







通过对之前学过的线性表进行时间复杂度分析总结出顺序存储结构线性表的最大问题就是插入和删除需要移动大量的元素,严重影响了效率。为了提高效率,引出一种在逻辑结构上相连但在物理结构上不相连的存储方式--链式存储结构。
链式存储结构的定义
为了表示每个数据元素与其直接后继元素之间的逻辑关系,创建一种结构,结构除了需要存储数据元素本身的信息之外还需要存储其直接后继的信息。如下图:

其中ai和ai+1是线性表中的两个相邻数据元素,但是他们在物理内存上并无相邻关系。
链式存储结构的逻辑结构
在基于链式存储结构的线性表中,每个结点都包含数据域和指针域,其中数据域存储数据元素本身,指针域存储相邻结点的地址,看一幅在内存中更直观的链式存储结构图:
上图表明链表的结点在内存中的地址并不是连续的。
链表分类
链表可以分为单链表、循环链表、双向链表。
单链表:每个结点只包含直接后继的地址信息。
循环链表:单链表中的最后一个结点的直接后继为第一个结点。
双向链表:单链表中的结点包含直接前驱和后继的地址信息。
链表中的概念
头结点:它是链表中的辅助结点,只包含指向第0个数据元素的指针,而没有数据信息,头结点有简化代码的作用,因为它始终指向了第0个元素,便于执行时对元素位置的定位。
数据结点:它是链表中代表数据元素的结点,表现为数据域和指针域。
