







目录
概述
链表是一种常见的数据结构,用于存储和组织数据。它由一系列节点组成,每个节点包含数据和指向下一个节点的指针。链表中的每个节点都是独立分配的,它们在内存中可以不连续地存储。
链表的主要特点是灵活性。相比于数组,链表的长度可以动态地增加或减少,不需要预先分配固定大小的内存空间。这使得链表在需要频繁插入和删除元素的场景中表现优秀。
一个单向链表节点基本上是由两个元素,即数据字段和指针所组成,而指针将会指向下一个元素在内存中的地址。在“单向链表”中第一个节点是“链表头指针”。指向最一个节点的指针设为NULL,表示它是“链表尾”,不指向任何地方。
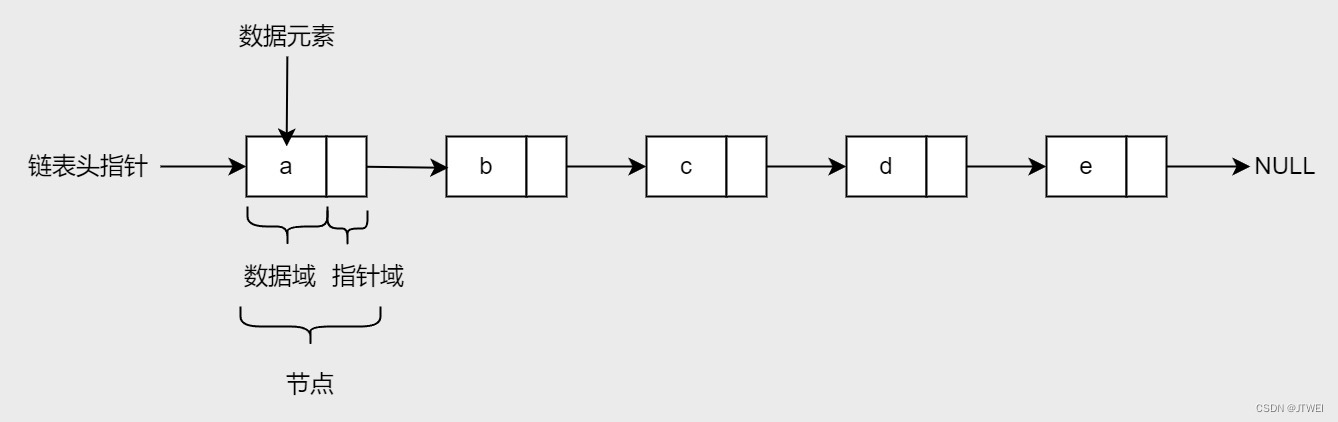
由于单向链表中所有节点都知道节点本身的下一个节点在哪里,但是对于前一个节点却没有办法知道,所以在单向链表的各种操作中,“链表头指针”就显得相当重要,只要存在链表头指针,就可以遍历整个链表、进行加入和删除节点等操作。一旦“链表头指针”丢失,将丢失整个链表。
单向链表
链表的节点类(Node)
在C或者C++语言中,是以指针(Pointer)类型来处理链表类型的数据结构。
typedef struct Node
{
ElemType data;
struct Node *next //*表示指针
} Node;C#虽然不使用指针,但因为启用了对象引用机制,从某种角度也间接实现了指针的某些作用,因此可以把链表声明为类(Class)。
class Node
{
//表示数据域,为了方便理解这里先声明为string类型,在实际项目中,多数为泛型
public string data;
//代替指针域
public Node next;
public Node(string data)
{
this.data = data;
this.next = null;
}
}链表的基础方法
有了Node类之后,我们就可以创建单向链表了,在LinkedList类中,定义了两个Node类节点指针,分别指向链表的第一个节点和最后一个节点。另外,在该类中声明两个常用方法,IsEmpty(),Print()。
class LinkedList
{
private Node first;
private Node last;
//用来判断当前的链表是否为空列表
public bool IsEmpty()
{
return first == null;
}
//用来将当前的链表内容打印出来
public void Print()
{
Node current = first;
while (current != null)
{
Console.WriteLine(current.data);
current = current.next;
}
}
}链表的Add方法
把数据添加到链表的最后一个节点。此时,有“链表为空”和“链表不为空”两种情况。
public void Add(string data)
{
Node newNode = new Node(data);
//如果链表为空,新建的节点既是第一个也是最后一个
//当前节点的没有后继节点,所以first.next=null,last.next=null;
if (this.IsEmpty())
{
first = newNode;
last = newNode;
}
else
{
//当链表不为空,当前链表里的last(最后一个节点)的后继节点为新建的节点
last.next = newNode;
//当前链表的最后一个节点就是新建节点
last = newNode;
}
}
链表的Remove方法
此时,有“删除链表的第一个节点”、“删除链表内的中间节点”、“删除链表后的最后一个节点”三种情况需要考虑。
public void Remove(string delData)
{
//链表为空无须执行
if (this.IsEmpty())
{
Console.WriteLine("链表为空!!!");
