









| 实验 目的 要求 | 目的:
|
|
实 验 环 境
|
|
练习内容
任务一:MapReduce词频统计编程实例;
1、创建MapReduce项目;

2、修改pom.xml依赖文件

3、导入Hadoop配置文件
4、关键代码说明
4.1、map函数的方法

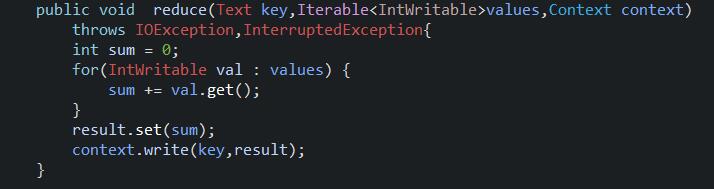
4.2、reduce函数的方法
4.3、main函数的调用(创建job类)

4.4、main函数的调用(设置job的输入输出路径并提交集群)

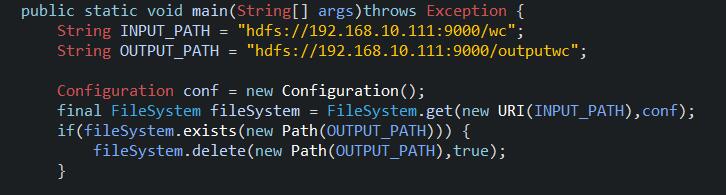
4.5、main函数的调用(定义输入输出路径)
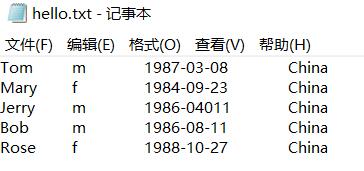
5、编写并上传hello.txt文件至Hadoop hdfs系统

6、将项目打包成jar包并上传至Hadoop中;


7、运行jar包,并显示运行结果;


8、Web端Hadoop平台任务展示


任务二:MapReduce排序的代码实现
1、关键代码说明
1.1、map函数的方法;
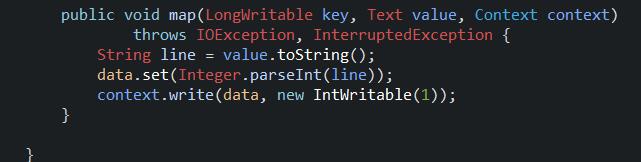
1.2、reduce函数的方法;
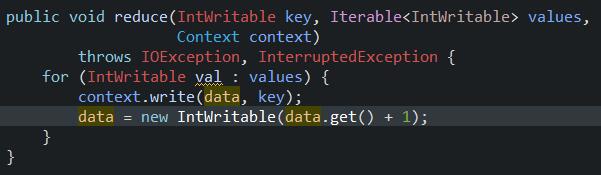
1.3、main函数的调用(创建job类)

1.4、main函数的调用(设置job类的输入输出路径)
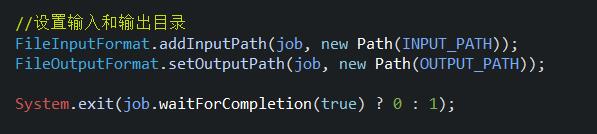
1.5、main函数的调用(定义输入输出路径)

2、将项目打包成jar包,并上传至Hadoop集群中;


3、上传测试文件;


4、执行程序并展示结果;


5、Web端验证;


任务三:MapReduce二次排序的实现原理
1、关键代码的实现;
1.1、map函数的方法;

1.2、Reduce函数的方法;
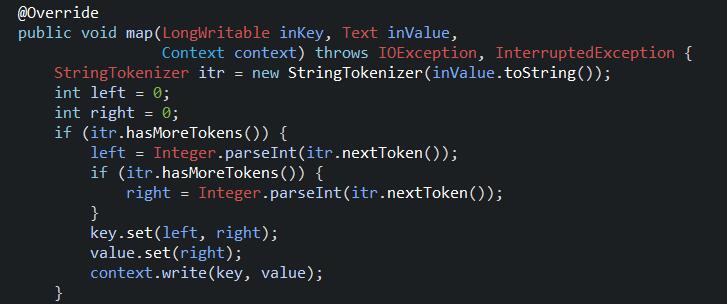
1.3、main函数的调用(创建job类)

