









文章目录
JDK源码阅读指导:
JDK源码很多,不知道从何读取,还好有前人指路,感谢!
https://blog.csdn.net/qq_21033663/article/details/79571506
ArrayList源码
参考资料:https://www.jianshu.com/p/f10edaec36fa
serialVersionUID的作用:
https://blog.csdn.net/java_mdzy/article/details/78354959

private static final long serialVersionUID = 8683452581122892189L;//序列化版本id
/**
* Default initial capacity.
* 默认初始容量为10----存储层
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* Shared empty array instance used for empty instances.
* 用于空实例的共享空数组实例--注意到staitc没?就是说创建多个空实例对象其实都指向的是
* 方法区同一个实例------
* 具体可以参见public ArrayList(int initialCapacity)有参构造方法
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* Shared empty array instance used for default sized empty instances.
* 共享空数组实例,用于默认大小的空实例。
* We distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
* 我们将其与EMPTY_ELEMENTDATA区分开来,以了解添加第一个元素时应该膨胀多少。
* 具体可以参见public ArrayList()无参构造方法
* Q:和上面EMPTY_ELEMENTDATA有啥区别,它们的修饰符和初值都一样啊,
* 有必要在方法区里定义两个实例吗???
* A:https://blog.csdn.net/u010412719/article/details/51108357
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* The size of the ArrayList (the number of elements it contains).
* 有效数据的大小-----抽象层
* @serial
*/
private int size;
/**
* The array buffer into which the elements of the ArrayList are stored.
* 这个ArrayList的元素被存储到这个数组缓冲区Object[] elementData中;
* The capacity of the ArrayList is the length of this array buffer.
* ArrayList的存储层容量就是这个数组缓冲区的长度
* Any empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
* 当添加第一个元素时,任何带有elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA的空ArrayList都将扩展为DEFAULT_CAPACITY。
*
*/
transient Object[] elementData; // non-private to simplify nested class access
构造方法
/**
* Constructs an empty list with the specified initial capacity.
* 指定容量(存储层)构造一个空的(抽象层)ArrayList
* @param initialCapacity the initial capacity of the list
* @throws IllegalArgumentException if the specified initial capacity
* is negative
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;//从这句可以感受到对存储资源的节省---方法区,这就是为什么要特意定义一个EMPTY_ELEMENTDATA的原因!
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* Constructs an empty list with an initial capacity of ten.
* 构造一个存储容量为10的空List
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;//默认容量时缓冲区数组的取值
}
private static final Object[] EMPTY_ELEMENTDATA = {};
DEFAULTCAPACITY_EMPTY_ELEMENTDATA={}------默认容量为空的ArrayList就是Object[]{}
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
elementData----ArrayList具体存储的内容
transient Object[] elementData; // non-private to simplify nested class access
http://www.cnblogs.com/chenpi/p/6185773.html
关于transient的作用:节省序列化过程中的存储空间
size:具体内容的大小
private int size;
private是为了防止别的类去修改它,当然访问没问题,只要ArrayList类内部提供一个public方法去做这件事就OK.非要修改的话其实也可以,就是提供内部一个public方法完成这件事,但设计初衷就导致不可能这么干的.
modCount:这个list被修改的次数
protected transient int modCount = 0;
这个构造方法没读懂
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// defend against c.toArray (incorrectly) not returning Object[]
// (see e.g. https://bugs.openjdk.java.net/browse/JDK-6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
add方法分析(扩容机制)
/**
* Appends the specified element to the end of this list.
* 在ArrayList末尾追加指定的元素
* @param e element to be appended to this list
* @return <tt>true</tt> (as specified by {@link Collection#add})
*/
public boolean add(E e) {
//添加的话肯定得保证存储层分配的容量够啊,也就是看看容量是不是足够size+1.
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;//将e赋值给elementData[size]然后size++;
return true;
}
/**
* 这个函数用来保证容量的
* @param minCapacity-----需求的最小容量:
*/
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));//依据需求的最小容量改变elementData的容量
}
/**
*
*/
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)//如果缓冲区容量不能满足需求的最小容量
grow(minCapacity);//按照需求的最小容量扩容
}
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
* 增加容量,以确保它至少可以容纳由最小容量参数指定的元素数量。
* @param minCapacity: the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);//扩容机制:1.5倍!
if (newCapacity - minCapacity < 0)//扩容新容量还是低于最小容量的话----权衡措施!
newCapacity = minCapacity;//那新容量干脆直接等于the desired minimum capacity得了
if (newCapacity - MAX_ARRAY_SIZE > 0)//要是这个新容量大的过分了,想下容量超过21亿是有点过分
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);//指定容量来复制一个新数组并重新指向(赋值操作)
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow//如果最小容量期望<0,抛出OOM异常?这是因为负数减去负数可能为正数!
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?//一个简单的三元表达式
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
public void ensureCapacity(int minCapacity) {
if (minCapacity > elementData.length
&& !(elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
&& minCapacity <= DEFAULT_CAPACITY)) {
modCount++;
grow(minCapacity);
}
}
get方法分析
/**
* Returns the element at the specified position in this list.
*
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
rangeCheck(index);//检查输入合法性----其实只有上限判断!
return elementData(index);//下限判断,
}
/**
* Checks if the given index is in range. If not, throws an appropriate
* runtime exception. This method does *not* check if the index is
* negative: It is always used immediately prior to an array access,
* which throws an ArrayIndexOutOfBoundsException if index is negative.
*/
private void rangeCheck(int index) {
if (index >= size)//有意思的是只做了上限判断,下限判断其实就是在get方法中的elementData(index)中;
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
// Positional Access Operations
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];//数组index>=0确保下限判断会报异常的,这是更底层所规定的了
}
其它
像remove一些重载方法啥的也不难,需要时在阅读,就是注意用remove从前往后删时自动补位的问题,推荐用Iterator!
Vector源码(过时?虽然安全但效率太低了)
Vector看了一下,和ArrayList源码相似度也太高了。看一下类继承结构图就能感觉到。就不分析了,没啥意义。
贴个关于这个Vector的分析,写的挺好的。
https://www.cnblogs.com/rnmb/p/6553711.html