尾结点:尾结点中存储的地址信息可以用于区分链表类型。为空:单链表。为第0个结点地址:循环链表。为随机值:非法链表。
单链表的结点定义
struct Node : public Object
{
T value;
Node* next;
};结点继承自顶层父类Object。
包含一个泛型变量。
指向Node结构体的指针变量。
成员变量为公有访问级别。
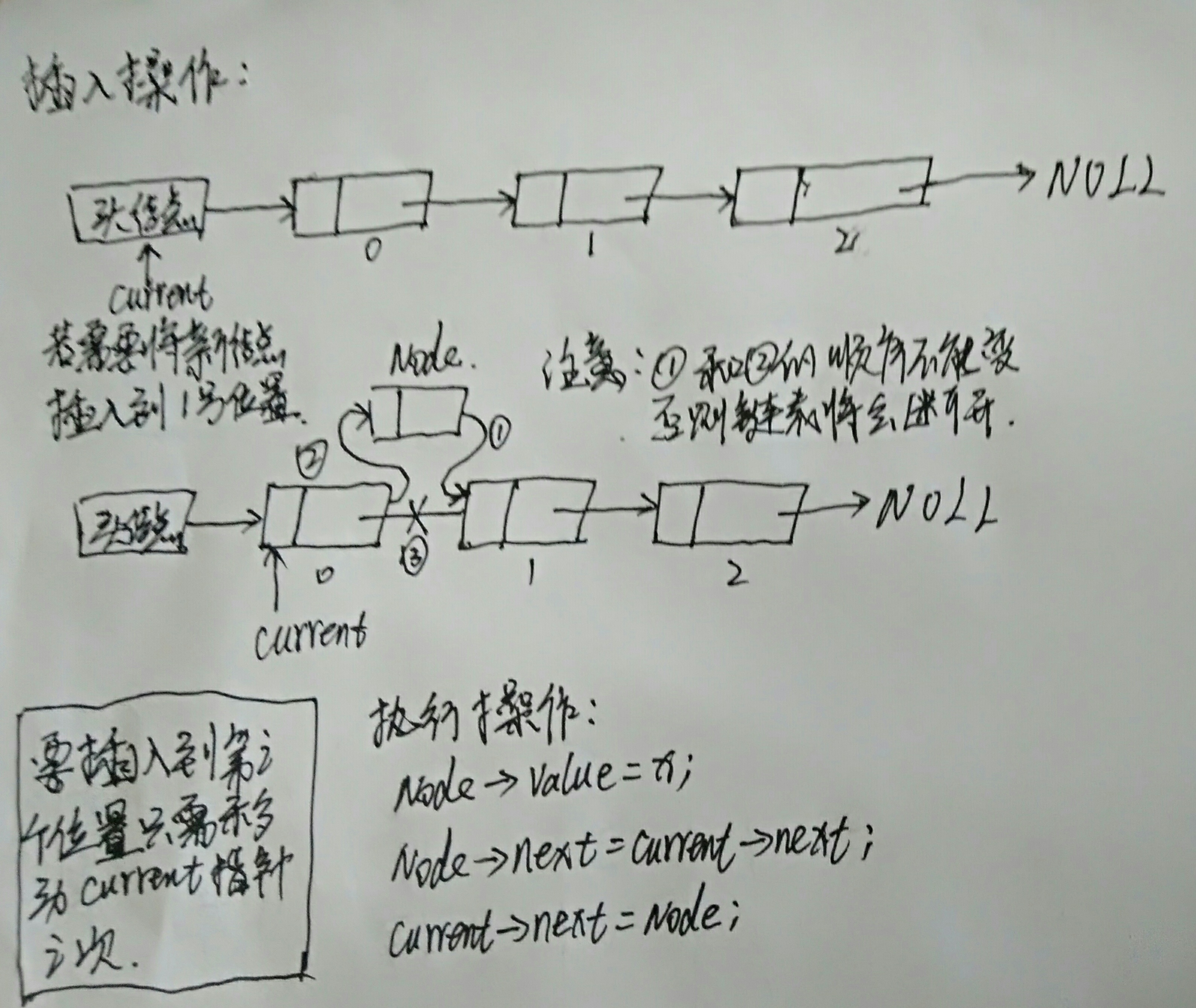
链表的插入操作
从头结点开始,通过current指针定位到待插入的目标位置
从堆空间申请新的Node结点并初始化数据域
执行插入操作。
操作如图:
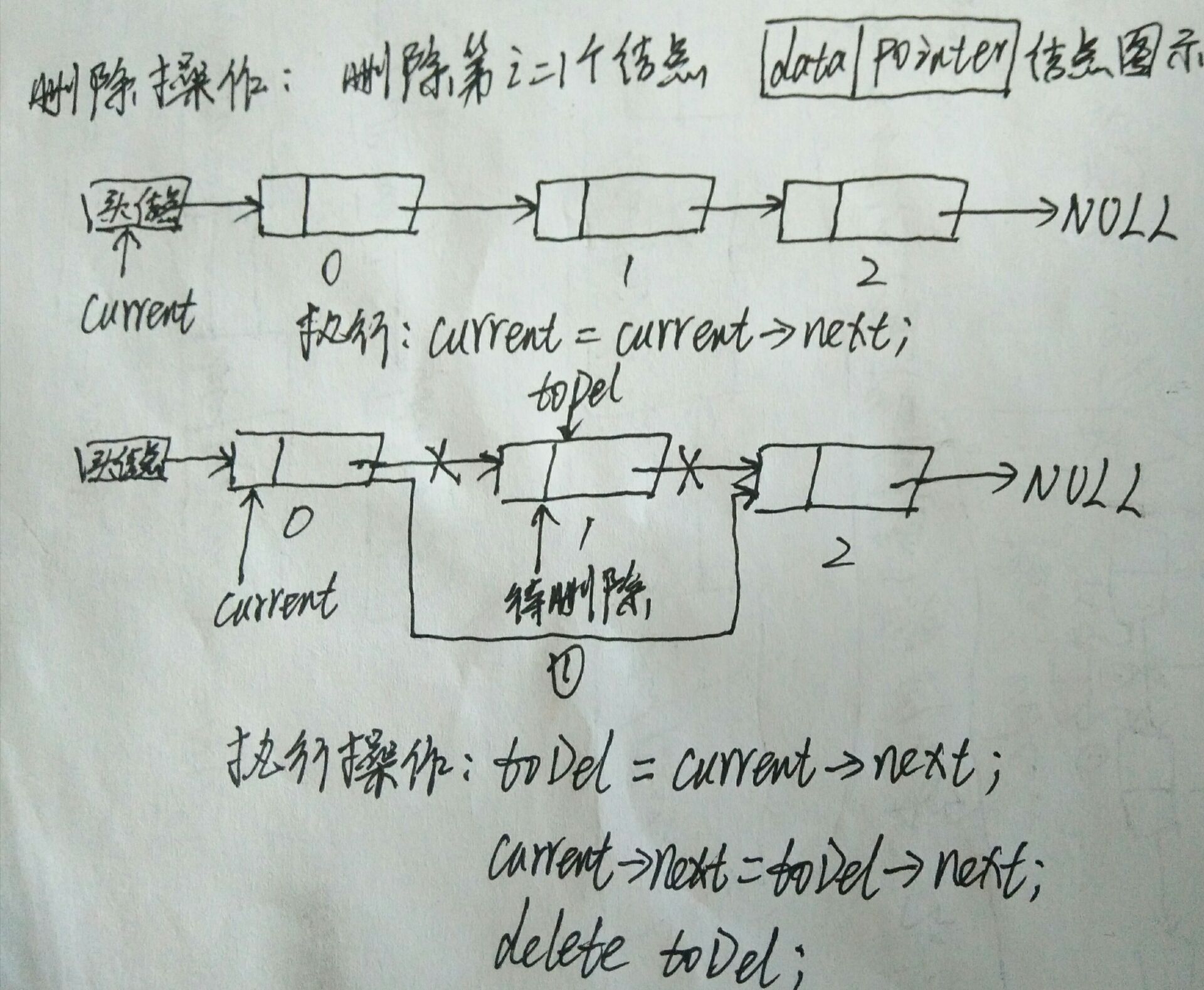
链表的删除操作
从头结点开始,通过current指针定位到目标位置
使用toDel指针指向需要删除的结点
执行删除操作
操作如图:
总结:
链表中的数据元素在物理内存中无相邻关系。
链表中的结点包含数据域和指针域。
头结点用于辅助数据元素定位,方便插入和删除。
插入和删除操作需要保证链表的完整性。















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









