







目录
1. 概述
简单来说,爬虫就是获取网页并提取和保存信息的自动化程序。其应用运行的主要流程:
首先,对待爬取的目标网站进行确定,并从已给定的初始URL链接中提取出一个,对该链接上的信息内容进行分析采集,最终储存到数据库当中。
其后,将网站中未经访问的链接纳入到待爬行列表当中,按照特定顺序逐个进行链接页面的提取、访问、分析、采集、储存。
最后,在循环执行爬行动作并达到程序预设的停止条件时,网络爬虫系统即可自动终止运行。
获取网页——网页源代码
提取信息——分析网页源代码
保存数据——TXT/JSON/SQL/MongoDB等
自动化程序——代替人完成相应操作
2. HTTP——超文本传输协议
所谓“超文本”,就是“超越了普通文本的文本”,它是文字、图片、音频和视频等的混合体,最关键的是含有“超链接”,能够从一个“超文本”跳跃到另一个“超文本”,形成复杂的非线性、网状的结构关系。
可以说HTTP是一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范,以及相关的各种控制和错误处理方式。
HTTP 不是一个孤立的协议,它通常跑在 TCP/IP 协议栈之上,依靠 IP 协议实现寻址和路由、TCP 协议实现可靠数据传输、DNS 协议实现域名查找、SSL/TLS 协议实现安全通信。
在 HTTP 协议里,浏览器的角色被称为“User Agent”即“用户代理”,意思是作为访问者的“代理”来发起 HTTP 请求。不过在不引起混淆的情况下,我们通常都简单地称之为“客户端”。
应答方:Web Server服务器。硬件含义就是物理形式或“云”形式的机器,在大多数情况下它可能不是一台服务器,而是利用反向代理、负载均衡等技术组成的庞大集群。但从外界看来,它仍然表现为一台机器,但这个形象是“虚拟的”。软件含义的 Web 服务器可能我们更为关心,它就是提供 Web 服务的应用程序,通常会运行在硬件含义的服务器上。它利用强大的硬件能力响应海量的客户端 HTTP 请求,处理磁盘上的网页、图片等静态文件,或者把请求转发给后面的 Tomcat、Node.js 等业务应用,返回动态的信息。

HTTP 是一个"传输协议",但它不关心寻址、路由、数据完整性等传输细节,而要求这些工作都由下层来处理。
因为互联网上最流行的是 TCP/IP 协议,而它刚好满足 HTTP 的要求,所以互联网上的 HTTP 协议就运行在了 TCP/IP 上,HTTP 也就可以更准确地称为“HTTP over TCP/IP”。
HTTPS 相当于“HTTP+SSL/TLS+TCP/IP”,为 HTTP 套了一个安全的外壳;
SSL 的全称是“Secure Socket Layer”,SSL 使用了许多密码学最先进的研究成果,综合了对称加密、非对称加密、摘要算法、数字签名、数字证书等技术,能够在不安全的环境中为通信的双方创建出一个秘密的、安全的传输通道,为 HTTP 套上一副坚固的盔甲。
3. URI/URL
Uniform Resource Identifier, 统一资源标识符, 可以定义为引用地址的字符串,用于指示资源的位置以及用于访问它的协议使用它就能够唯一地标记互联网上资源;
Uniform Resource Locator 统一资源定位符,标识逻辑或物理资源的字符序列,是URI的子集。
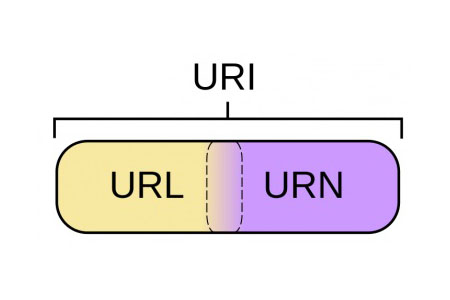
在互联网上,URN用的非常少,几乎所有的URI都是URL,一般的网络链接既可称URL也可称URI。
3.1 URI格式
URI 本质上是一个字符串,这个字符串的作用是唯一地标记资源的位置或者名字。它不仅能够标记万维网的资源,也可以标记其他的,如邮件系统、本地文件系统等任意资源。而“资源”既可以是存在磁盘上的静态文本、页面数据,也可以是由 Java、PHP 提供的动态服务。