Vector和ArrayList比较
ArrayList类结构图:
Vector类结构图:
参考链接
https://www.cnblogs.com/rnmb/p/6553711.html
小结:
(1)效率与安全的矛盾
Vector在对元素进行操作的方法加了synchronized,使得线程安全,这也意味着效率可能比较低。
(2)二者扩容比例不同:增删时会进行数组copy
扩容为原来的1.5倍
在add()和remove()时都会进行数组的copy:在大数据效率会比较低下。
Stack(过时)源码
只是在Vector基础上额外增加了一些栈的操作,毕竟栈就是可以视为一个特殊(行为受限)的动态数组。
严格意义上讲Vector不是一个严格的栈,它的其它行为也没有受限呀。

LinkedList源码
参考资料:
https://blog.csdn.net/m0_37884977/article/details/80467658

Linkedlist插入删除较快(这就是队列的特性),查找较慢。
LinkedList是一个双边队列。
线程不安全。
属性罗列

其它
LinkedList之前也读得七七八八了,也没有什么困惑的地方,现在可以先行搁置对源码的分析了!
ArrayList和LinkedList的区别
(1)ArrayList和LinkedList相比占用空间更少。
(2)从遍历的角度来看,
ArrayList的for循环遍历要优于for-each或者Iterator;
LinkedList的for循环遍历要劣于for-each或者Iterator.
上面两句话还是比较好理解的。
同样规模的ArrayList和LinkedList相比:
对于for循环遍历,前者性能优势明显优于后者。
上面这一句话也不难理解,可以参考下面的文章:
https://www.cnblogs.com/ixenos/p/5682979.html
Q:可是
同样规模的ArrayList和LinkedList相比:
对于for-each/Iterator循环遍历,后者性能优势明显优于前者。这是什么原因???
A:看一下Iterator的实现就行了,这算是我对该篇文章的补充。
HashSet源码
参考链接:
https://www.cnblogs.com/whgk/p/6114842.html
HashSet类结构图
TreeSet源码
TreeSet类结构图
HashMap源码
参考链接:
http://www.cnblogs.com/whgk/p/6091316.html
https://www.cnblogs.com/chinajava/p/5808416.html
类结构图:

Map中的键值对如何存储?
HashMap有一个静态内部类Node,这个元素实现了Entry接口(Map接口的内接口)。

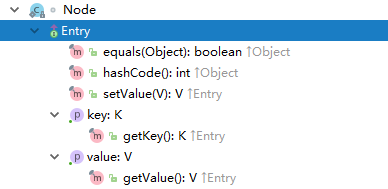

put(HashMap的扩容)
一扩扩两倍,哈希表容量总是2的幂次倍。
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; //节点(K-V)数组叫tab
Node<K,V> p;
int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
Questions:
Q:为什么继承了AbstractMap又要实现Map接口?
A: https://blog.csdn.net/u011392897/article/details/60141739
官方注释:
https://www.cnblogs.com/silyvin/p/9106744.html
也有前辈作了这样的事情,但有些意见相左。这篇博客集中了好几篇质量高的博文,相当好。