return;
}
//在链表中删除一个节点,根据所删除节点的位置会存在三种情况
Node newNode;
Node tmp;
//删除链表的第一个节点
if (first.data == delData)
{
//只要把链表头指针指向第二个节点即可
first = first.next;
}
//删除链表的最后一个节点
else if (last.data == delData)
{
newNode = first;
//找到链表的倒数第二个节点
while (newNode.next != last)
{
newNode = newNode.next;
}
//将倒数第二个节点的指针域设为null
newNode.next = null;
last= newNode;
}
//删除链表的中间某个节点
else
{
newNode = first;
tmp = first;
//找到当前节点
while (newNode.data!= delData)
{
tmp = newNode; //当前节点
newNode = newNode.next; //当前节点的下一个节点
}
//将删除节点的前一个节点的指针,指向欲删除节点的下一个节点
tmp.next = newNode.next;
}
}
链表的串联方法
此时只需要把链表1的最后一个节点的指针指向链表2的第一个节点就可以了
public LinkedList Concatenate(LinkedList list1,LinkedList list2)
{
LinkedList ptr;
ptr = list1;
//通过遍历找到最后一个节点
while(ptr.last.next != null)
{
ptr.last=ptr.last.next;
}
//把链表1的最后一个节点的指针指向链表2的第一个节点
ptr.last.next = list2.first;
return list1;
}链表的反转
由于单向链表中的节点特性是知道下一个节点的位置,可是却无法得知它上一个节点的位置。如果需要反过来输出单向链表应该怎么办呢?思路是,遍历链表,把每个节点从后往前插入到新的链表。
public LinkedList Reverse()
{
LinkedList tmp = new LinkedList();
//从当前链表的第一个节点开始遍历
Node current = first;
while (current != null)
{
//记录一下下一个节点,因为是引用类型,(因为之后的操作current.next会被置空)
Node next = current.next;
if (tmp.IsEmpty())
{
//当tmp为空时,first和last 都是current;
tmp.first = current;
tmp.last = current;
tmp.last.next = null;
}
else
{
//记录下当前的头节点
Node before = tmp.first;
//当不为空时,每次只需要把节点添加到tmp的头节点
tmp.first = current;
//把当前的头节点的指针,指向上一个头节点
tmp.first.next = before;
}
//移向下一个节点
current = next;
}
return tmp;
}
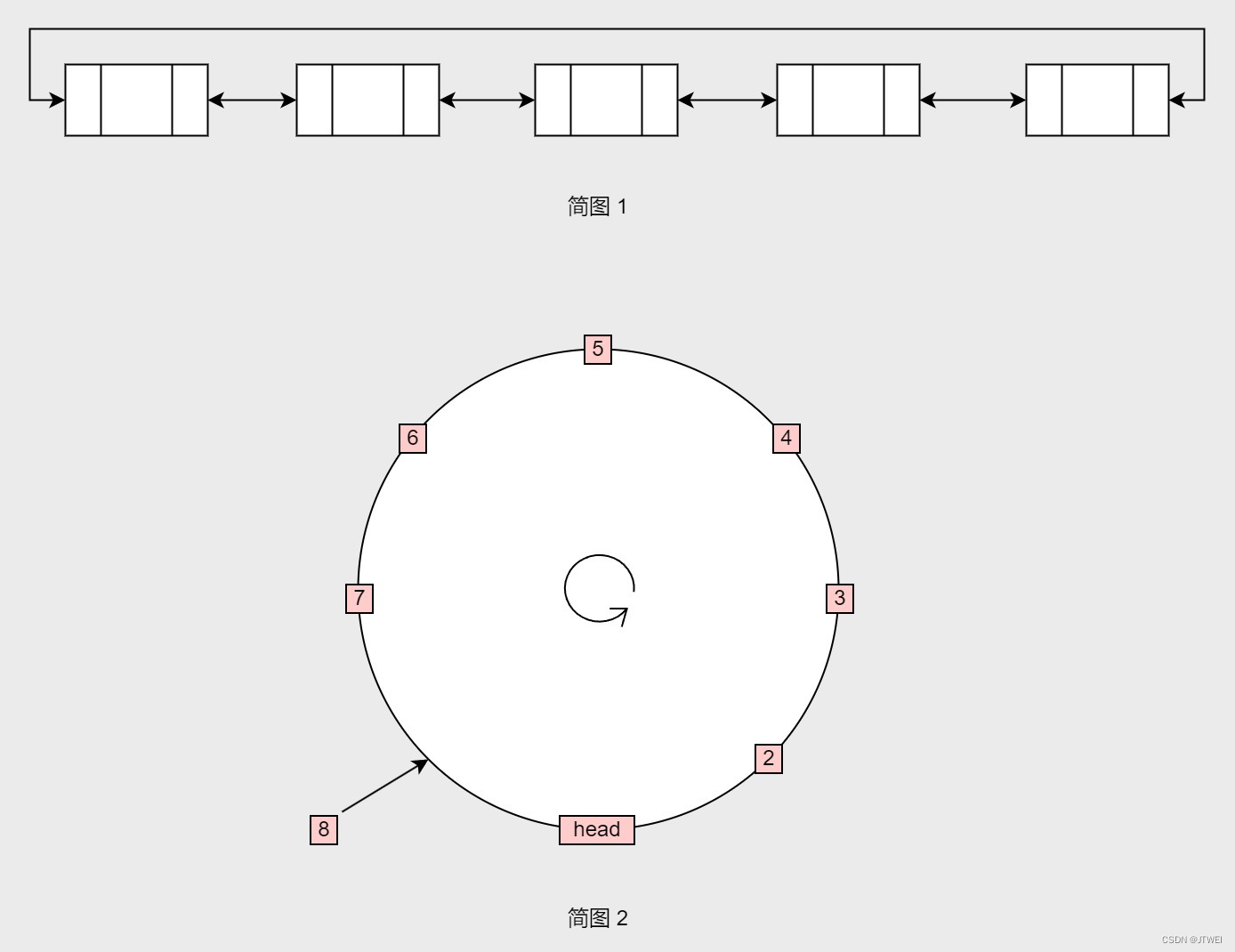
环形链表
在单向链表中,链表头指针一旦被破坏或者意识,则整个链表就会遗矢。如果我们把链表的最后一个节点指针指向链表头部,而不是指向null,那么整个链表就成为一个单方向的环形结构。因为每一个节点都可以是链表头部,所以可以从任一节点来遍历其他节点。

环形链表的优缺点
| 优点 | 缺点 |
| 1.可以从任一节点遍历其他节点。 2.遍历整个链表的时间是固定的,与链表长度无关 | 1.需要多一个链接空间。 2.插入一个节点需要改变两个链接。 |