URI 第一个组成部分叫scheme,翻译成中文叫“方案名”或者“协议名”,表示资源应该使用哪种协议来访问。最常见的当然就是“http”了,表示使用 HTTP 协议。另外还有“https”,表示使用经过加密、安全的 HTTPS 协议。此外还有其他不是很常见的 scheme,例如 ftp、ldap、file、news 等。
在 scheme 之后,必须是三个特定的字符“://”,这个就是这样规定的。
在“://”之后,是被称为“authority”的部分,表示资源所在的主机名,通常的形式是“host:port”,即主机名加端口号。 HTTP 的默认端口号是 80,HTTPS 的默认端口号是 443。
URI 的 path 部分必须以“/”开始,也就是必须包含“/”,不要把“/”误认为属于前面 authority。
查询参数 query 有一套自己的格式,是多个“key=value”的字符串,这些 KV 值用字符“&”连接,浏览器和客户端都可以按照这个格式把长串的查询参数解析成可理解的字典或关联数组形式。
“query”部分,它在 path 之后,用一个“?”开始,但不包含“?”,表示对资源附加的额外要求。
其中主机名之前的身份信息“user:passwd@”,表示登录主机时的用户名和密码,现在不推荐使用这种形式了(RFC7230)
查询参数后的片段标识符“#fragment”,它是 URI 所定位的资源内部的一个“锚点”或者说是“标签”,浏览器可以在获取资源后直接跳转到它指示的位置。但片段标识符仅能由浏览器这样的客户端使用,服务器是看不到的。也就是说,浏览器永远不会把带“#fragment”的 URI 发送给服务器,服务器也永远不会用这种方式去处理资源的片段。
3.2 URI的编码
URI 转义的规则有点“简单粗暴”,直接把非 ASCII 码或特殊字符转换成十六进制字节值,然后前面再加上一个“%”。中文、日文等则通常使用 UTF-8 编码后再转义。
4. 请求
直观地说,我们在浏览器中输入一个URL,按下回车,这个过程就是浏览器向网站服务器发出了一个请求。
请求,由客户端向服务端发出,大体可以分为4个部分:请求方法(Request Method)、请求的网址(Request URL)、请求头(Request Headers)以及请求体(Request Body)。


4.1 请求方法
HTTP/1.1 规定了八种方法:
1. GET:从服务器获取资源,可以理解为读取或者下载数据;
2. HEAD:从服务器获取资源的元信息——服务器不会返回请求的实体数据,只会传回响应头;
3. POST:向资源提交数据,相当于写入或上传数据;向 URI 指定的资源提交数据,数据就放在报文的 body 里
4. PUT:类似 POST;
5. DELETE:指示服务器删除资源;
6. CONNECT:要求服务器为客户端和另一台远程服务器建立一条特殊的连接隧道;
7. OPTIONS:列出可对资源实行的方法;
8.TRACE:追踪请求 - 响应的传输路径

常见的请求方法主要又两种:GET和POST。
一般情况下,涉及有上传文件、登录账号等含有敏感信息的操作时,通常使用POST。其他情况用get。我在看这方面的内容时,发现有另一个博主总结的很好,在此不再赘述,附链接如下:https://blog.csdn.net/qq_38182125/article/details/89071899
4.2 请求头Headers
Accept:请求报头域,用于指定客户端可接受哪些类型的信息。
Accept-Language:指定客户端可接受的语言类型。
Accept-Encoding:指定客户端可接受的内容编码。
Host:用于指定请求资源的主机IP和端口号,其内容为请求URL 的原始服务器或网关的位置。
