









| 实验 目的 要求 |
目的:
| ||||||||||||
|
实 验 环 境
|
|
练习内容
任务一:Hive DDL的使用;
1、使用命令“hive”启动hive,进入Hive控制台;

2、创建内部表;

3、创建外部表;

4、创建分区表

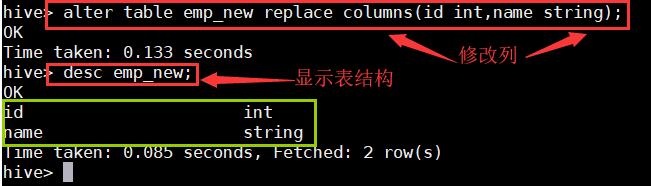
5、使用hive DDL命令进行一些简单的操作;


任务二:Hive DML的使用;
1、创建文本并写入数据;

2、进行DML操作;

3、创建hdfs用于存放文件的位置,并查看是否创建成功;

4、上传数据文件至hdfs;

5、查看上传的文件内容;

6、对上传的数据文件进行基本操作;

7、将查询结果插入hive表中;

8、导出hive的表数据;

9、查看导出的数据;

任务三:Hive内置函数的基本操作;
1、获取所有函数;

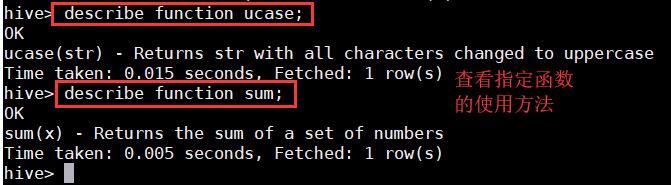
2、查看指定函数的使用方法;
3、进行表操作;

4、查看concat的使用方法;

5、连接ename,job字段;

任务四:Hive UDF开发;
1、创建maven工程项目Hive;
1.1、创建项目;

1.2、修改pom.xml文件,添加指定依赖;

2、Hive UDF开发;
2.1、编写HelloUDF.Java文件;

2.2、导出项目为jar包;

2.3、上传jar包至集群中;

3、编辑jar包上传至服务器,并将自定义函数UDF添加到Hive中;

4、查看自定义函数中是否有以上传的;

5、使用自定义函数进行查询操作;

任务五:调优策略;
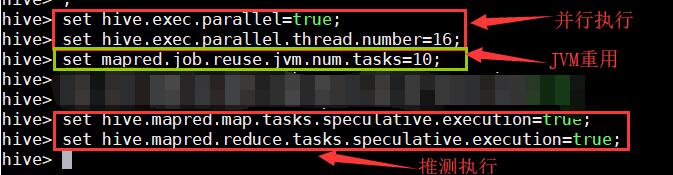
1、并行执行及JVM重用;
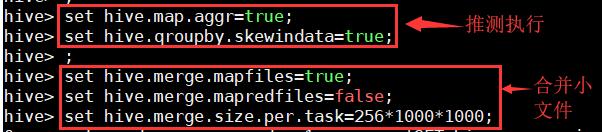
2、推测执行,合并小文件;
出现的问题与解决方案
排错一:
错误:装载hdfs至hive失败

排错思路:
- 查看指定目录是否正确;
- 查看指定文件是否正确;
- 查看命令应用是否正确;
原因分析:之前在上传数据文件至hdfs时,系统默认删除了源文件
解决方案:重新编写数据文件再次上传;

排错二:
错误:运行自定义函数失败;

排错思路:
- 检查jar包是否合适;
- 检查环境是否合适;
- 检自定义函数是否正确
原因分析:开发环境开发自定义函数时在jdk1.8环境,而Hadoop集群环境中使用的是jdk1.7环境,jar包jdk版本过高;


解决方案:更改maven项开发环境为jdk1.7版本,重新打包项目为jar包上传至hdfs中使用;
知识拓展
1. Hive介绍
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
2. Hive架构
用户接口,包括 CLI,JDBC/ODBC,WebUI
元数据存储,通常是存储在关系数据库如 mysql, derby 中
解释器、编译器、优化器、执行器
Hadoop:用 HDFS 进行存储,利用 MapReduce 进行计算
Ps:hive的元数据并不存放在hdfs上,而是存储在数据库中(metastore),目前只支持 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
元数据就是描述数据的数据,而Hive的数据存储在Hadoop HDFS
数据还是原来的文本数据,但是现在有了个目录规划。
3. Hive与Hadoop的关系
Hive利用HDFS存储数据,利用MapReduce查询数据。
4. Hive安装部署
Hive只是一个工具,不需要集群配置。
export HIVE_HOME=/usr/local/hive-2.0.1
export PATH=PATH:
HIVE_HOME/bin
配置MySql,如果不进行配置,默认使用derby数据库,但是不好用,在哪个地方执行./hive命令,哪儿就会创建一个metastore_db
MySQL安装到其中某一个节点上即可。
5. Hive的thrift服务
可以安装在某一个节点,并发布成标准服务,在其他节点使用beeline方法。
启动方式,(假如是在master上):
启动为前台服务:bin/hiveserver2
启动为后台:nohup bin/hiveserver2 1>/var/log/hiveserver.log 2>/var/log/hiveserver.err &
连接方法:
hive/bin/beeline 回车,进入beeline的命令界面
输入命令连接hiveserver2
beeline> !connect jdbc:hive2://master:10000
beeline> !connect jdbc:hive2://localhost:10000
(master是hiveserver2所启动的那台主机名,端口默认是10000)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









