







文章目录
一、五种数据类型
1.1 字符串
字符串value最大长度是512M。
字符串操作常用命令:
set a hello : 创建变量a,赋值为hello
get a : 查看变量a
getset a world : 先查看a的值,再给a赋值为world

del a : 删除变量a
incr num: 如果num不存在,创建变量num,默认值是0,并增加1,所以num的值是1.如果一个变量的值不是数字,不能使用incr。

decr num: 如果num不存在,创建变量num,默认值是0,并减1,所以num的值是-1.

incrby num 5: 如果num不存在,创建变量num,默认值是0,增加5,所以num的值是5。如果num存在,就在num的基础上加5.

decrby num 3: 如果num不存在,创建变量num,默认值是0,减3,所以num的值是-3。如果num存在,就在num的基础上减3。

append num 5: 在num变量值后面追加5,相当于字符串拼接了。

1.2 列表
列表常用于消息队列的一些服务。redis中的列表就像是一个栈,先进入的元素是在列表的尾部,后进入的元素是在列表的首部。
lpush list1 a b c : 向列表list1中插入元素a, b, c。先插入的元素在列表的尾部,如下图所示:

lpush list1 1 2 3 : 向列表list1中插入元素1, 2, 3
rpush list2 a b c: 像列表list2中插入元素a, b, c。先插入的元素在列表的首部,如下图所示:
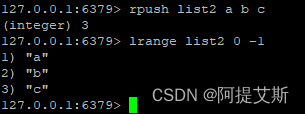
rpush list2 1 2 3: 向列表list2中插入元素1, 2, 3
lrange list1 0 5 : 查看列表list1的[0-5]位置的元素
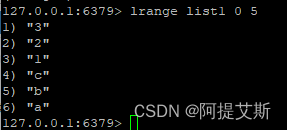
lrange list1 0 -1: 查看列表list1的所有元素。
lpop list1: 弹出列表list1头部元素。

rpop list1: 弹出列表list1的尾部元素

llen list1: 计算list1的长度

lpushx list1 x : 只有当list1存在的时候,才会把x存入到列表list1中。如果list1不存在就会出现下图所示的情况,x并没有插入到指定的列表里:

rpushx list2 x : 只有当list2存在的时候,才会把x存入到列表list2中。
lrem list1 2 a: 从左向右,删除list1中2个a元素。
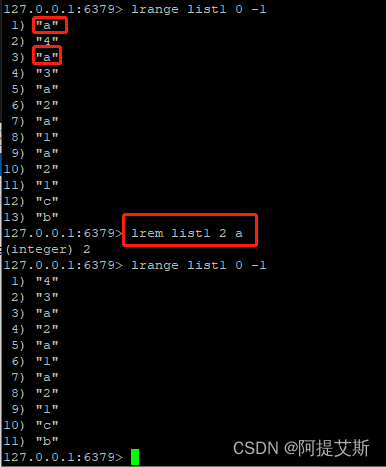
lrem list1 -2 a : 从右向左,删除list1中2个a元素。