Cookie:也常用复数形式Cookies,这是网站为了辨别用户进行会话跟踪而存储在用户本地的数据。它的主要功能是维持当前访问会话。例如,我们输入用户名和密码成功登录某个网站后,服务器会用会话保存登录状态信息,后面我们每次刷新或请求该站点的其他页面时,会发现都是登录状态,这就是Cookies 的功劳。Cookies里有信息标识了我们所对应的服务器的会话,每次浏览器在请求该站点的页面时,都会在请求头中加上 Cookies 并将其发送给服务器,服务器通过 Cookies识别出是我们自己,并且查出当前状态是登录状态,所以返回结果就是登录之后才能看到的网页内容。
Referer:此内容用来标识这个请求是从哪个页面发过来的,服务器可以拿到这一信息并做相应的处理,如做来源统计、防盗链处理等。
User-Agent:简称UA,它是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本、浏览器及版本等信息。在做爬虫时加上此信息,可以伪装为浏览器;如果不加,很可能会被识别出为爬虫。
Content-Type:也叫互联网媒体类型( Internet Media Type)或者MIME类型,在HTTP协议消息头中,它用来表示具体请求中的媒体类型信息。例如,texthtml 代表 HTML 格式,image/gif代表GIF图片,application/json代表JSON类型。

5.响应
所谓“响应”是浏览器发出请求后,服务器返回的信息。通过向服务器发送请求,服务器返回的响应体即是网页源代码。
响应,可以分为三个部分:响应状态码(Response Status Code)、响应头(Response Headers)以及响应体(Response Body)
5.1 响应状态码——表示了服务器对请求的处理结果
由于请求方法是一个“指示”,那么客户端自然就没有决定权,服务器掌控着所有资源,也就有绝对的决策权力。它收到 HTTP 请求报文后,看到里面的请求方法,可以执行也可以拒绝,或者改变动作的含义,毕竟 HTTP 是一个“协议”,两边都要“商量着来”。
若服务器拒绝。一般会返回以下三种响应:
1.假装这个文件不存在,直接返回一个 404 Not found 报文;
2.稍微友好一点,明确告诉你有这个文件,但不允许访问,返回一个 403 Forbidden;
3.再宽松一些,返回 405 Method Not Allowed,然后用 Allow 头告诉你可以用 HEAD 方法获取文件的元信息
目前 RFC 标准里规定的状态码是三位数,所以取值范围就是从 000 到 999。RFC 标准把状态码分成了五类,用数字的第一位表示分类,而 0~99 不用,这样状态码的实际可用范围就大大缩小了,由 000~999 变成了 100~599。
1××:提示信息,表示目前是协议处理的中间状态,还需要后续的操作;实际能够用到的时候很少
2××:成功,报文已经收到并被正确处理;
3××:重定向,资源位置发生变动,需要客户端重新发送请求;
4××:客户端错误,请求报文有误,服务器无法处理;
5××:服务器错误,服务器在处理请求时内部发生了错误
6.常见的反扒机制
爬虫和反爬虫技术是矛与盾之争,且换代周期越来越短,故需要长期化、系统化、平台化、标准化的研究,以避免每次遇到不同的爬虫和反爬虫问题都重新进行重复冗余的工作。
6.1 服务端限制
反爬虫技术通常先在服务器端进行请求限制,防止爬虫进行数据请求,从源头限制恶意数据爬取。通常有如下几种方式。
6.1.1 请求头Headers审查
HTTP的请求头是在每次向网络服务器发送请求时,传递的一组属性和配置信息。服务器通常通过这组属性和配置信息来判断访问网站的对象。
Headers包含很多配置信息,目前来看,其中User-Agent、Referer以及Cookie经常被用于反爬设置。
对于每个浏览器,访问网站都会有其固定的 user-agent,通常以“Mozilla/4.0”开头,而网络爬虫的User-agent 一般为空缺的,或者以“Scrapy”、“Python”等常见爬虫框架/工具的名称开头。
