







目录
9.1 卷积-kernel_size,stride,zero_padding
9.2 Activation Function & Max pooling
9.1 卷积-kernel_size,stride,zero_padding
位置无关性,近邻关系,更少的参数
卷积通过查看相关位置而不是绝对位置来解决位置相关问题
9.2 Activation Function & Max pooling

Max pooling
用来减小activation map的尺寸,从而减小参数数量,也能达到消除图像小变化带来的影响的作用。通常对activation map进行最大池化à激活函数。如果将max pooling的参数stride设置为none,缺省将是下采样核的大小(即不重叠进行下采样)。
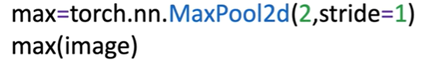
图9.2-1 pytorch中使用最大池化
9.3 多输入多输出通道

图9.3-1 多输出activation map

图9.3-2 多activation map
9.4 卷积神经网络-CNN
池化是在激活之后应用的


图9.4-1 卷积神经网络pytorch搭建
使用GPU资源
首先查看gpu是否可用:torch.cuda.is_available()
接着设置设备:device=torch.device(‘cuda:0’)
在训练前只需要将Model和input使用to方法传到device即可使用计算资源
Torchvision模型
使用pratrained模型时,如果需要冻结网络的前几层只替换网络的最后一层,需要遍历网络的前k层,将requires_grad参数设置为False;Optimizer只使用requires_grad为True的参数。

![]()

图9.4-2 使用pretrained模型进行自定义任务;保持训练好模型的前面层参数不变,只训练和任务相关的最后一层的参数
注:本文截图来自Coursera同名课程,感谢Coursera提供的在线学习资源!















 4427
4427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









