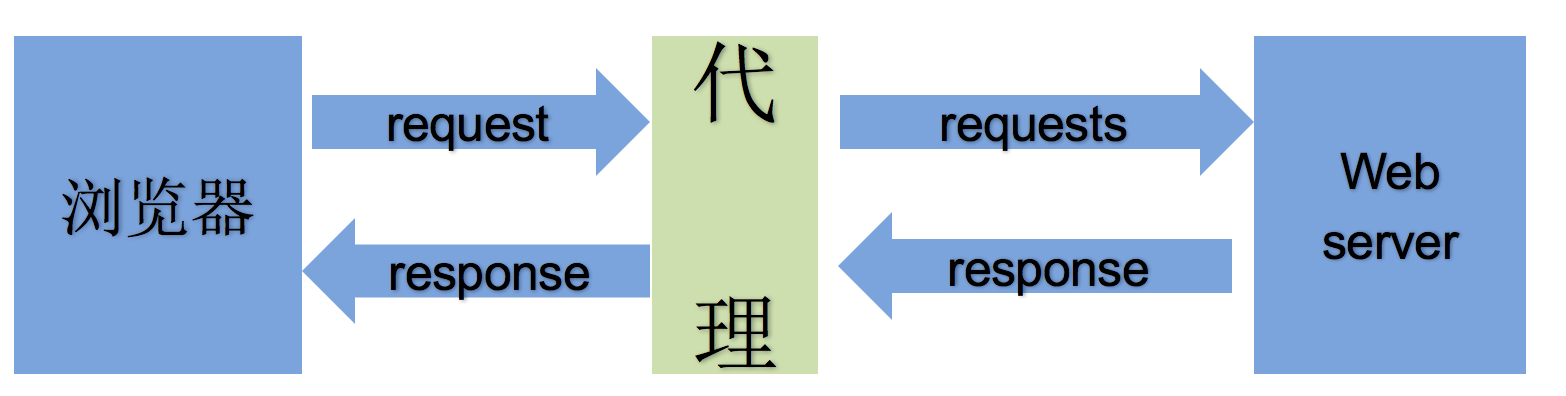
2.2 理解使用代理的过程
2.3 理解正向代理和反向代理的区别
通过上图可以看出:
正向代理:对于浏览器知道服务器的真实地址,例如VPN
反向代理:浏览器不知道服务器的真实地址,例如nginx
详细讲解:
正向代理是客户端与正向代理客户端在同一局域网,客户端发出请求,正向代理 替代客户端向服务器发出请求。服务器不知道谁是真正的客户端,正向代理隐藏了真实的请求客户端。
反向代理:服务器与反向代理在同一个局域网,客服端发出请求,反向代理接收请求 ,反向代理服务器会把我们的请求分转发到真实提供服务的各台服务器Nginx就是性能非常好的反向代理服务器,用来做负载均衡
2.4 代理的使用
用法:
requests.get("http://www.baidu.com", proxies = proxies)proxies的形式:字典
例如:
proxies = { "http": "http://12.34.56.79:9527", "https": "https://12.34.56.79:9527", }2.5 代理IP的分类
根据代理ip的匿名程度,代理IP可以分为下面四类:
透明代理(Transparent Proxy):透明代理的意思是客户端根本不需要知道有代理服务器的存在,但是它传送的仍然是真实的IP。使用透明代理时,对方服务器是可以知道你使用了代理的,并且他们也知道你的真实IP。你要想隐藏的话,不要用这个。透明代理为什么无法隐藏身份呢?因为他们将你的真实IP发送给了对方服务器,所以无法达到保护真实信息。
匿名代理(Anonymous Proxy):匿名代理隐藏了您的真实IP,但是向访问对象可以检测是使用代理服务器访问他们的。会改变我们的请求信息,服务器端有可能会认为我们使用了代理。不过使用此种代理时,虽然被访问的网站不能知道你的ip地址,但仍然可以知道你在使用代理,当然某些能够侦测ip的网页也是可以查到你的ip。(使用代理IP是怎么被别人发现并被查出真实IP的? - 百度文库)
高匿代理(Elite proxy或High Anonymity Proxy):高匿名代理不改变客户机的请求,这样在服务器看来就像有个真正的客户浏览器在访问它,这时客户的真实IP是隐藏的,完全用代理服务器的信息替代了您的所有信息,就象您就是完全使用那台代理服务器直接访问对象,同时服务器端不会认为我们使用了代理。IPDIEA覆盖全球240+国家地区ip高匿名代理不必担心被追踪。
在使用的使用,毫无疑问使用高匿代理效果最好
从请求使用的协议可以分为:
http代理
https代理
socket代理等
不同分类的代理,在使用的时候需要根据抓取网站的协议来选择
2.6 代理IP使用的注意点
反反爬
使用代理ip是非常必要的一种
反反爬的方式但是即使使用了代理ip,对方服务器任然会有很多的方式来检测我们是否是一个爬虫,比如:
一段时间内,检测IP访问的频率,访问太多频繁会屏蔽
检查Cookie,User-Agent,Referer等header参数,若没有则屏蔽
服务方购买所有代理提供商,加入到反爬虫数据库里,若检测是代理则屏蔽
所以更好的方式在使用代理ip的时候使用随机的方式进行选择使用,不要每次都用一个代理ip
代理ip池的更新
购买的代理ip很多时候大部分(超过60%)可能都没办法使用,这个时候就需要通过程序去检测哪些可用,把不能用的删除掉。
代理服务器平台的使用:
当然还有很多免费的,但是大多都不可用需要自己尝试
3、配置
浏览器配置代理
右边三点==> 设置==> 高级==> 代理==> 局域网设置==> 为LAN使用代理==> 输入ip和端口号即可
参考网址:如何设置浏览器网络代理-百度经验
代码配置
urllib
handler = urllib.request.ProxyHandler({'http': '114.215.95.188:3128'}) opener = urllib.request.build_opener(handler) # 后续都使用opener.open方法去发送请求即可requests
# 用到的库 import requests # 写入获取到的ip地址到proxy # 一个ip地址 proxy = { 'https':'221.178.232.130:8080' } """ # 多个ip地址 proxy = [ {'https':'221.178.232.130:8080'}, {'https':'221.178.232.130:8080'} ] import random proxy = random.choice(proxy) """ # 用百度检测ip代理是否成功 url = 'https://www.baidu.com/s?' # 请求网页传的参数 params={ 'wd':'ip地址' } # 请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36' } # 发送get请求 response = requests.get(url=url,headers=headers,params=params,proxies=proxy) # 获取返回页面保存到本地,便于查看 with open('ip.html','w',encoding='utf-8') as f: f.write(response.text)
















 1286
1286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}