







实验目的
1、掌握数据挖掘中数据预处理的方法;
2、了解数据转换的过程和方法;
3、了解描述性数据汇总的计算机实现方法。
1、理解分类的一般过程和基本原理;
2、巩固分类算法的算法思想,能够进行分类操作;
3、学会分类预测问题中的性能评估方法。
实验原理
现实世界中的数据库极易受噪音数据、遗漏数据和不一致性数据的侵扰,为提高数据质量进而提高挖掘结果的质量,产生了大量数据预处理技术。数据预处理有许多方法:
(1) 数据清理: 数据清理是完成格式的标准化、对空缺值进行处理、清除重复的数据以及对异常数据进行错误纠正和清除等操作;
(2) 数据集成: 数据集成是将来自不同数据源的数据合并为统一一致的数据存储中, 这种数据存储可以是数据库或数据仓库;数据集成主要包括:包含相同字段属性的纵向追加和具有相关属性叠加的横向合并。
(3) 数据归约: 数据归约是针对原始数据集中地属性和记录, 实现有效的数据采样与对应属性选择, 进一步降低数据规模, 在数据归约过程可以采用聚集、聚类以及将冗余特征值删除等形式, 达到既能最大限度的保持数据的原有特征, 又能够有效的精简数据量的目的。数据归约主要通过数据立方体技术、维消减、数据压缩、数据块消减、离散化和概念层次生成等方法实现。
(4) 数据变换: 数据变换是根据需要将数据压缩到较小的区间中, 也就是对数据进行规格化处理, 将数据压缩到特定的范围之内。
以上几种数据预处理方法, 相互之间不仅关联而且是独立的, 各个预处理方法的实施并没有先后顺序的严格制约, 并且相互贯通, 例如消除数据冗余的过程既可以看做是数据清洗过程的一项工作, 也可以认为是数据归约工作中的一种方法。
特征选择能够从数据集中选取具有代表性的特征子集,删除不相关或冗余特征。因此,在软件缺陷预测中采用特征选择,不仅能够提高预测模型的训练速度,更重要的是能够提高其预测性能。根据特征选择的输出类型不同,可将其分为特征排序和特征子集选择两类。
1、常用的预测模型:决策树、朴素贝叶斯分类器和支持向量机(SVM)等。
2、评价预测结果,常用的性能评价指标:F-Measure、AUC
实验内容:
预处理
实验题目
对数据集D(CM1软件缺陷预测中常用的数据集) 进行如下特征选择处理,使用熟悉的程序设计语言进行编程(要求程序具有通用性):
(本实验中数据集D指CM1数据集,数据细节参见CM1.arff文件)
CM1数据说明:LOC_BLANK、 LOC_BLANK、 BRANCH_COUNT、CALL_PAIRS 、LOC_CODE_AND_COMMENT、LOC_COMMENTS、CONDITION_COUNT 、CYCLOMATIC_COMPLEXITY、CYCLOMATIC_DENSITY、DECISION_COUNT、DECISION_DENSITY 、DESIGN_COMPLEXITY、DESIGN_DENSITY、EDGE_COUNT、ESSENTIAL_COMPLEXITY、ESSENTIAL_DENSITY、LOC_EXECUTABLE、PARAMETER_COUNT、HALSTEAD_CONTENT、HALSTEAD_DIFFICULTY、HALSTEAD_EFFORT、HALSTEAD_ERROR_EST、HALSTEAD_LENGTH、 HALSTEAD_LEVEL、 HALSTEAD_PROG_TIME、 HALSTEAD_VOLUME、 MAINTENANCE_SEVERITY、 MODIFIED_CONDITION_COUNT、 MULTIPLE_CONDITION_COUNT、 NODE_COUNT、 NORMALIZED_CYLOMATIC_COMPLEXITY、 NUM_OPERANDS、 NUM_OPERATORS 、 NUM_UNIQUE_OPERANDS、 NUM_UNIQUE_OPERATORS、 NUMBER_OF_LINES、 PERCENT_COMMENTS 、 LOC_TOTAL 为样本特征;
Defective {Y,N}表示样本的类别,Y表示有缺陷样本,N表示无缺陷样本。
方法说明:
在软件缺陷预测中,一个数据集是由大量样本组成的,每个样本又包括多个特征来描述样本的相关特性。对于一个数据集D={x1,x2,…,xn},该数据集包括n个样本,每个样本含有d个特征,分别表示为F={ f1,f2,…,fd }。此时,每个样本可以看作是一个 d 维向量。因此,数据集 D中任意两个样本xi与xj之间的欧氏距离为: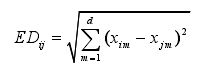 上式将数据集中不同特征的量纲(即单位)看作是相同的,故无法准确度量不同量纲的特征间的距离。因此,需要对数据集进行标准化处理,消除不同特征间的量纲约束,从而准确度量不同特征间的距离。标准化过程如下:
上式将数据集中不同特征的量纲(即单位)看作是相同的,故无法准确度量不同量纲的特征间的距离。因此,需要对数据集进行标准化处理,消除不同特征间的量纲约束,从而准确度量不同特征间的距离。标准化过程如下: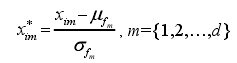
 经过标准化处理后,两个样本间的标准化欧氏距离如式所示:
经过标准化处理后,两个样本间的标准化欧氏距离如式所示: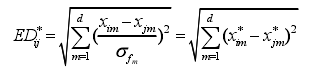
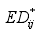 值越小,说明两个样本越相似。对于两个不同类别的样本来说,若它们之间的相似性较高,则认为这两个样本中特征差值较大的那些特征与类别的相关程度更高。