完整代码示例
using System;
public class Node
{
public string Data { get; }
public Node Next { get; set; }
public Node(string data)
{
Data = data;
Next = null;
}
}
public class CircularLinkedList
{
private Node Head { get; set; }
/// <summary>
/// 判断链表是否为空
/// </summary>
/// <returns>如果链表为空,返回true;否则返回false</returns>
public bool IsEmpty()
{
return Head == null;
}
/// <summary>
/// 输出链表中的所有数据
/// </summary>
public void Display()
{
if (IsEmpty())
{
Console.WriteLine("环形链表为空。");
return;
}
Node current = Head;
do
{
Console.Write(current.Data + " -> ");
current = current.Next;
} while (current != Head);
Console.WriteLine();
}
/// <summary>
/// 增加一条数据到链表中
/// </summary>
/// <param name="data">要添加的数据</param>
public void Add(string data)
{
Node newNode = new Node(data);
if (IsEmpty())
{
// 链表为空时,将新节点作为头节点,并构成循环
Head = newNode;
newNode.Next = Head;
}
else
{
// 遍历链表,找到最后一个节点
Node lastNode = GetLastNode();
// 将新节点添加到最后一个节点之后
lastNode.Next = newNode;
// 设置新节点的下一个节点为头节点,构成循环
newNode.Next = Head;
}
}
/// <summary>
/// 从链表中移除指定数据的节点
/// </summary>
/// <param name="data">要移除的数据</param>
public void Remove(string data)
{
if (IsEmpty())
{
Console.WriteLine("环形链表为空。");
return;
}
Node current = Head;
Node previous = null;
do
{
if (current.Data.Equals(data))
{
if (previous != null)
{
// 如果要移除的节点不是头节点,则更新前一个节点的Next指针
previous.Next = current.Next;
// 如果要移除的节点是头节点,更新Head指针
if (current == Head)
{
Head = current.Next;
}
}
else
{
// 如果要移除的节点是唯一节点,则将Head设为null
if (current.Next == Head)
{
Head = null;
}
else
{
// 如果要移除的节点是头节点,更新Head指针,并将链表最后一个节点指向新的Head
Node lastNode = GetLastNode();
Head = current.Next;
lastNode.Next = Head;
}
}
Console.WriteLine($"成功从环形链表中移除数据:{data}。");
return;
}
previous = current;