每个浏览器、知名的爬虫都有其固定的 User-Agent ,因此只要知道这些浏览器或者知名爬虫的User-Agent 就可以伪装成该浏览器访问站点。但知名的爬虫一般都有固定的 IP,如搜索引擎的爬虫,不容易伪装。因此伪装浏览器的 User-Agent 是目前比较主流的伪装方法之一,因为浏览器下载后任何人都可以使用,没有固定的 IP 地址。但是当访问一个服务器过于频繁时,单一的 User-Agent 会被服务器识别为异常访问,此时需要不断的更换不同浏览器的 User-Agent 。
其中Cookie反爬技术又分为3种:
第一种是由服务器返回一个固定的 Cookie,想要获取数据携带上固定的 Cookie 即可。
第二种是 Cookie 会不断发生改变,当用户不断浏览新的页面时,便可能会在 Cookie 中记录用户浏览过的页面、用户搜索的关键字等。
第三种是通过前端的 JavaScript 操作Cookie 的变化并且可能会对某些数据进行加密,其实也就是Cookie 与 JavaScript 加密的结合产物。
网站为了辨别用户身份、进行session跟踪,当该cookies访问超过某一个阈值时就禁止掉该cookie/cookies,导致数据爬取失败。如果登录用户cookie/cookies信息在固定周期内失效(时效性),那就要找到登录接口,重新模拟登录,存储cookie/cookies,再重新发起数据请求,不断循环此步骤。
Refer 代表的意思是这个页面是从哪里跳转过来的,如从 www.baidu.com 跳转到 https://www.sina.com.cn/,Refer 就是 www.baidu.com。百度统计网站流量来源时就是依靠这个字段。有些站点在收到爬虫的访问请求时候会做识别,不是要求内的 Refer 则不能访问该页面,Refer 输入错误也会导致无法访问该页面。一般来说,使用目标站点的首页地址作为 Refer 就可以了。
6.1.2并发限制——IP限制


爬虫与人类在访问特征上最大的区别在于,人类对网站的访问会在较短时间里完成并收敛于某个时刻,而爬虫对网站的周期访问量是线性递增的。
一种基于访问数量的反爬虫策略:监控单个IP的访问量与时间的关系,对于一个较短周期的访问设置比较宽的阈值,而随着时间长度的增加而逐步收紧该阈值,当一个IP在周期内访问量达到阈值时,将其判定为爬虫并禁止访问。可考虑使用设置爬虫爬取频率、分布式爬取或者购买代理IP设置代理池的方式解决。
6.1.3 验证码限制
验证码是基于人能从图片中识别出文字和数字而机器却不能的原理产生的,是网站最常用来验证是爬取机器人还是普通用户在浏览的方式之一。
从最初的数字字母验证码到中文验证码、再到图像验证码,网络安全技术人员不断地与爬虫技术作斗争,验证码技术的发展史就是爬虫技术和反爬虫技术的博弈史。目前滑动拼图验证则是验证码的升级版,要求必须滑动拼图到指定位置才能通过验证进行下一步操作。复杂验证码,无法通过识图识别,可以考虑使用第三方收费服务或通过机器学习让爬虫自动识别复杂验证码,识别后程序自动输入验证码继续数据爬取。
6.1.4 数据加密
有些网站把ajax请求的所有参数全部加密,根本没办法构造所需要的数据请求。有的网站反爬虫策略更复杂,还把一些基本的功能都封装了,全部都是在调用网站自己的接口,且接口参数也是加密的。
网页动态加载技术 Ajax 全称为 Asynchronous JavaScriptand XML,直译为“异步的 JavaScript 与 XML 技术”,是一种创建交互式网页应用的网页开发技术,用于创建快速动态网页,由杰西·詹姆士·贾瑞特提出。与传统的 Web 应用相比,Ajax 通过浏览器与服务器进行少量的数据交换就可以实现网页的异步更新,在不重新加载整个网页的情况下,即可对网页进行更新。