HashMap不保证map的顺序, 而且顺序是可变的。
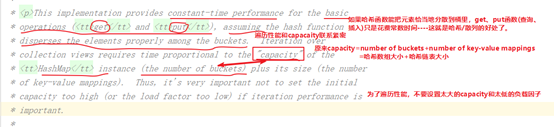
下面这端其实讲的就是哈希表原理:
注意:这是JDK1.8对HashMap的优化, 哈希碰撞后的链表上达到8个节点时要将链表重构为红黑树, 查询的时间复杂度变为O(logN)。
知识点
版本变迁:JDK1.8以前传统HashMap的缺点?
数组+链表,即使哈希函数取得再好,也很难达到元素百分百均匀分布。
针对这种情况,JDK 1.8 中引入了红黑树(查找时间复杂度为 O(logn))来优化这个问题
HashTable和HashMap怎么实现均匀散列?
JDK1.7 indexFor才是用h&(length-1)实现散列的。----要求length为2的幂次。
JDK1.8源码:
哈希数组、哈希链表和哈希红黑树?
集合框架中modCount的意义?
https://www.cnblogs.com/nevermorewang/p/7808197.html
transient modCount为什么不用序列化?
iterator的一些知识
WeakHashMap源码
ConcurrentHashMap源码
TreeMap源码
HashTable(过时)源码
HashMap和HashTable区别
- HashMap是HashTable的轻量级实现,非线程安全
- HashMap允许键值为空,当然只是允许一个
- HashTable使用Enumeration,HashMap使用Iterator
Questions:
Q:为什么不直接实现Iterator?
A:可以实现多重可定制迭代!!!
Properties源码
Iterable和Iterator区别
只有实现了Iterable接口的对象才可以使用for-each循环。?
Iterator是一个遍历器,相当于一个游标。
Iterable和Iterator的区别?这篇文章解释了为什么不合二为一,还提供了匿名内部类对Iterator的实现,很好!!!
https://www.jianshu.com/p/cf82ab7e51ef
HashCode()和equals()源码:
http://www.cnblogs.com/whgk/p/6071617.html
Map接口:
Comparable和Comparator接口:
Java中Comparable和Comparator区别小结
Comparable接口就一个待实现方法:
Comparator接口一个待实现方法,一大堆实体方法。-----那这和实现类有啥区别???
JDK1.8增加了default关键字:
JAVA8新特性——接口定义增强?(default+static)
用处:自然排序+自定义排序
String源码:final,其它字符串类也是
Iterable(增强for循环)和Iterator接口:
参考资料:
Java基础之Iterable与Iterator :https://www.cnblogs.com/albertrui/p/8318336.html
Q:为什么一定要实现Iterable接口,为什么不直接实现Iterator接口呢?
A: 看一下JDK中的集合类,比如List一族或者Set一族,都是实现了Iterable接口,但并不直接实现Iterator接口。 仔细想一下这么做是有道理的。
因为Iterator接口的核心方法next()或者hasNext() 是依赖于迭代器的当前迭代位置的。 如果Collection直接实现Iterator接口,势必导致集合对象中包含当前迭代位置的数据(指针)。 当集合在不同方法间被传递时,由于当前迭代位置不可预置,那么next()方法的结果会变成不可预知。 除非再为Iterator接口添加一个reset()方法,用来重置当前迭代位置。 但即时这样,Collection也只能同时存在一个当前迭代位置。 而Iterable则不然,每次调用都会返回一个从头开始计数的迭代器。 多个迭代器是互不干扰的。
Serializable接口:
参考资料:
Serializable的意义:https://blog.csdn.net/qq_28738419/article/details/80338544
序列化
反序列化
transient修饰的school,我也试过了,果然不能序列化,很好!!!
Cloneable接口
提到了Serializable和浅复制、深复制。
https://blog.csdn.net/qq_37113604/article/details/81168224
浅复制:把基本数据类型复制一份,把引用数据类型指向的地址也复制一份,但并不会把引用数据类型指向的对象也复制一份。
深复制:引用数据类型数据指向的类型都复制一份!!!
如何实现深复制?
(1) 除了String这种方法区的引用数据类型比如自定义的一个类Student等还是应该手动指定clone一份的(也就说这个自定义类也得实现以下这个Cloneable接口)!不过多重引用倒是一件麻烦事,多重引用意味要好几层都重写clone()。
(2) 直接用Serializable先序列化再反序列化一了百了,哈哈哈???!
如何使用?
-
实现标记接口Cloneable,因为一个方法都没有
-
重写Object中的clone()----OK,
-
接下来直接调用obj.clone()就可以了,具体是否深复制还是浅复制得看咋重写的。
clone()局限性
(1) 多重引用在个人未经思考的中型Demo中实现深复制要小心一定。稍有疏忽就不是彻底的深复制了。。。
(2) 像StringBuilder这样的非自定义类没有实现Cloneable接口想clone都不行。
???忽然想到了,好像也不是特别麻烦,直接再new一哈StringBuffer就OK!!!
CharSequence接口:
不用想的太复杂,就是定义了一些“字符序列“相关类应该具有的功能,具体见下图:
实现了这个接口的类包括以下几个,具体有兴趣的话用快捷键ctrl+alt+B(IntelliJ IDEA)查看实现类:















 1524
1524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