current = current.Next;
} while (current != Head);
Console.WriteLine($"环形链表中不存在数据:{data}。");
}
/// <summary>
/// 将另一个链表连接到当前链表的末尾
/// </summary>
/// <param name="list">要连接的链表</param>
public void Concatenate(CircularLinkedList list)
{
if (list.IsEmpty())
{
Console.WriteLine("要连接的链表为空。");
return;
}
if (IsEmpty())
{
// 如果当前链表为空,直接将另一个链表设置为当前链表
Head = list.Head;
}
else
{
// 如果当前链表不为空,在当前链表的最后一个节点之后连接另一个链表
Node lastNode = GetLastNode();
lastNode.Next = list.Head;
}
// 使新的链表成为环形链表
Node lastNodeInList = list.GetLastNode();
lastNodeInList.Next = Head;
}
/// <summary>
/// 判断链表中是否包含指定数据的节点
/// </summary>
/// <param name="data">要查找的数据</param>
/// <returns>如果链表中包含指定数据的节点,返回true;否则返回false</returns>
public bool Contains(string data)
{
if (IsEmpty())
{
return false;
}
Node current = Head;
do
{
if (current.Data.Equals(data))
{
return true;
}
current = current.Next;
} while (current != Head);
return false;
}
private Node GetLastNode()
{
Node current = Head;
while (current.Next != Head)
{
current = current.Next;
}
return current;
}
}双向链表 (C#源码分析)
单向链表和环形链表都是属于拥有方向性的链表,只能单向遍历,万一某一个链接断裂,那么后面的链表数据变回遗失而无法复原。因此,我们可以将两个方向不同的链表结合起来,除了存放数据的字段外,他还有两个指针变量(prev,next),其中一个指针指向后面的节点,另一个则指向前面的节点,这样的链表被称为双向链表(Double Linked List)。

双向链表的优缺点
| 优点 | 缺点 |
| 1.能够轻松地找到前后节点, 2.因为双向链表中任一节点都可以找到其他节点,从而不需要反转或对比节点等处理,执行速度较快。 3.如果任一节点的链接断裂,可以通过反向链表进行遍历,从而快速地重建完整的链表。 | 1.在加入或删除节点时都需要调整leftNode,rightNode两个指针。 2.因为每个节点含有两个指针变量,所以较良妃空间。 |
在C# dotNet框架中已经封装好了一个双向链表,所以我们不在自己实现双向链表,而是直接分析源码。
源码地址
LinkedList<T>源码:
https://learn.microsoft.com/zh-cn/dotnet/api/system.collections.generic.linkedlist-1?view=net-7.0
LinkedList<T>API:
LinkedListNode<T>类
// Note following class is not serializable since we customized the serialization of LinkedList.
