







前言
接触过Requests + BeautifulSoup之后,Scrapy是我接触的第一个爬虫框架。以下是我的一些理解总结。
参考文档: 爬虫官方文档
一、Scrapy简介
Scrapy是一套基于Twisted的异步处理应用程序框架,用于抓取网站和提取结构化数据,这些数据可用于广泛的应用程序,如数据挖掘、信息处理或历史存档。
二、Scrapy环境安装
windows上安装scrapy环境命令: pip install Scrapy
验证scrapy是否安装成功

我是在虚拟环境中安装的,pip安装scrapy之后可以直接在虚拟环境中使用scrapy创建爬虫项目。但我不在虚拟环境中使用scrapy有时会遇到提示scrapy 不是内部或外部命令或者scrapy命令找不到类似的报错,这是为什么呢?可以查看venv/Scripts目录,发现有一个scrapy.exe二进制文件,安装scrapy的时候会自动在虚拟环境的Scripts目录下生成这个文件,相当于scrapy.exe命令已经在虚拟环境变量中了,所以能直接使用。

而不能使用scrapy命令的情况,可能是下载到真实环境中了,需要把scrapy.exe所在目录配置到环境变量中才可以使用。如果在linux上安装之后,查看环境变量中的scrapy文件,其实就是一个python文件,根据传参的不同做不同的操作。
查看scrapy可以传递哪些参数:

| 参数名称 | 参数含义 | 例子 |
|---|---|---|
| bench | 只是一个测试例子,安装好之后可以使用该命令测试下爬虫项目能不能用 | scrapy bench |
| fetch | 使用该爬虫项目爬取一个连接 | scrapy fetch https://www.xxx.com |
| genspider | 生成一个爬虫 | scrapy gensipder scrapy1 |
| runspider | 运行一个爬虫 | scrapy runsipder scrapy1 |
| settings | 获取爬虫配置 | scrapy settings --get "ROBOTSTXT_OBEY" |
| shell | 配置加载后会打开一个交互式shell,可以查看一些信息 | scrapy shell |
| startproject | 创建一个爬虫项目 | scrapy startproject scrapy_demo |
| version | 查看爬虫版本 | scrapy version |
| view | 会在浏览器中打开指定的url,同时也会爬取信息 | scrapy view https://www.xxxx.com |
当创建项目之后,在项目目录下运行scrapy -help还可以看到更多其他参数。
三、爬虫原理简述
爬虫原理图网上也很多了,自己重新梳理一遍如下:

上图中的几个实体:
Scrapy引擎:协调Spider/ItemPipeline/Downloader/Scheduler之间的工作。
Item Pipeline: 负责处理Spider中获取到的item,并进行后期处理(详细分析、过滤、存储等)的地方。就是爬虫要保存什么内容可以在这个模块控制。
Scheduler: 负责接收引擎发送过来的request请求,并按照一定的方式进行整理排列,入队(去重)。当引擎需要时,交还给引擎。
Downloader: 下载器,负责下载scrapy engine发送的所有Requests请求,并将其获取到的Responses交还给scrapy engine,由引擎交给Spider来处理。
Spiders: 负责处理所有Responses从中分析提取数据,获取Item字段需要的数据,这些Item最终会交付给 Item Pipeline;并将需要跟进的URL提交给引擎,再次进入Scheduler。
Downloader Middlewares: 下载中间件,自定义扩展下载功能的组件。比如之后可能接触到的Selenium中间件、代理中间件都会写到这个模块中。
Spider Middlewares: Spider中间件,自定义扩展和操作引擎和Spider中间通信的功能组件。
那爬虫的起始URL会从哪个模块开始?会从Spiders开始。
- Spiders构造url的请求,引擎把这个请求转发给Scheduler模块
- Scheduler做做去重操作什么的,又返回给引擎,引擎把处理后的请求传递给Downloader模块
- Downloader模块会按照下载器中间件的操作(比如携带Cookie获取资源、配置代理获取资源、使用Selenium模拟浏览器获取响应等)获取资源响应,然后将响应内容又经过scrapy引擎的调度传递给了Spider
- Spider做响应解析,该保存的数据传递给Item Pipeline,响应中的新的url构造成新的请求又被引擎传递给Scheduler
- 周而复始,直至所有的连接爬取完成。
四、新建一个简单爬虫项目
制作一个爬虫总共需要四步
- 新建项目:scrapy startproject xxxxxx
- 明确目标: items.py, 明确需要抓取的目标
- 制作爬虫: spiders/xxxspider.py,制作爬虫开始爬取网页
- 存储内容:pipelines.py,设计管道存储爬取内容
以下开始写爬虫例子。
4.1 新建项目
scrapy startproject scrapy_demo

查看下新建的爬虫项目目录结构:
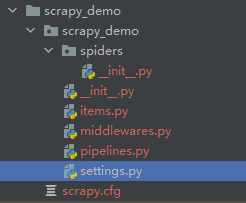
项目中文件作用:
scrapy.cfg文件: 项目配置文件,有项目名称,默认项目配置

spiders目录:这个目录下放置项目的爬虫,一个项目可以不止一个爬虫,有几个爬虫,在spiders目录下就建几个爬虫文件。
items.py文件:保存响应哪些信息就是在这个文件里处理的。相当于数据清洗。

middlewares.py文件:中间件是在这个文件里写的。这里面的方法几乎都是固定的,我们只需要重写部分函数就行了,后面会再详细了解总结。

pipelines.py文件:清洗后的数据保存是在这个文件里操作的。比如写到文件中、数据库里。

settings.py文件:爬虫项目的配置文件,这个文件非常重要,启用哪些中间件、遵守robots协议、并发请求数、下载延时等都是在settings.py中配置的。后面会专门对settings.py中的参数做总结。

4.2 创建爬虫
scrapy genspider spider1 https://www.xxx.com

会在spiders目录下生成一个爬虫文件,内容如下:

name就是生成的爬虫的名称。
allowed_domains是允许爬取的域名范围。
start_urls是爬虫开启的第一个url地址。
parse()函数是爬虫发起请求后,响应都会经过这个爬虫的parse函数,相当于做一个回调函数。
4.3 运行爬虫
scrapy crawl spider1
运行爬虫spider1之后的部分日志如下:

总结
1、了解了爬虫的基本概念和基本原理。
2、安装scrapy包和使用scrapy命令行工具。
3、使用scrapy命令行工具新建一个爬虫项目和爬虫,并运行爬虫。
4、还需探索~
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









