








文章链接:https://arxiv.org/pdf/2407.06187
github链接:https://research.nvidia.com/labs/dir/jedi
本文提出了一种无需微调的文本生成图像方法,采用了新颖的联合图像扩散模型。
提出了一种简单且可扩展的数据合成流程,用于生成共享同一主题的多图像个性化数据集。
设计了新颖的架构和采样技术,如耦合自注意力和图像引导,以实现高保真度的个性化生成。
个性化文本生成图像模型使用户能够在不同场景中创建展示其个人物品的图像,并在各个领域找到应用。为了实现个性化功能,现有方法依赖于在用户的自定义数据集上微调文本生成图像的基础模型,这对于普通用户来说可能并不容易,而且资源密集且耗时。尽管已有尝试开发无需微调的方法,但其生成质量远低于微调方法。
本文提出了一种名为Joint-Image Diffusion (JeDi) 的有效技术,用于学习无需微调的个性化模型。关键思想是学习共享共同主题的多个相关文本图像对的联合分布。为了便于学习,提出了一种可扩展的合成数据集生成技术。模型训练完成后,本文的模型在测试时通过在采样过程中简单使用参考图像作为输入,能够实现快速且简便的个性化。JeDi不需要任何昂贵的优化过程或额外的模块,并且可以保留任意数量参考图像所表示的身份。实验结果表明,本文的模型在定量和定性方面都实现了最先进的生成质量,显著优于之前基于微调和无需微调的个性化基准。

方法
数据集创建
训练模型以生成多张同一主题图像的联合分布,需要一个数据集,每个样本都是共享同一主题的图像集。虽然存在一些同一主题的数据集,例如 CustomConcept101和 DreamBooth,但它们规模较小,缺乏扩散模型训练所需的足够变化。因此,研究者们使用大型语言模型和单图像扩散模型创建了一个包含同一主题的图像-文本对的多样化大规模数据集,称为合成同一主题(S3)数据集。
下图3展示了数据生成过程。首先从一个常见对象列表开始,并提示 ChatGPT 为列表中的每个对象生成文本描述。然后,使用预训练的 SDXL模型,通过在每个生成的文本提示中附加“相同的照片”一词,生成一个相同主题的照片拼贴数据集。观察到,通过这种方式提示 SDXL 模型,它可以生成具有不同姿势的相同主题的照片拼贴。然而,生成的图像通常包含简单背景中的物体特写。为了增加数据的多样性,采用了一个后处理步骤,对生成的对象进行背景增强。
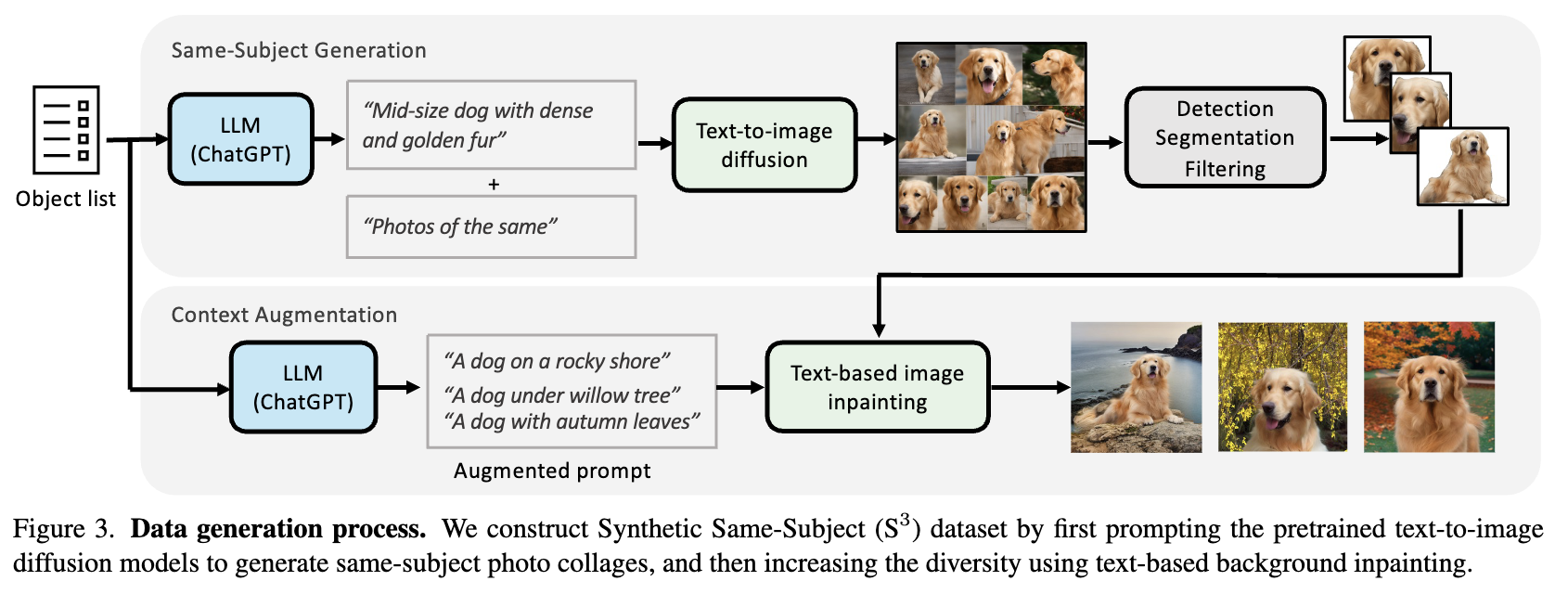
对于生成的照片拼贴,首先运行目标检测和分割
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