lrem list1 0 a : 删除list1中的所有a元素。

lset list1 3 fff : 设置list1坐标为3的位置元素值为fff。
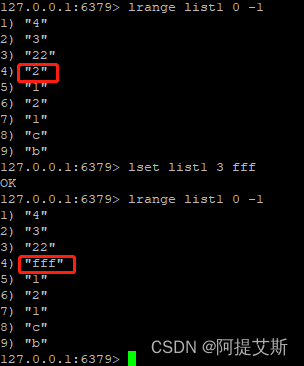
linsert list1 before a 22 : 在列表list1的第一个a元素之前插入一个元素22.
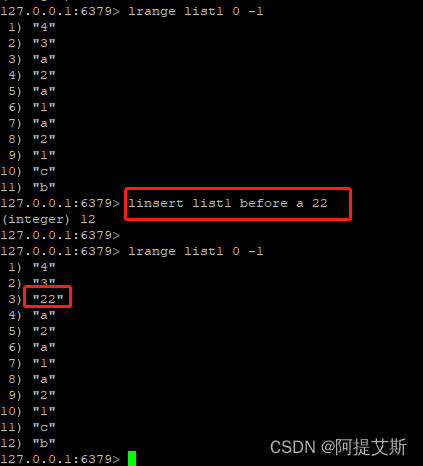
linsert list1 after 1 33: 在列表list1的第一个1元素之后插入一个元素33。
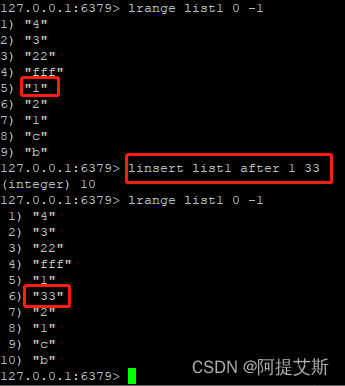
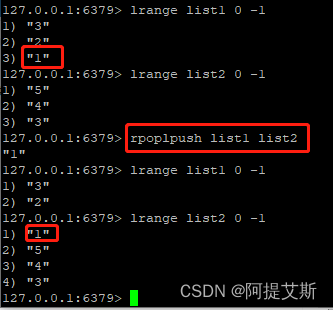
rpoplpush list1 list2 : 将list1最后一个元素弹出,插入到list2的首部。该命令可防止消息丢失。
1.3 有序字符串集合
Sorted-Set(zset)中每个元素都有一个相对应的分数,Sorted-Set就是根据元素的分数进行排序的。
Sorted-Set主要应用在排名、热搜等场景。
zadd sortset1 70 zs 80 ls 90 ww:创建或更新有序集合sortset1,添加或更新的三个元素是zs, ls, ww,对应的分值分别为70, 80, 90。
zscore sortset1 zs: 获取zs的分数。
zcard sortset1: 获取sortset1的元素数量。
zrem sortset1 zs: 删除元素zs。
zrange sortset1 0 -1: 获取sortset1中的元素。
zrange sortset1 0 -1 withscores: 获取sortset1中的元素和分数。从小到大。
zrevrange sortset1 0 -1 withscores :获取sortset1中的元素和分数。从大到小。
zremrangebyrank sortset1 0 4: 按照范围删除集合中的[0, 4)元素。
zremrangebyscore sortset1 80 100: 删除分数在[80, 100]之间的元素。
zrangebyscore sortset1 0 100: 获取分数在[0, 100]之间的元素。

zrangebyscore sortset1 0 100 withscores: 携带分数显示[0, 100]之间的元素。

zrangebyscore sortset1 0 100 withscores limit 0 2 : 携带分数显示[0, 100]之间的元素,只显示[0, 2)两个元素。
zincrby sortset1 3 ls: 给有序集合sortset1中的ls元素的分数增加3.
zcount sortset1 80 90: 获取分数在[80, 90]之间的元素的个数。
1.4 哈希
存储Hash,String Key和String Value的map容器。每一个Hash可以存储4294967295个键值对
哈希常用的命令:
hset person1 username bob 创建person1对象,属性为username,值为bob。
hset person1 age 18: person1对象添加属性age,值为18
hmset person2 username David age 20: 创建person2对象,添加属性username,值为David,添加属性age,值为20.
hget person1 username: 获取person1对象的username属性值。(获取单个属性值)
hmget person1 username age: 获取person1对象的username和age属性值。(获取多个属性值)
hgetall person1: 获取person1的所有属性和值。

hdel person2 username age: 删除person2对象的username 和 age属性。
del person2: 删除person2对象
hincrby person1 age 5 : person1对象的age属性增加5.

hexists person1 username: 判断person1对象的username是否存在,存在返回1,不存在返回0。

hlen person1: 获取属性个数

hkeys person1: 获取所有属性名称
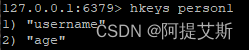
hvals person1: 获取所有值

1.5 字符串集合
Set集合中不允许出现重复的元素。
Set可包含的最大元素数量是4294967295.
常应用于数据的唯一性场景、维护数据对象之间的关联关系(差、交、并)。
sadd set1 a b c: 向集合set1中添加a, b,c
srem set1 a: 删除set1集合中的a元素
smembers set1: 查看set1中的元素

sismember set1 a: 判断set1中是否有元素a,返回1表示含有该元素,0表示不包含该元素。
sdiff set1 set2: 求差集,获取set1集合中有,set2集合中没有的元素。
sinter set1 set2: 求交集,获取set1集合和set2集合中共有的元素。
sunion set1 set2: 求并集,将set1集合和set2集合元素合并到一起。
scard set1: 获取到set1集合的数量
srandmember set1: 从set1集合中随机返回一个元素
sdiffstore set_diff set1 set2: 将set1集合和set2集合的差集保存到set_diff 集合中。
sinterstore set_inter set1 set2: 将set1集合和set2集合的交集保存到set_inter 集合中。
sunionstore set_union set1 set2: 将set1集合和set2集合的并集保存到set_union集合中。
key定义的注意点:
不要过长:消耗内存
不要过短:降低可读性
统一的命名规范
二、其他命令
keys *: 获取所有的keys
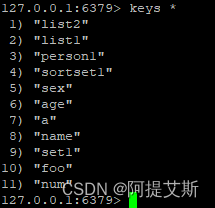
keys set?: 获取set开头的key,注意?只能匹配一个字符,所以可以匹配到set1,却匹配不到set11。