// 注意下面的类是不可序列化的,因为我们自定义了LinkedList的序列化。
[System.Runtime.InteropServices.ComVisible(false)]
public sealed class LinkedListNode<T> {
//所属的LinkedList<T>的引用,表示他属于哪个LinkedList。
internal LinkedList<T> list;
//下一个节点的引用
internal LinkedListNode<T> next;
//上一个节点的引用
internal LinkedListNode<T> prev;
//获取节点中包含的值。
internal T item;
public LinkedListNode( T value) {
this.item = value;
}
internal LinkedListNode(LinkedList<T> list, T value) {
this.list = list;
this.item = value;
}
public LinkedList<T> List {
get { return list;}
}
//获取 LinkedList<T> 中的下一个节点。
public LinkedListNode<T> Next {
get { return next == null || next == list.head? null: next;}
}
//获取 LinkedList<T> 中的上一个节点。
public LinkedListNode<T> Previous {
get { return prev == null || this == list.head? null: prev;}
}
//获取节点中包含的值。
public T Value {
get { return item;}
set { item = value;}
}
//清空
internal void Invalidate() {
list = null;
next = null;
prev = null;
}
}
LinkedList<T>类
基本属性
-
Count:获取 LinkedList<T> 中实际包含的节点数。
-
First:获取 LinkedList<T> 的第一个节点。
-
Last:获取 LinkedList<T> 的最后一个节点。
public class LinkedList<T> : ICollection<T>, System.Collections.ICollection, IReadOnlyCollection<T>, ISerializable, IDeserializationCallback
{
// This LinkedList is a doubly-Linked circular list.
// 这个LinkedList是一个双链循环列表
internal LinkedListNode<T> head;
internal int count;
internal int version;
private Object _syncRoot;
// names for serialization
const String VersionName = "Version";
const String CountName = "Count";
const String ValuesName = "Data";
public int Count
{
get { return count; }
}
public LinkedListNode<T> First
{
get { return head; }
}
public LinkedListNode<T> Last
{
get { return head == null ? null : head.prev; }
}
}
构造方法
//初始化一个空的LinkedList类的新实例
public LinkedList() {}
//初始化LinkedList类的新实例,该实例包含从指定的System.Collections.IEnumerable复制的元素,
//并且有足够的容量容纳复制的元素数量。
public LinkedList(IEnumerable<T> collection) {
if (collection==null) {
throw new ArgumentNullException("collection");
}
foreach( T item in collection) {
AddLast(item);
}
}
//初始化LinkedList类的一个新实例,
//该实例可以用指定的System.Runtime.Serialization.SerializationInfo和System.Runtime.Serialization.StreamingContext进行序列化。
#if !SILVERLIGHT
protected LinkedList(SerializationInfo info, StreamingContext context)
siInfo = info;
}
#endifAdd方法
-
AddAfter:指定的现有节点后添加指定的新节点
-
AddBefore:指定的现有节点前添加指定的新节点
-
AddFirst:开头处添加指定的新节点
-
AddLast:结尾处添加指定的新节点
//判断参数是否有效
internal void ValidateNewNode(LinkedListNode<T> node) {
if (node == null) {
throw new ArgumentNullException("node");
}
if ( node.list != null) {
throw new InvalidOperationException(SR.GetString(SR.LinkedListNodeIsAttached));
}
}
