







提示:纯小白,刚开始接触机器学习,目前也只是在网上找一些资料学习,权当学习笔记,有理解错误的地方,欢迎提出,我会及时更改。
文章目录
前言
提示:参考资料《Python机器学习手册-从数据预处理到深度学习》以及从网上查找的其他资料
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
一、向量、矩阵和数组
主要是对Numpy的一些操作,样例可参考:向量、矩阵和数组
二、加载数据
涉及机器学习,第一个步骤都是把原始数据加载到系统中。
从不同载体(比如CSV、SQL、JSON)中加载数据的方法,可参考样例:加载数据
三、数据整理
数据整理经常用于描述将原始数据转换成整洁的、组织合理的形式以供使用的过程,它是数据预处理中的一个重要步骤。
整理数据时,最常用的数据结构是数据帧data frame,数据帧呈表格状,用行和列来表示数据。
数据整理用的库主要是pandas,可参考样例:数据整理
四、处理数值型数据
1. 特征缩放
将原始数值数据转换成机器学习算法所需特征。
特征就是区分一个东西的地方,比如一个苹果的特征:红色、圆、甜、光滑、脆等等,这些我理解为一个事务的特征。
机器学习中特征缩放是一个很常见的预处理任务。很多算法都假设所有特征是在同一取值范围中的,最常见的范围是[0, 1]或[-1, 1]。
特征缩放的目的:把特征数据等比例放大或缩小,可以提高后面的模型算法训练效率。【待研究】
最简单的一种缩放方法:min-max缩放,将特征数据缩放到[0, 1]范围内。先计算特征的最小值和最大值,然后对所有特征进行缩放。

参考代码:特征缩放
2. 特征的标准化
特征标准化是特征缩放min-max缩放的一个常见的替代方案:将特征进行转换,使其平均值为0,标准差为1.
特征标准化计算公式:
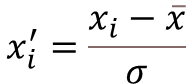
标准差
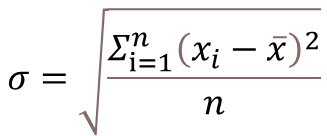
σ
\sigma
σ 计算公式:
针对特征中的异常值,可以使用中位数和四分位数间距进行缩放。【待研究】
特征标准化代码可以参考:特征标准化
3. 归一化观察值
归一化可以对单个观察值进行缩放,使其拥有一致的范数。当一个观察值有多个相等的特征时,经常使用这种类型的缩放。
欧式范数(L2范数)计算公式:

曼哈顿范数(L1范数)计算公式:
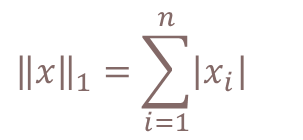
归一化观察值代码可参考:归一化观察值
4. 生成多项式和交互特征
当特征和目标值(预测值)之间存在非线性关系时,就需要创建多项式特征。
交互特征在我的理解中,就是一个特征依赖另一个特征,共同对目标作用生成效果。
多项式和交互特征代码可参考:生成多项式和交互特征
5. 转换特征
对特征值进行统一操作,一般是自定义一个函数,然后让每个特征值经过这个函数处理,得到自己想要的处理结果。
转换特征代码可参考:转换特征
6. 识别异常值
6.1 EllipticEnvelope
针对一个数据集,给这些数据画一个圈,在这个圈里面的视为正常值,在圈外边的视为异常值。
这个方法的一个主要限制是它需要指定一个污染指数参数,表示异常值在观察值中的比例,但是这个比例我们也不知道,只能自己根据数据进行估计,觉得异常值比较少,污染指数设置小一点;觉得异常值比较多,污染指数设置大一些。
6.2 四分位差
之查看某些特征,使用四分位差(interqutile range, IQR)来识别这些特征的极端值。
IQR是数据集的第1个四分位数和第3个四分位数之差。可以将IQR视为数据集中大部分数据的延展距离,而异常值会远远地偏离数据较为集中的区域。异常值常常被定义为比第1个四分位数小1.5IQR的值,或比第3个四分位数大1.5IQR的值。
参考代码:识别异常值
7. 异常值处理
通常有三种方式来处理异常值:
7.1 丢弃异常值
7.2 标记异常值,并作为数据的一个特征值
7.3 异常值特征转换,降低异常值的影响
在处理异常值时,不存在绝对准则,应该考虑异常值的来源是什么,如果是真的不需要的异常值,可以直接丢弃,如果确实存在异常场景,那就要考虑将该异常标记出来或进行特征转换了。
参考代码:异常值处理
8. 将特征离散化
将一个数值型特征离散化,分到多个离散的小区间中。
8.1 根据阈值将特征二值化
8.2 根据多个阈值将数值型特征离散化
参考代码: 将特征离散化
9. 使用聚类的方式将观察值分组
对观察值进行聚类操作,使相似的观察值被分为一组。
参考代码:使用聚类的方式将观察值分组
10. 删除带有缺失值的观察值
大多数机器学习算法不允许目标值或特征数组中存在缺失值,所以有必要在数据预处理阶段解决这个问题。
参考代码:删除带有缺失值的观察值
11. 填充缺失值
数据中存在缺失值,希望填充或预测这些值。
填充缺失值主要有两种策略:
策略一:使用机器学习来预测缺失值,最流行的选择是KNN。
不足:只适合小数据集,对大数据集,计算量会成为一个很严重的问题。
策略二:用平均值来填充缺失值。
不足:效果没有KNN好,但平均值填充策略很容易扩展到包含成千上万观察值的大数据集。
参考代码:填充缺失值
总结
本文中对机器学习的一些基础概念和基础操作做了总结,每一步每一种情况都给了代码样例,代码实现只是表面,重要的是了解和学习机器学习的思想。一步一步来吧!














 1854
1854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