1.4、main函数的调用(设置job类输入输出路径)
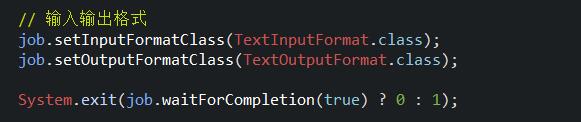
1.5、main函数的调用(定义输入输出路径)
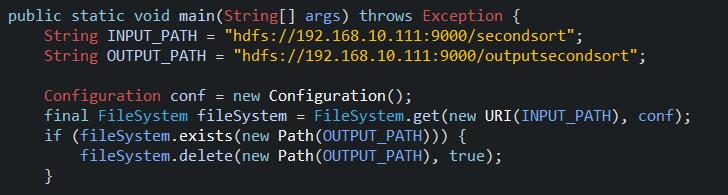
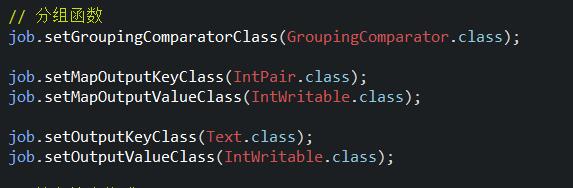
1.6、main函数的调用(调用分组函数)
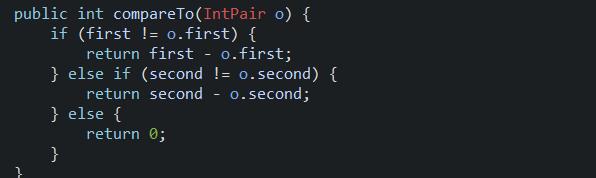
1.7、排序函数的实现;
2、将项目打包成jar包,并上传至Hadoop集群中;


3、上传测试文件;

4、执行程序并展示结果;


出现的问题与解决方案
排错一:
错误:关于MapReduce,Map能完全执行,Reduce执行到一半卡住不执行
排错思路:
卡住了几个小时,死活停滞不前,发现后根据提示开始排错,进入50030,进入作业发现
这说明作业在map之完后的shuffle阶段中,reduce无法从map处拷贝数据,是因为客户端与数据节点通讯失败造成的。客户端程序应该能够和所有的节点通讯才能保证数据的传输正常,然后开始各种检查:所有节点hosts中写的完全相通,不是节点名称不同或者节点没有完全加上造成的,排除;找到slaves发现写的也完全相同,不是节点缺失有误,最后查看了防火墙的状态,发现其中一个节点的防火墙没有关闭,找到原因,service iptables stop,然后重新提交作业,成功运行
排错二:
错误:Map或Reduce任务中的某些代码抛出异常,此时Hadoop强行停止java虚拟机,并向JobTracker汇报,JobTracker将任务标记为失败显示给用户,同时写入日志目录
排错思路:
设置重试次数以及等待一定次数后对异常记录跳过检测:
conf.setInt("Mapred.Map.max.attempts",2); //设置尝试次数,超过则失败
conf.setInt("Mapred.skip.attempts.to.start.skipping",1); //开始“跳过”模式,读取失败超过则开启“skip mode”
conf.setInt("Mapred.skip.Map.max.skip.reords",1); //设置最大跳过记录数;
解决:不是所有的异常都会导致任务失败,也有可能因为网络或者硬件或其他原因导致运行过慢,此时Haodop会自动在另外一个节点上启动同一个任务作为任务执行的一个备份。
排错三:
错误:JAVA虚拟机重用。
原因:Hadoop为每个任务启动一个新的虚拟机,若java虚拟机开启过多(任务被划分得过于细粒度),资源损耗会过大。
解决:“Java虚拟机重用模式”,类似线程池与连接池的原理。将细粒度的任务变成串行执行。多个java虚拟机被同时启动,执行完一个任务后,并不直接关闭,而是被加载新的任务重新执行。同时执行的java虚拟机数目可设定,默认1,(不适合重用);默认-1,所有任务都用同一个java虚拟机。















 1184
1184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