值越小,说明两个样本越相似。对于两个不同类别的样本来说,若它们之间的相似性较高,则认为这两个样本中特征差值较大的那些特征与类别的相关程度更高。
首先,统计数据集 D (即CM1)中的有缺陷样本数n 1 和无缺陷样本数n 2 ,则该数据集的不平衡率表示为⌊n2 /n1 ⌋。同时,对数据集 D 进行标准化处理,计算每个有缺陷样本与所有无缺陷样本间的标准化欧氏距离。其次,根据得到的标准化欧氏距离,选取与每个有缺陷样本最近邻的 k 个无缺陷样本,这里的k 即为数据集的不平衡率。然后,分别计算它们的特征差值,依据特征差值更新特征权重。最后,按照特征权重降序排列产生一个特征排序列表,排序越靠前,说明该特征与类别的相关程度越高。
举例说明算法过程:
假设数据集 D 中包含 9 个样本,每个样本包括 3 个特征。假设x1 ~ x 3为有缺陷样本
(共 3 个),x4~ x9 为无缺陷样本(共 6 个),因此近邻数 k = 2。按照算法步骤计算标准化欧式距离、特征差值和特征权重,然后更新特征权重并生成特征排序列表{ f3, f2, f1},其中f3 与类别特征的相关度最高,而f 1 与类别的相关度最低。

在特征排序列表的基础上,按照顺序依次进行特征子集选择。例如,得到的特征排序列表为
,d表示特征个数,排序越靠前,说明该特征与类别的相关程度越高。由此,根据特征排序顺序可以得到d个特征子集,分别为,最后评价所有特征子集的分类性能。
分类和预测
选取12个 NASA 数据集作为实验对象,采用不同的分类方法分别对这12个数据集进行软件缺陷预测分析。(数据见data文件夹)
- 预处理:
选出与类别相关度较高的特征子集:采用上机1 中数据预处理方法,获得特征排序列表。在特征排序列表的基础上,按照顺序依次进行特征子集选择。例如,得到的特征排序列表为,d表示特征个数,排序越靠前,说明该特征与类别的相关程度越高。由此,根据特征排序顺序可以得到d个特征子集,分别为,最后评价所有特征子集的分类性能,并据此选取与类别相关度较高的特征子集,并进一步构建分类预测模型。 - 预测模型方法
分类器构建预测模型:(1)决策树 (2)Naive Bayes (NB) (3)SVM
可在以上分类器中选择2个或者3个分类器构建预测模型。 - 性能评价
选取F-Measure或AUC作为性能评价指标;
采用 10 次 10 折交叉验证,保证实验结果的准确性和可靠性。
import numpy as np
from sklearn import preprocessing
from sklearn import tree
from sklearn import svm
from sklearn import naive_bayes
from sklearn.model_selection import RepeatedKFold
from sklearn import metrics
import pandas
import copy, os, sys, arff
from openpyxl import Workbook
def restart_program():
python = sys.executable
os.execl(python, python, * sys.argv)
def getdata(data):
instance = data.shape[0]
attribute = data.shape[1] - 1
Defective = data[:, attribute]
data = np.delete(data, attribute, axis=1)
return data,instance,attribute,Defective
def getDefectiveNum(Defective):
DefectiveNum = copy.deepcopy(Defective)
for i,v in enumerate(DefectiveNum):
if v == 'Y':
DefectiveNum[i] = 0
else:
DefectiveNum[i] = 1
DefectiveNum = [float(i) for i in DefectiveNum]
return DefectiveNum
def DT(train_Data,train_Defective,test_Data,test_Defective):
clf = tree.DecisionTreeClassifier()
clf.fit(train_Data, train_Defective)
predict_prob = clf.predict_proba(test_Data)[:, 1]
DT_auc = metrics.roc_auc_score(getDefectiveNum(test_Defective), predict_prob)
return DT_auc
def SVC(train_Data,train_Defective,test_Data,test_Defective):
clf = svm.SVC(C=4)#(gamma='rbf'
train_Defective = getDefectiveNum(train_Defective)
clf.fit(train_Data, train_Defective)
pred = clf.predict(test_Data)
#pred = getDefectiveNum(pred)
test_Defective = getDefectiveNum(test_Defective)