//内部插入节点前 (下划有对该方法的图解)
private void InternalInsertNodeBefore(LinkedListNode<T> head, LinkedListNode<T> newNode) {
newNode.next = head;
newNode.prev = head.prev;
head.prev.next = newNode;
head.prev = newNode;
version++;
count++;
}
//内部插入到空链表
private void InternalInsertNodeToEmptyList(LinkedListNode<T> newNode) {
Debug.Assert( head == null && count == 0, "LinkedList must be empty when this method is called!");
newNode.next = newNode;
newNode.prev = newNode;
head = newNode;
version++;
count++;
}
//在LinkedList中指定的现有节点之后添加指定的新节点
public LinkedListNode<T> AddAfter(LinkedListNode<T> node, T value) {
ValidateNode(node);
LinkedListNode<T> result = new LinkedListNode<T>(node.list, value);
//重点:node.next,意思是插入下一个节点前,也就是当前节点后
InternalInsertNodeBefore(node.next, result);
return result;
}
public void AddAfter(LinkedListNode<T> node, LinkedListNode<T> newNode) {
ValidateNode(node);
ValidateNewNode(newNode);
InternalInsertNodeBefore(node.next, newNode);
newNode.list = this;
}
public LinkedListNode<T> AddBefore(LinkedListNode<T> node, T value) {
ValidateNode(node);
LinkedListNode<T> result = new LinkedListNode<T>(node.list, value);
//AddBefore 与 AddAfter 的主要区别就是参数 node 和 node.next的区别
InternalInsertNodeBefore(node, result);
//需要考虑是不是头节点
if ( node == head) {
head = result;
}
return result;
}
public void AddBefore(LinkedListNode<T> node, LinkedListNode<T> newNode) {
ValidateNode(node);
ValidateNewNode(newNode);
InternalInsertNodeBefore(node, newNode);
newNode.list = this;
if ( node == head) {
head = newNode;
}
}
public LinkedListNode<T> AddFirst(T value) {
LinkedListNode<T> result = new LinkedListNode<T>(this, value);
//如果链表为空,直接添加到空
if (head == null) {
InternalInsertNodeToEmptyList(result);
}
else {
InternalInsertNodeBefore( head, result);
//注意:AddFirst 和 AddLast 的主要区别就是这句话,改变链表头节点。
head = result;
}
return result;
}
public void AddFirst(LinkedListNode<T> node) {
ValidateNewNode(node);
if (head == null) {
InternalInsertNodeToEmptyList(node);
}
else {
InternalInsertNodeBefore( head, node);
head = node;
}
node.list = this;
}
public LinkedListNode<T> AddLast(T value) {
LinkedListNode<T> result = new LinkedListNode<T>(this, value);
if (head== null) {
InternalInsertNodeToEmptyList(result);
}
else {
InternalInsertNodeBefore( head, result);
}
return result;
}
public void AddLast(LinkedListNode<T> node) {
ValidateNewNode(node);
if (head == null) {
InternalInsertNodeToEmptyList(node);
}
else {
InternalInsertNodeBefore( head, node);
}
node.list = this;
}
从源码可以知道,AddAfter、AddBefore、AddFirst、AddLast方法都用到了InternalInsertNodeBefore这个方法,从名称我们可以看出,这个方法是把节点插入到指定节点之前,那么,究竟是如何通过一个方法实现了不同的插入次序呢?