exists xxx : 判断key xxx是否存在.
rename xxx yyy: 重命名key xxx为yyy.
expire yyy 1000: 设置key yyy的过期时间为1000秒。
ttl yyy: 查看所剩余时间。如果key yyy没有设置时间,会返回-1.
type yyy: 查看key yyy类型:string、set、zset、list、hash.
flushall: 清空数据库中的所有key。
三、redis的特性
3.1 多数据库
一个redis实例最多可提供16个数据库。下标为0-15,数据库默认连接的是0号数据库。
select 1: 通过select命令选择1号数据库。
move sortset1 1: 移动当前数据库的sortset1到1号数据库中。
3.2 事务
事务可以参考mysql数据库中的事务。
multi : 开启事务,后面的命令都被认为是事务相关的操作。
exec: 相当于提交。如下图所示是一个事务提交的例子:

discard: 相当于回滚。开启事务后,未执行exec提交时,可以discard回滚上一步操作。如下图所示是一个事务回滚的例子:

四、redis持久化
redis快是因为在内存中操作数据,如果停电了,或机器重启了,内存中的数据就没了,所以持久化是有必要的。
4.1 RDB方式
在指定的时间间隔后,将内存中的数据集快照写入磁盘。
优势:
- 相比AOF,启动效率更高。
- 恢复更容易,只是一个rdb文件。
缺势:
- 如果宕机,数据还没有来的及写到硬盘,那么数据就丢失了。
配置:redis.conf文件中进行配置。
下图所示配置含义,每900秒有一个key发生变化,就进行保存;每300秒有10个key发生变化就进行保存;每60秒有10000个key发生变化,就进行保存。

保存rdb文件的文件名为dump.rdb,保存到当前目录的data目录下。

4.2 AOF方式
以日志形式记录服务器处理数据的每一个操作。redis服务起来之后,会读取日志重新构建数据库,保证启动后数据库中的数据是完整的。
优势:
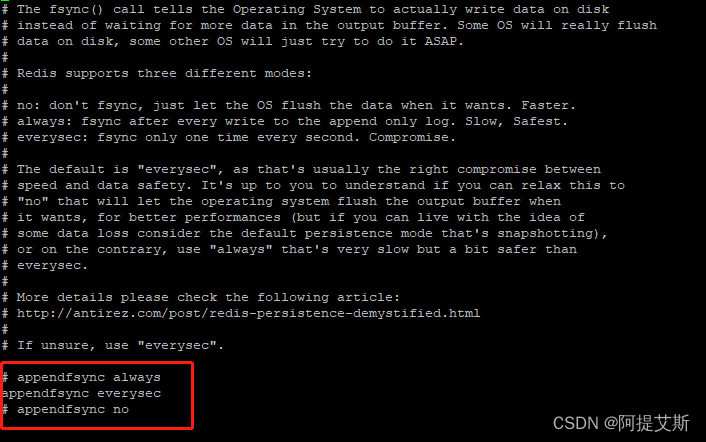
- 更高的数据安全性:每秒同步【异步】、每修改同步、不同步。
- 日志使用的append进行日志追加,就算写的过程中发生了宕机,历史数据还在。
- 如果日志过大,redis有重写机制,会把日志写到老的磁盘文件中。
- 日志记录结构非常清晰。
劣势:
- 相同的数据集,相比RDB,保存文件要大写
- 相比RDB,运行效率低
配置:redis.conf文件中进行配置。
如下图所示,默认AOF功能没有打开,如果要打开设置appendonly为yes,默认生成的aof文件为appendonly.aof
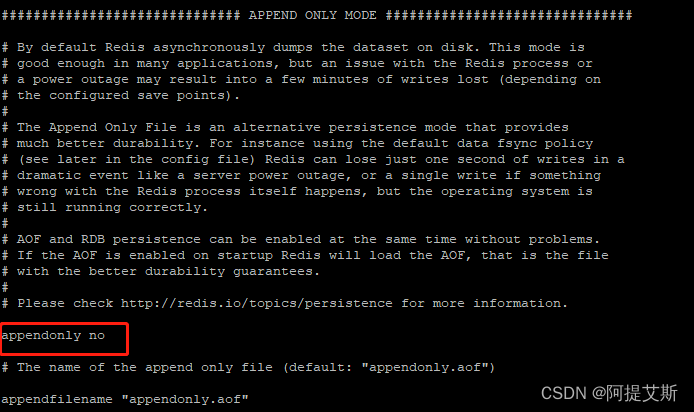
aof的三种同步策略。
看下aof文件中的内容:

4.3 无持久化
这种方式就只是使用redis的缓存功能。
4.4 共用RDB和AOF
可以同时使用RDB和AOF两种方式进行数据持久化。















 886
886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