SVC_auc = metrics.roc_auc_score(test_Defective, pred)
return SVC_auc
"""svc = svm.SVC()
svc.fit(train_Data, train_Defective)
predict_prob = svc.predict(test_Data)
TP = 0 # 正确预测为正例数
FP = 0 # 错误预测为正例数
FN = 0 # 错误预测为负例数
for index, predict in enumerate(predict_prob):
if predict == 'Y' and test_Defective[index] == 'Y':
TP += 1
if predict == 'Y' and test_Defective[index] == 'N':
FP += 1
if predict == 'N' and test_Defective[index] == 'Y':
FN += 1
if TP + FP == 0 or TP + FN == 0:
SVC_F1 = 0
else:
P = TP / (TP + FP)
R = TP / (TP + FN)
if P + R == 0:
SVC_F1 = 0
else:
SVC_F1 = 2 * P * R / (P + R)
return SVC_F1"""
def func(myset):
test_auc = 0
test_F1 = 0
try:
kf = RepeatedKFold(n_splits=10, n_repeats=10)
for train_index, test_index in kf.split(myset):
train = []
test = []
for train_num in train_index:
train.append(originData[train_num])
for test_num in test_index:
test.append(originData[test_num])
train = np.array(train)
test = np.array(test)
train_Data, train_Instance, train_Attribute, train_Defective = getdata(train)
test_Data, test_Instance, test_Attribure, test_Defective = getdata(test)
test_auc = DT(train_Data, train_Defective, test_Data, test_Defective)
test_F1 = SVC(train_Data, train_Defective, test_Data, test_Defective)
except:
func(myset)
return test_auc,test_F1
'''新建数据表'''
wb = Workbook()
ws = wb.active
fileList = ['CM1', 'KC1', 'KC3', 'MC2', 'MW1', 'PC1', 'PC2', 'PC3', 'PC4', 'JM1', 'MC1']#, 'PC5']
'''JM1 MC1 PC5'''
for filename in fileList:
ws.append([filename])
'''导入数据'''
dataset = arff.load(open('Data/'+filename+'.arff'))
originData = np.array(dataset['data'])
data, instance, attribute, Defective = getdata(originData)
DefectiveNum = getDefectiveNum(Defective)
'''标准化'''
data = data.astype('float64')
scaled = preprocessing.scale(data)
#print(scaled)
'''计算k'''
k = np.sum(Defective == "N")/np.sum(Defective == "Y")
k = int(k)
#print(k)
'''标准化距离'''
ed = np.zeros((instance, instance))
alldata = instance*instance
for i in range(0, instance):
for j in range(0, instance):
caleddata = i*instance + j
percent = int(caleddata/alldata*100)
#ed[i][j] = np.sqrt(np.sum(np.square(scaled[i, :] - scaled[j, :])))
print("\r计算"+filename+"特征排序列表:"+"."*percent+str(percent)+"%",end=' ')
ed[i][j] = np.linalg.norm(scaled[i,:] - scaled[j,:])
print()
#print(ed)
'''临近样本'''
rank = []
for i in range(0, instance):
rank.append(pandas.Series(ed[i, :]).rank(method='min').tolist())