private void InternalInsertNodeBefore(LinkedListNode<T> node, LinkedListNode<T> newNode)
{
newNode.next = node;
newNode.prev = node.prev;
node.prev.next = newNode;
node.prev = newNode;
version++;
count++;
}

查找方法
-
Contains(T):确定某值是否在 LinkedList<T> 中。
-
Find(T):查找包含指定值的第一个节点。
-
FindLast(T):查找包含指定值的最后一个节点。
-
GetEnumerator:返回循环访问 LinkedList<T> 的枚举数。
public bool Contains(T value) {
return Find(value) != null;
}
//查找包含指定值的第一个节点
public LinkedListNode<T> Find(T value) {
LinkedListNode<T> node = head;
EqualityComparer<T> c = EqualityComparer<T>.Default;
if (node != null) {
if (value != null) {
do {
if (c.Equals(node.item, value)) {
return node;
}
node = node.next;
} while (node != head);
}
else {
do {
if (node.item == null) {
return node;
}
node = node.next;
} while (node != head);
}
}
return null;
}
//查找包含指定值的最后一个节点。
public LinkedListNode<T> FindLast(T value) {
if ( head == null) return null;
LinkedListNode<T> last = head.prev;
LinkedListNode<T> node = last;
EqualityComparer<T> c = EqualityComparer<T>.Default;
if (node != null) {
if (value != null) {
do {
if (c.Equals(node.item, value)) {
return node;
}
node = node.prev;
} while (node != last);
}
else {
do {
if (node.item == null) {
return node;
}
node = node.prev;
} while (node != last);
}
}
return null;
}
public Enumerator GetEnumerator() {
return new Enumerator(this);
}
IEnumerator<T> IEnumerable<T>.GetEnumerator() {
return GetEnumerator();
}
#if !SILVERLIGHT
[Serializable()]
#endif
[SuppressMessage("Microsoft.Performance", "CA1815:OverrideEqualsAndOperatorEqualsOnValueTypes", Justification = "not an expected scenario")]
public struct Enumerator : IEnumerator<T>, System.Collections.IEnumerator
#if !SILVERLIGHT
, ISerializable, IDeserializationCallback
#endif
{
private LinkedList<T> list;
private LinkedListNode<T> node;
private int version;
private T current;
private int index;
#if !SILVERLIGHT
private SerializationInfo siInfo; //A temporary variable which we need during deserialization.
#endif
const string LinkedListName = "LinkedList";
const string CurrentValueName = "Current";
const string VersionName = "Version";
const string IndexName = "Index";
internal Enumerator(LinkedList<T> list) {
this.list = list;
version = list.version;
node = list.head;
current = default(T);
index = 0;
#if !SILVERLIGHT
siInfo = null;
#endif
}
#if !SILVERLIGHT
internal Enumerator(SerializationInfo info, StreamingContext context) {
siInfo = info;
list = null;
version = 0;
node = null;
current = default(T);
index = 0;
}
#endif
public T Current {
get { return current;}
}
object System.Collections.IEnumerator.Current {
get {
if( index == 0 || (index == list.Count + 1)) {
ThrowHelper.ThrowInvalidOperationException(ExceptionResource.InvalidOperation_EnumOpCantHappen);
}
return current;
}
}
public bool MoveNext() {
if (version != list.version) {
throw new InvalidOperationException(SR.GetString(SR.InvalidOperation_EnumFailedVersion));
}
if (node == null) {
index = list.Count + 1;
return false;
}
++index;
current = node.item;
node = node.next;
if (node == list.head) {
node = null;
}
return true;
}
void System.Collections.IEnumerator.Reset() {
if (version != list.version) {
throw new InvalidOperationException(SR.GetString(SR.InvalidOperation_EnumFailedVersion));
}
current = default(T);
node = list.head;
index = 0;
}
public void Dispose() {
}
#if !SILVERLIGHT
void ISerializable.GetObjectData(SerializationInfo info, StreamingContext context) {
if (info==null) {
throw new ArgumentNullException("info");
}
info.AddValue(LinkedListName, list);
info.AddValue(VersionName, version);
info.AddValue(CurrentValueName, current);
info.AddValue(IndexName, index);
}
void IDeserializationCallback.OnDeserialization(Object sender) {
if (list != null) {
return; //Somebody had a dependency on this Dictionary and fixed us up before the ObjectManager got to it.
