



1. 稀疏索引和稠密索引
-
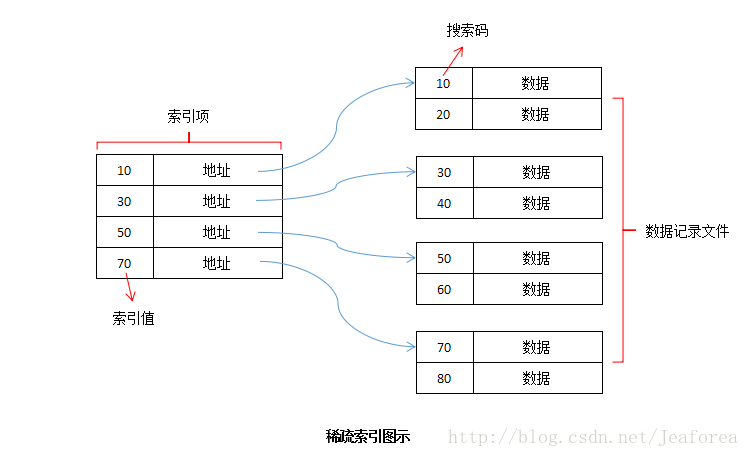
稀疏索引
在稀疏索引中,不会为每个搜索关键字创建索引记录。此处的索引记录包含搜索键和指向磁盘上数据的实际指针。要搜索记录,我们首先按索引记录进行操作,然后到达数据的实际位置。如果我们要寻找的数据不是我们通过遵循索引直接到达的位置,那么系统将开始顺序搜索,直到找到所需的数据为止。
-
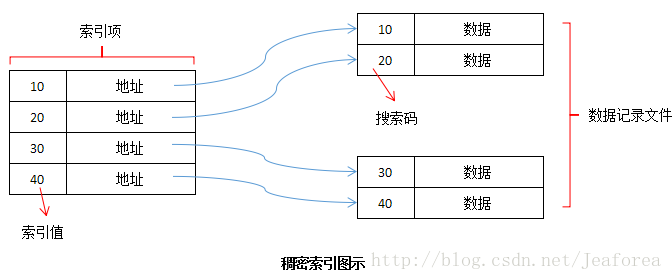
稠密索引
在密集索引中,数据库中的每个搜索键值都有一个索引记录。这样可以加快搜索速度,但需要更多空间来存储索引记录本身。索引记录包含搜索键值和指向磁盘上实际记录的指针。
-
稀疏矩阵与稠密矩阵的优缺点
- 稀疏矩阵占用的空间小,但是速度慢,精确率相对于稠密索引慢。
- 稠密索引相对来说占用的空间大,但是速度快。
2. 顺序索引
**搜索码:**用于在文件中查找记录的属性或属性集称为搜索码,可以将其简单的理解为主键。
| id | username |
|---|---|
| 1 | 神原拓也 |
| 2 | 源辉二 |
顺序索引就是按顺序存储搜索码的值
2.1 聚集索引
如果包含记录的文件按照某个搜索码按指定的顺序排序,也就是说除了搜索码,记录也是按序存储的,那么改搜索码对应的索引称为聚集索引,也叫做主索引。稀疏索引的适用范围是聚集索引。
2.2 非聚集索引
如果搜索码指定的顺序和记录的顺序不同则叫做非聚集索引,也叫做辅助索引
辅助索引必须是稠密索引
3. 散列索引
实现:散列索引
散列
有M个桶,每个桶是有相同容量的存储块(可以是内存页,也可以是磁盘块)
内存数据可采用散列确定存储页,主文件可采用散列确定存储块,索引亦可采用散列确定索引项的存储块
M个桶。一个桶可以是一个存储块,亦可是若干个连续的存储块。
散列函数 h(k),可以将键值k映射到 {0,1,…,M-1}中的某一个值
将具有键值k的记录Record(k)存储在对应h(k)编号的桶中
在键值几倍于桶的数目时,每个散列值都可能多于一个桶,形成一个主桶和多个溢出桶的列表,此时需要二次检索:先散列找到主桶号,再依据链表逐一找到每个溢出桶。
散列索引的好处,还可以进行集合运算,即对每个桶进行集合运算
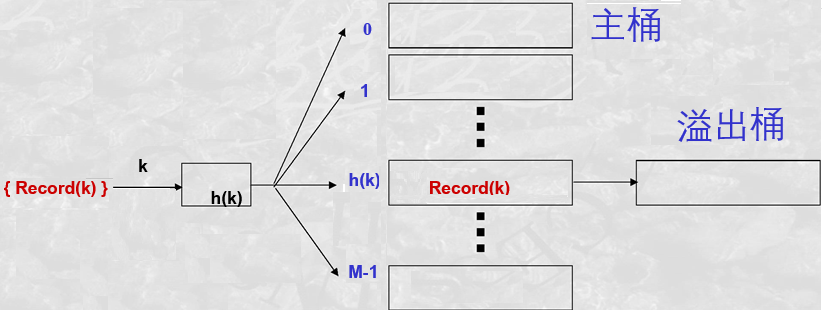
—————————
原文链接:https://blog.csdn.net/weixin_43934607/article/details/110210706
3.1 散列索引与顺序索引的区别
- 存储方式不同
- 应用场景不同
4. 非顺序索引——B+树索引文件
二叉搜索树、平衡树、红黑树、B-树、B+树


















 7670
7670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