#print(rank)
nearest = []
rankcpy = copy.deepcopy(rank)
def getminposition(mylist):
minnum = min(mylist)
position = mylist.index(minnum)
return position
def delete(list1,list2):
deltalist = []
for i,v in enumerate(list1):
deltalist.append(abs(list1[i]-list2[i]))
return deltalist
def add(list1,list2):
sumlist = []
for i,v in enumerate(list1):
sumlist.append(abs(list1[i]+list2[i]))
return sumlist
for index,i in enumerate(rankcpy):
n = []
num = 0
while 1:
position = getminposition(i)
if Defective[position] == 'Y' or position == index:
i[position] = max(i)
else:
n.append(position)
i[position] = max(i)
num += 1
if num == k:
break
nearest.append(n)
#print(nearest)
'''特征差值'''
delta = []
for i,v in enumerate(data):
d = []
for j,w in enumerate(nearest[i]):
d.append(delete(data[i], data[w]))
delta.append(d)
#print(delta)
'''特征权重'''
W = np.zeros(attribute)
#print(W)
for i,v in enumerate(delta):
if Defective[i] == 'Y':
for j in v:
W = add(W,pandas.Series(j).rank(method='min').tolist())
#print(W)
'''特征排序列表'''
WRank = pandas.Series(W).rank(method='min').tolist()
fRank = []
WRankcpy = copy.deepcopy(WRank)
#print(WRankcpy)
flag = 0
while 1:
for i, v in enumerate(WRankcpy):
if v == max(WRankcpy):
fRank.append(i+1)
WRankcpy[i] = -1
flag += 1
if flag == attribute:
break
if flag == attribute:
break
print(filename+"特征排序列表")
print(fRank)
def getSet(data,rank,num):
subset = []
for i in range(instance):
subset.append([])
for j in range(num):
for i,v in enumerate(data[:,rank[j]-1]):
subset[i].append(v)
for i,v in enumerate(Defective):
subset[i].append(v)
return subset
AUCList = []
F1List = []
for i in range(1,attribute+1):
myset = getSet(data,fRank,i)
auc,F1 = func(myset)
AUCList.append(auc)
F1List.append(F1)
ws.append(['决策树-AUC'])
ws.append(AUCList)
ws.append(['最大值位置'])
AUCindex = AUCList.index(max(AUCList))+1
ws.append([AUCindex])
ws.append(["对应序列"])
ws.append(fRank[0:AUCindex])
ws.append(['SVM-AUC'])
ws.append(F1List)
ws.append(['最大值位置'])
Findex = F1List.index(max(F1List))+1
ws.append([Findex])
ws.append(["对应序列"])
ws.append(fRank[0:Findex])
print(filename+'finish')
#wb.save('Data/test.xlsx')
测试数据集
@attribute LOC_BLANK numeric
@attribute BRANCH_COUNT numeric
@attribute CALL_PAIRS numeric
@attribute Defective {Y,N}
@data
6,9,2,N
15,7,3,Y
27,9,1,Y
7,3,2,N
51,25,13,N
3,5,2,N
13,9,5,N















 3811
3811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