用异步加载技术来应对爬虫相当有效。因为爬虫所抓取的都是一个网站起始的HTML代码,而不是异步刷新后的代码,所以网站设计者可以将网站中受保护的部分使用AJAX技术异步加载到HTML中,这样,既不会影响到人类用户的正常访问,也让网络爬虫无法抓取到受保护的内容。
遇到这样的网站,常使用模拟浏览器行为和抓包来截获网站数据。
可以考虑用selenium+phantomJS框架,调用浏览器内核,并利用phantomJS执行js模拟人为操作,触发页面中的js脚本。
6.2 前端限制
前端通常利用“CSS或HTML标签”“自定义字体”“元素错位”和“隐藏元素”等干扰混淆关键数据的反爬策略,保护数据安全。
6.2.1 自定义字体
某些网站在源码上的字体不是正常字体编码, 而是自定义的一种字体, 调用自定义的TTF文件来渲染网页中的文字,真实内容通过一种对应关系最终在页面上展示,而不在网页源代码中展示,通过复制或者简单的采集无法爬取到真实的数据。
反爬虫在源代码中隐藏了真正的字体,但最终如果要在页面上展示还是需要导入字体包,找到字体文件,下载后使用font解析模块包对TTF文件进行解析,解析出一个字体编码集合,与模块包里的文字编码进行映射,再反推转换对应关系即可获得真实正确的内容。
6.2.2 元素错位
不管是爬虫还是自动化测试,元素定位是爬虫最基本而且必需的一个步骤,如用BeautifulSoup find定位, BeautifulSoupcss定位、 selenium定位等。“元素错位”反爬虫策略是指网站维护人员利用伪装或错位一些关键信息的定位,让爬虫爬不到真实正确的内容。
通常先用上述各种方法找到样式文件,根据backgroudpostion值和图片数字进行映射,然后根据HTML标签里class名称,匹配出CSS里对应class中content的内容进行替换。
6.2.3 隐藏元素
用隐含字段阻止网络数据采集的方式主要有两种。第一种是表单页面上的一个字段可以用服务器生成的随机变量表示。如果提交时这个值不在表单处理页面上,服务器就认为这个提交不是从原始表单页面上提交的,而是由一个网络机器人提交。另一种是通过隐藏伪装元素保护重要数据,在重要数据的标签里加入一些干扰性标签,干扰数据的获取。
绕开第一种表单交验的方式最佳方法为先采集表单所在页面上生成的随机变量,然后再提交到表单,处理页面第二种情况则需要过滤掉干扰混淆的HTML标签,或者只读取有效数据的HTML标签的内容。
7.法律与道德约束
1.在做那些可能要承担法律责任的网络数据采集项目之前,你还是应该咨询一下律师,而不是软件工程师。
2.远离那些受保护的计算机,不要接入没有授权的计算机(或网站服务器),尤其是避开政府或财务计算机。
3.如果满足下列三个条件,网络爬虫就属于侵犯动产:
|
4.注意查看robots.txt和服务协议
5.“爬虫学的好,牢饭吃到饱”
《反不正当竞争法》视角下爬虫协议规制的现实困境与出路探寻.pdf-互联网文档类资源-CSDN下载
补充:
第一次补充——字符的编码方式
刚开始知道这几个名词就行了,常见的网页编码方式:
Unicode——符号集 https://home.unicode.org/
ASCII——英文字符、阿拉伯数字等编码
GBK、GB2312、GB18030——中文编码,前两个中文简体编码、后一个中文繁体编码
汉字对应表 http://www.chi2ko.com/tool/CJK.htm
UTF-8——UTF-8 是 Unicode 的实现方式之一,是在互联网上使用最广的一种 Unicode 的实现方式
后期研究可以参考另一个博主的总结:常见的几种编码方式_byf0521hlyp的博客-CSDN博客_编码方式
















 302
302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











