







Java中神奇的Unicode换行符(\u000d)
很有意思的一个技巧,使用这个技巧能绕过waf的内容检测。
public class Test {
public static void main(String[] args) {
String name = "张三";
//\u000dname="李四";
System.out.println(name);
}
}
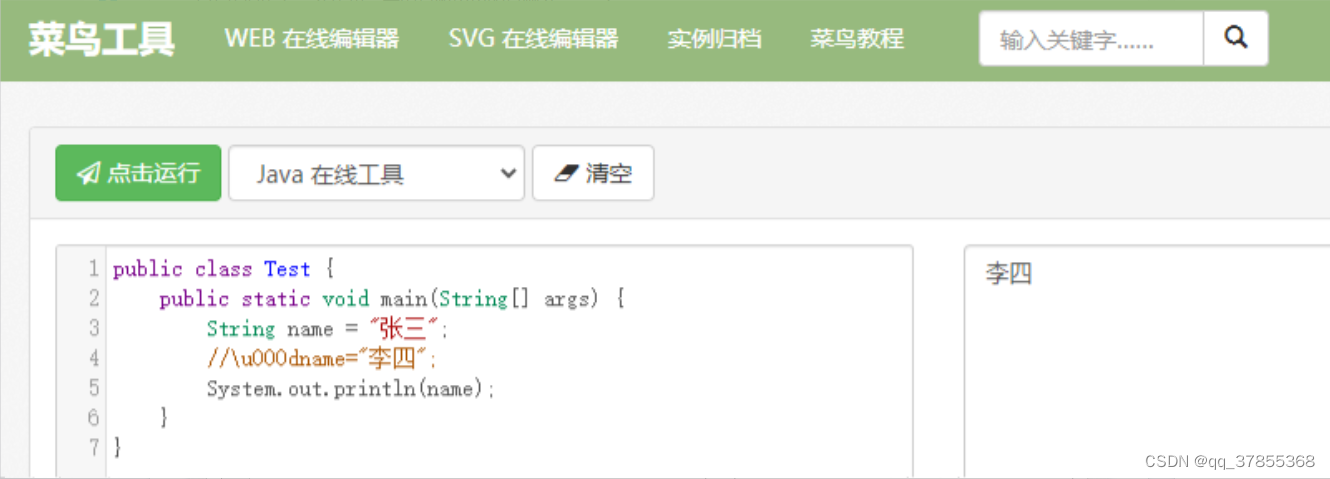
看到这个结果,是不是有点懵逼了?明明 name = 李四 被注释了为什么最终执行输出的还是 李四 这个变量?
我们单纯从代码上看,问题应该就是出在那串特殊字符上 \u000d,因为这代码里面没别的奇怪点了。\u000d看上去就知道是一个Unicode字符,转换十进制以后发现它代表一个换行符!!
那么这个时候答案就出来了,Java的编译器不仅会去编译代码, 也会去解析Unicode字符。
那么我们现在把那个代码修改为人看的懂的,首先\u000d==换行符,那么转换为代码就是。
public class Test {
public static void main(String[] args) {
String name = "张三";
//
name="李四";
System.out.println(name);
}
}
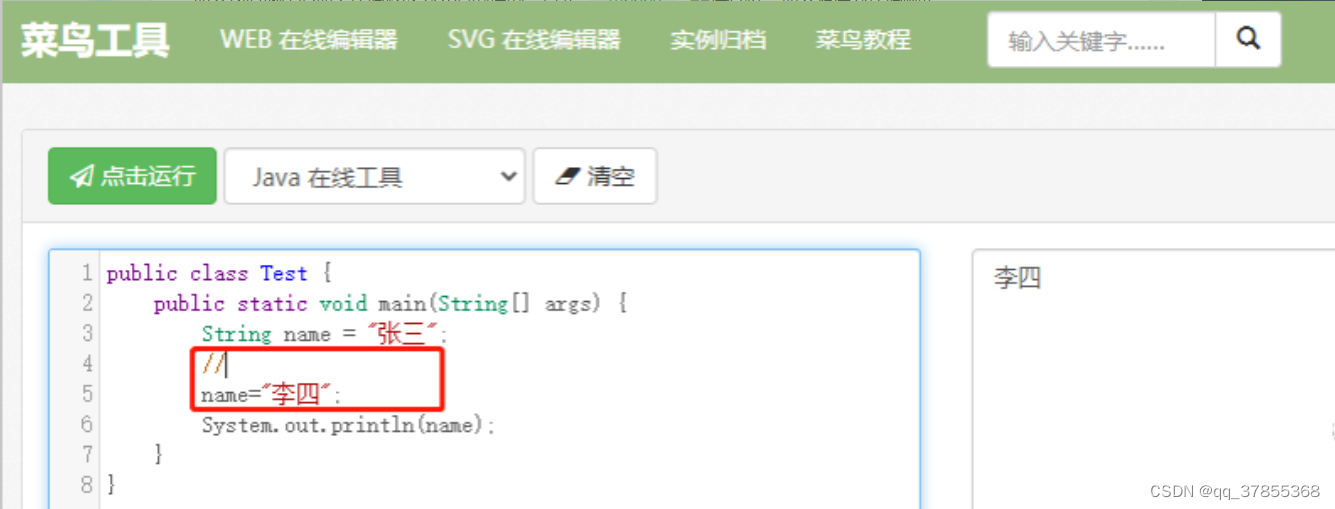
可以看的到\u000d被转换为换行符,把 name=“李四”; 挤到了 //(注释符) 的下一行,最终逃逸了 //(注释符) 影响了name的值。
那么这个东西可以拿来干嘛呢?很明显这个东西是用来绕waf的好玩意。例如:一个使用了Unicode字符混淆的写文件代码,执行完毕以后会在根目录生成一个t.txt文件,内容为:abcd。
public class Test {
public static void main(String[] args) {
try {
java.io.FileWriter f=new//\u000djava.\u000dio.\u000dFileWriter\u000d("t.txt");
f.//\u000dwrite//\u000d("abcd");
f.//\u000dclose//\u000d();
System.out.println("文件创建成功");
} catch (java.io.IOException e) {
e.printStackTrace();
}
}
}
- 该方法拿来绕内容检测的waf想比是非常不错的选择之一;
- Java的编译器不仅会去编译代码,也会去解析Unicode字符;















 521
521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