}
if (siInfo==null) {
throw new SerializationException(SR.GetString(SR.Serialization_InvalidOnDeser));
}
list = (LinkedList<T>)siInfo.GetValue(LinkedListName, typeof(LinkedList<T>));
version = siInfo.GetInt32(VersionName);
current = (T)siInfo.GetValue(CurrentValueName, typeof(T));
index = siInfo.GetInt32(IndexName);
if( list.siInfo != null) {
list.OnDeserialization(sender);
}
if( index == list.Count + 1) { // end of enumeration
node = null;
}
else {
node = list.First;
// We don't care if we can point to the correct node if the LinkedList was changed
// MoveNext will throw upon next call and Current has the correct value.
if( node != null && index != 0) {
for(int i =0; i< index; i++) {
node = node.next;
}
if( node == list.First) {
node = null;
}
}
}
siInfo=null;
}
#endif
}
从方法可以看出, 是从链表的头节点开始遍历,对比item的值。
删除方法
-
Clear():从 LinkedList<T> 中移除所有节点。
-
Remove(LinkedListNode<T>) :从 LinkedList<T> 中移除指定的节点。
-
Remove(T):从 LinkedList<T> 中移除指定值的第一个匹配项。
-
RemoveFirst():移除位于 LinkedList<T> 开头处的节点。
-
RemoveLast():移除位于 LinkedList<T> 结尾处的节点。
public void Clear() {
LinkedListNode<T> current = head;
while (current != null ) {
LinkedListNode<T> temp = current;
current = current.Next; // use Next the instead of "next", otherwise it will loop forever
temp.Invalidate();
}
head = null;
count = 0;
version++;
}
public bool Remove(T value) {
LinkedListNode<T> node = Find(value);
if (node != null) {
InternalRemoveNode(node);
return true;
}
return false;
}
public void Remove(LinkedListNode<T> node) {
ValidateNode(node);
InternalRemoveNode(node);
}
public void RemoveFirst() {
if ( head == null) { throw new InvalidOperationException(SR.GetString(SR.LinkedListEmpty)); }
InternalRemoveNode(head);
}
public void RemoveLast() {
if ( head == null) { throw new InvalidOperationException(SR.GetString(SR.LinkedListEmpty)); }
InternalRemoveNode(head.prev);
}
internal void InternalRemoveNode(LinkedListNode<T> node) {
Debug.Assert( node.list == this, "Deleting the node from another list!");
Debug.Assert( head != null, "This method shouldn't be called on empty list!");
if ( node.next == node) {
Debug.Assert(count == 1 && head == node, "this should only be true for a list with only one node");
head = null;
}
else {
node.next.prev = node.prev;
node.prev.next = node.next;
if ( head == node) {
head = node.next;
}
}
node.Invalidate();
count--;
version++;
}
//LinkedListNode类中的方法。
internal void Invalidate() {
list = null;
next = null;
prev = null;
}
CopyTo
从目标数组的指定索引处开始将整个 LinkedList<T> 复制到兼容的一维 Array
/*
数组:
一维系统。从LinkedList复制元素的目标数组。数组必须具有从零开始的索引。
指数:
数组中开始复制的从零开始的索引。
*/
public void CopyTo( T[] array, int index) {
if (array == null) {
throw new ArgumentNullException("array");
}
if(index < 0 || index > array.Length) {
throw new ArgumentOutOfRangeException("index",SR.GetString(SR.IndexOutOfRange, index) );
}
if (array.Length - index < Count) {
throw new ArgumentException(SR.GetString(SR.Arg_InsufficientSpace));
}
LinkedListNode<T> node = head;
if (node != null) {
do {
array[index++] = node.item;
node = node.next;
} while (node != head);
}
}














 2626
2626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









