









本文主要介绍智能体相关基础知识,主流的智能体开源项目,重点介绍Lagent智能体和AgentLego框架。
一. 为什么要有智能体
目前的大预言模型有一些局限性,包括有时候会生成虚假信息,也就是我们说的“大模型胡言乱语”,还有就是训练完成的大模型,其信息取决于训练的数据,无法实时更新。但智能体可以在大模型的基础上调用各种工具,实现更加丰富的功能,例如调用搜索引擎,获取最新信息等。

二. 什么是智能体
在1995年 Hayes-Roth提出的智能体概念:
1. 可以感知环境中的动态条件
2. 能采取动作影响环境
3. 能运用推理能力理解信息,解决问题,产生推断,决定动作

三. 智能体组成
智能体一般由三部分组成:大脑,感知和动作。
大脑一般由一个能力强悍的大模型,如ChatGPT,参数千亿的各类模型。
感知一般由语言文字,图片,视频,音频,传感器等作为输入。
动作是指智能体支持的一些动作,例如 图片检测,调用搜索引擎进行信息搜索等。

四. 常见智能体
1. AutoGPT
用户输入问题后,在任务列表中,选择一个任务给大模型执行,根据返回的结果,选择任务执行,这样循环,直达完成用户的问题。

2. ReWoo
用户输入后,通过大脑,也就是我们选择的大模型,进行任务拆分,再将拆分的任务分配给各个动作执行器,最终返回给大脑,回复答案给用户。

3. ReAct
与ReWoo类似。

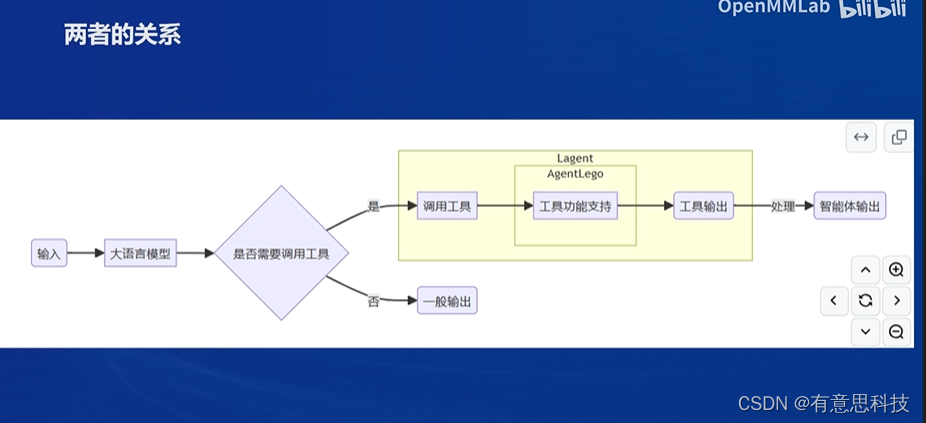
五. Lagent 和 AgentLego
1. Lagent
一个轻量级开源智能体框架,旨在让用户可以高效的构建基于大预言模型的智能体。支持多种智能体范式,如AutoGPT,ReWoo,ReAct等。同时也支持多种工具如,谷歌搜索,Python解释器等。

2. AgentLego
一个多模态工具包,旨在像乐高积木,可以快速简便地拓展自定义工具,从而组装出自己地智能体。支持多个智能体框架,如Lagent, Langchain等。


















 1048
1048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











